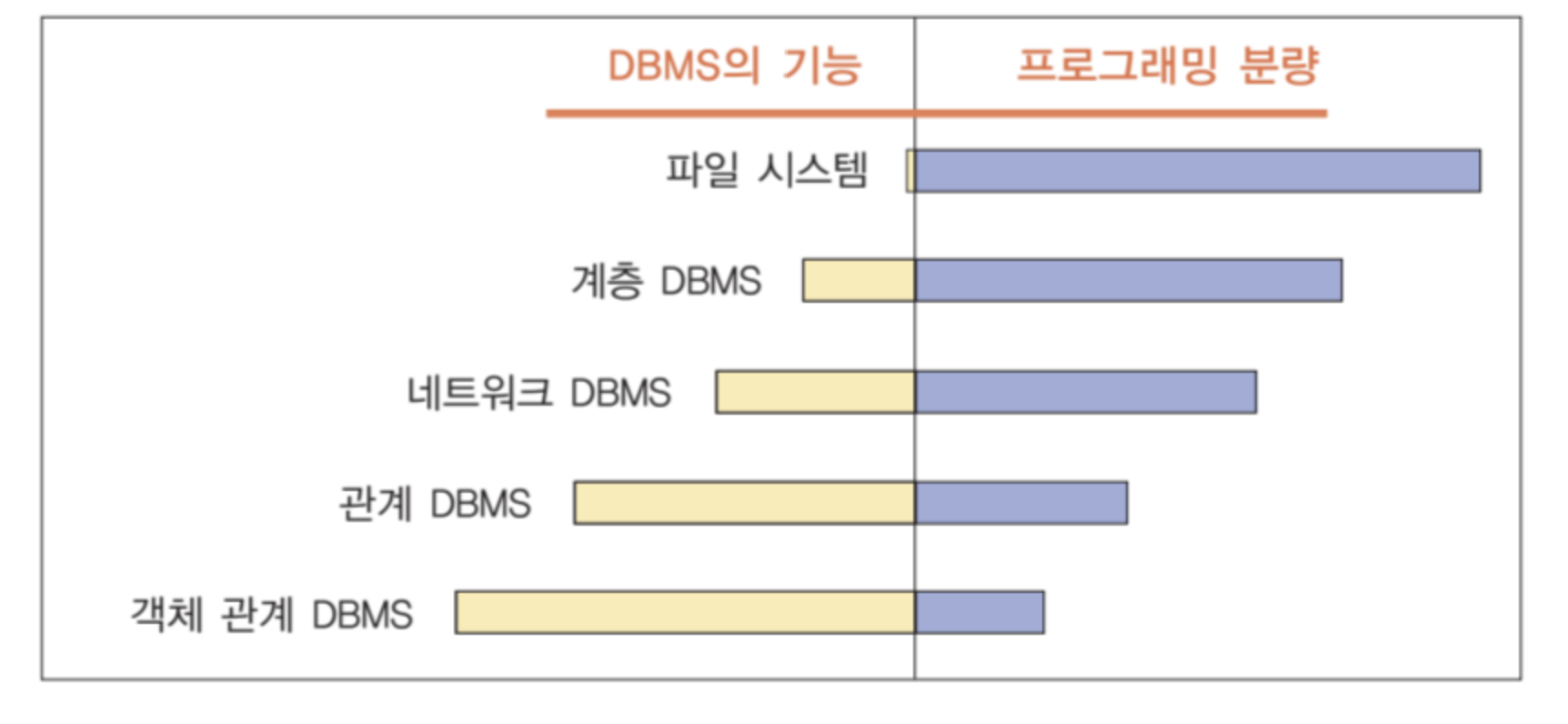
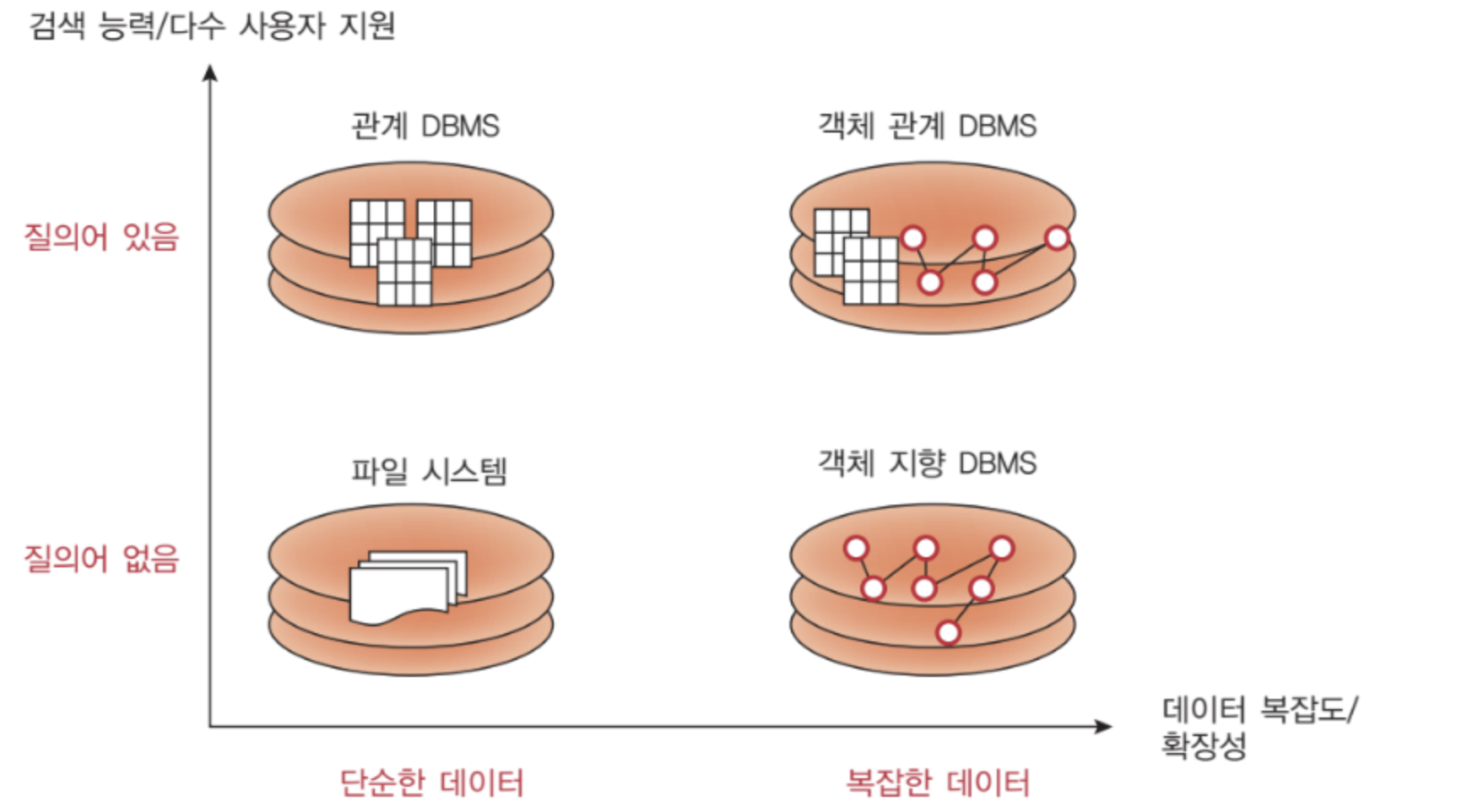
데이터 모델의 분류
-
고수준 또는 개념적 데이터 모델 (conceptual data model)
: 사람이 인식하는 것과 유사하게 데이터베이스의 전체적인 논리적 구조를 명시한다.
ex) 엔티티-관계 데이터 모델과 객체 지향 데이텀 모델 -
표현 데이터 모델 (representation data model)
: 최종 사용자가 이해하는 개념이면서 컴퓨터 내에서 데이터가 조직되는 방식과 멀리 떨어져 있지 않음.
ex) 계층 데이터 모델, 네트워크 데이터 모델, 관계 데이터 모델, 객체 관계 데이터 모델 -
저수준 또는 물리적인 데이터 모델 (physical data model)
: 데이터베이스에 데이터가 어떻게 저장되는가를 기술
ex) B-트리 인덱스, 해싱 등
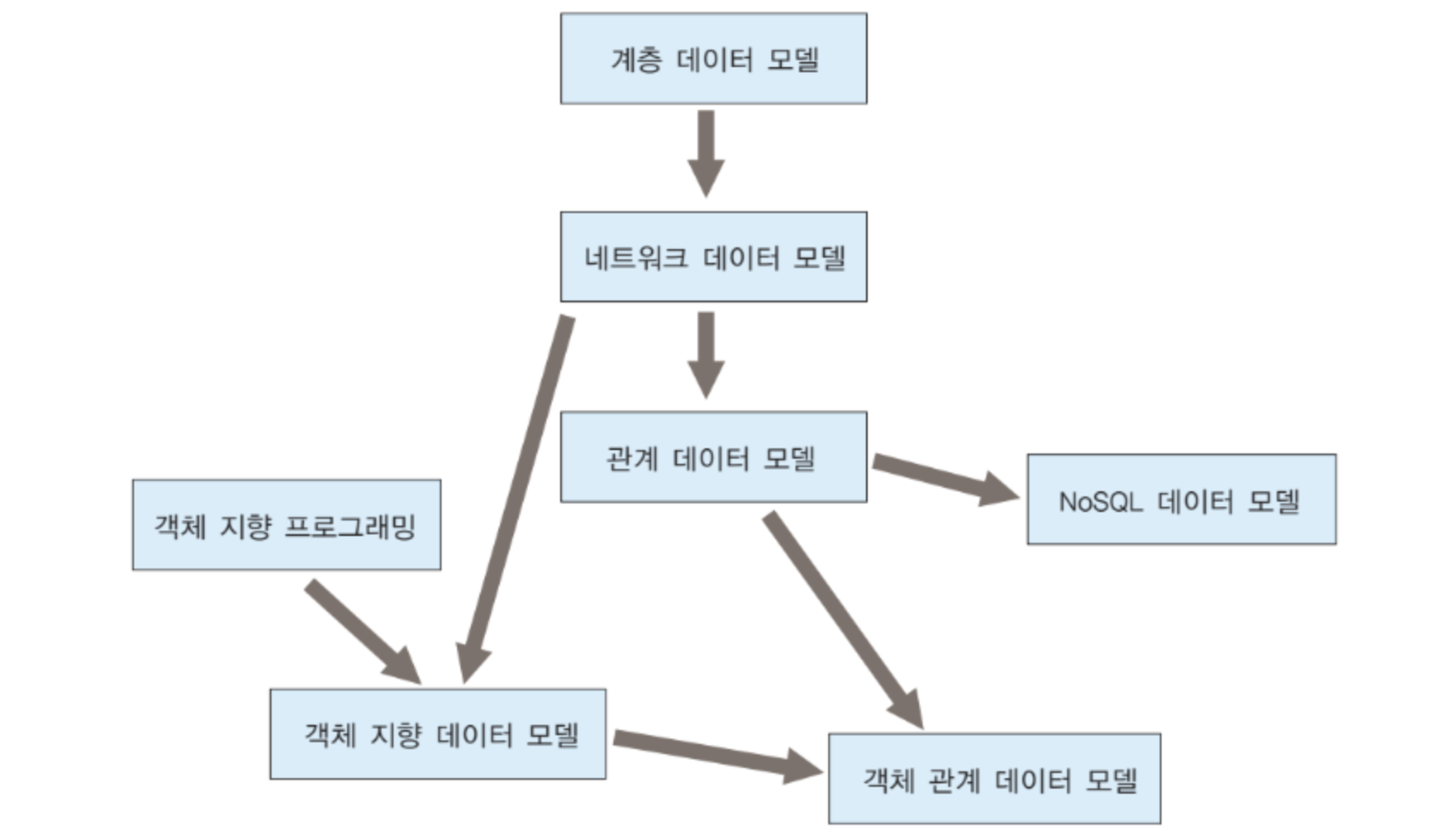
계층 데이터 모델
-
1960년대 후반에 최초의 계층 DBMS가 등장 (IBM의 IMS)
-
트리 구조를 기반으로 함
-
장점
: 어떤 유형의 응용에 대해서는 빠른 속도와 높은 효율성을 제공 -
단점
: 어떻게 데이터를 접근하는가를 미리 응용 프로그램에 정의해야 한다.
데이터베이스가 생성될 때 각각의 관계를 명시적으로 정의해야 한다.
레코드들이 링크로 연결되어 있으므로 레코드 구조를 변경하기 어렵다.
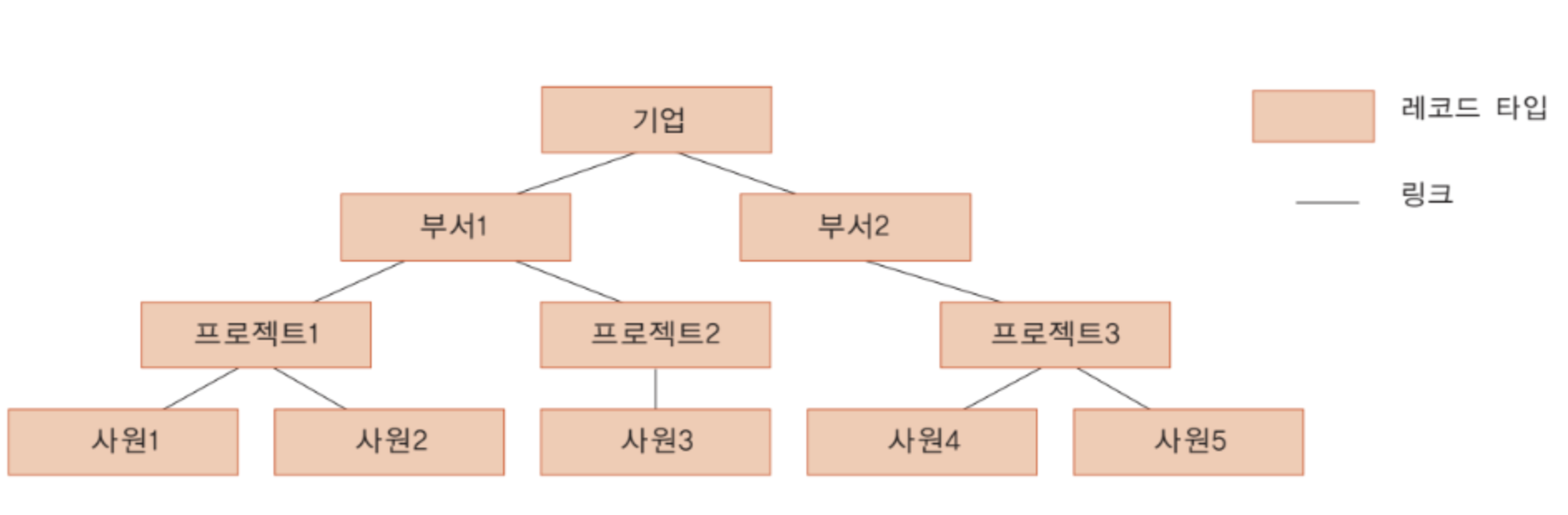
위의 그림에서 한 명의 사원이 여러 프로젝트에 참여할 경우 데이터의 중복이 발생하게 된다.
네트워크 데이터 모델
-
1960년대 초에 C.Bachman이 Honeywell에서 최초의 네트워크 DBMS인 IDS를 개발
-
계층 데이터 모델의 한계를 극복하고자 나온 것이 네트워크 데이터 모델
-
레코드들이 노드로, 레코드들 사이의 관계가 간선으로 표현되는 그래프를 기반으로 함.
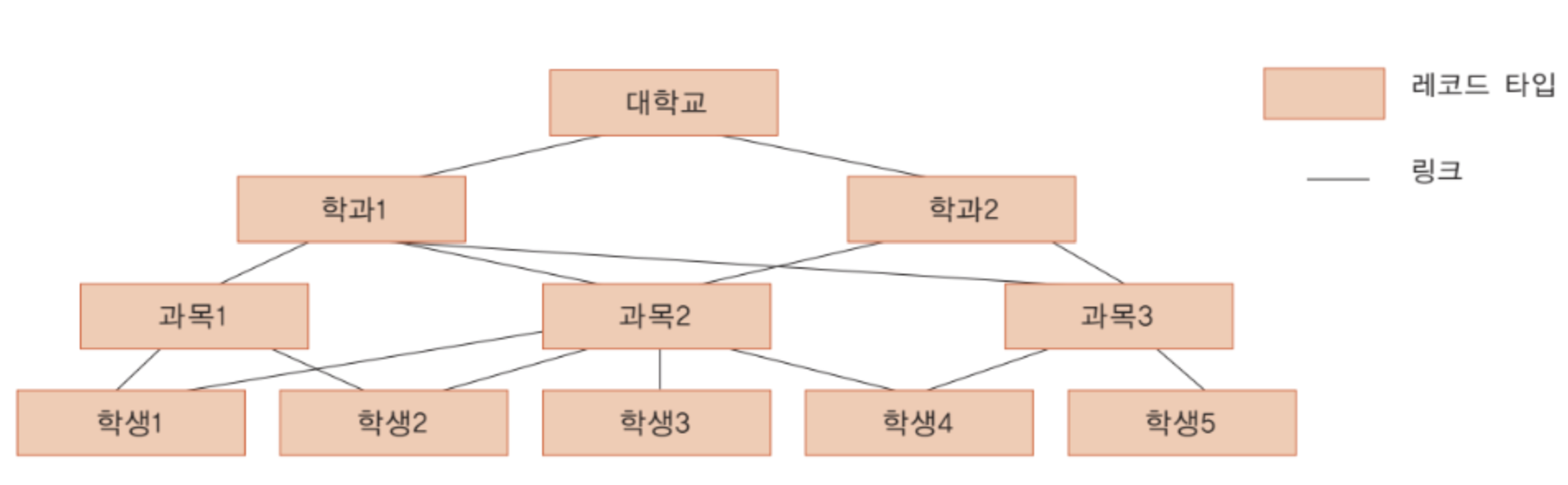
데이터의 중복을 방지할 수 있다.
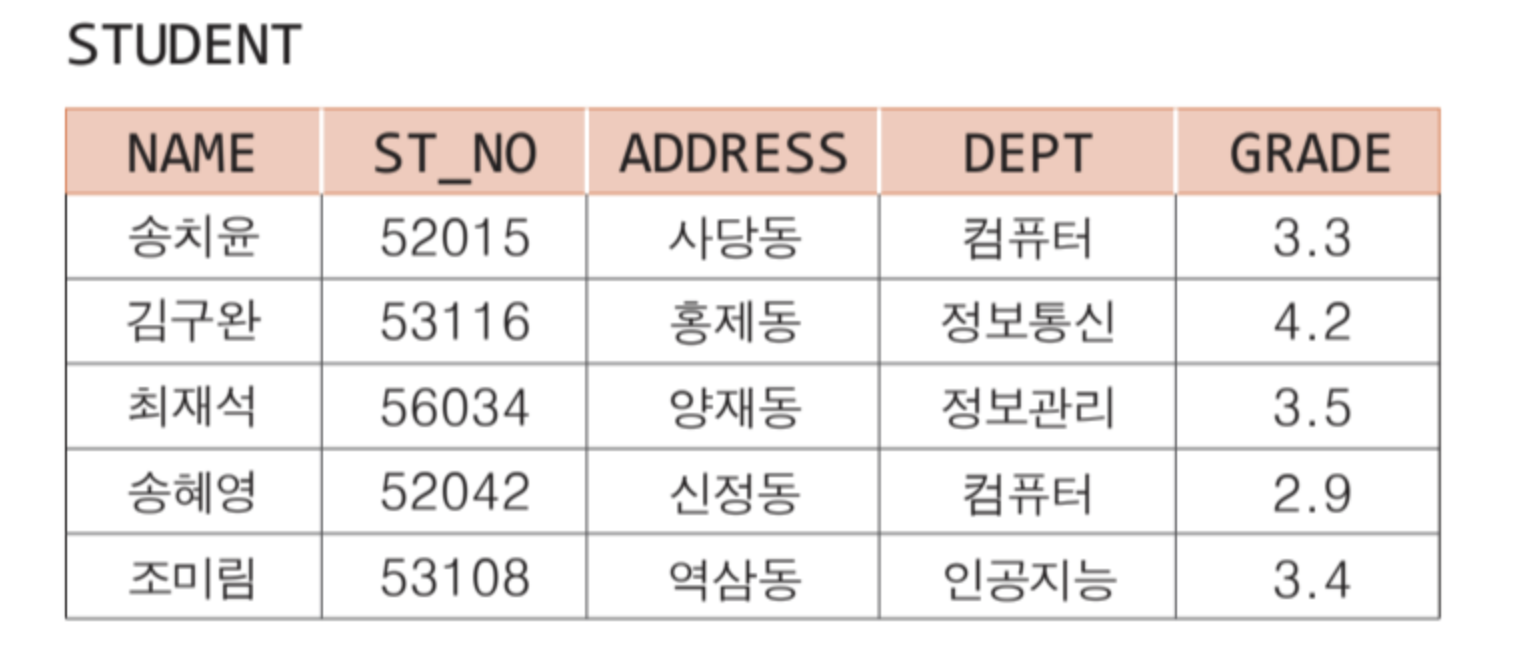
관계 데이터 모델
-
1970년에 E.F.Codd가 IBM 연구소에서 관계 데이터 모델을 제안
-
데이터를 테이블 형태로 명시하여 저장
-
장점
: 모델이 간단하여 이해하기 쉽다. 사용자는 자신이 원하는 것(what)만 명시하고, 데이터가 어디에 있는지, 어떻게 접근해야 하는지(how)는 관계 DBMS가 결정한다.
객체 지향 데이터 모델
-
1980년대 후반 들어 새로운 데이터 모델인 객체 지향 데이터 모델이 등장
-
객체 지향 프로그래밍 패러다임을 기반으로 하는 데이터 모델
-
장점
: 데이터와 프로그램을 그룹화하고, 복잡한 객체들을 이해하기 쉬우며, 유지와 변경이 용이하다.
객체 관계 데이터 모델
- 1990년대 후반에 관계 DBMS에 객체 지향 개념을 통합한 객체 관계 데이터 모델이 제안됨.
NoSQL 데이터베이스
-
2000년대 들어서 메타(페이스북), 엑스(트위터)와 같은 소셜 미디어와 웹 데이터(구글)가 폭발적으로 증가하면서 반구조적/비구조적인 빅데이터를 다룰 필요성이 크게 대두되었다.
-
Not only SQL