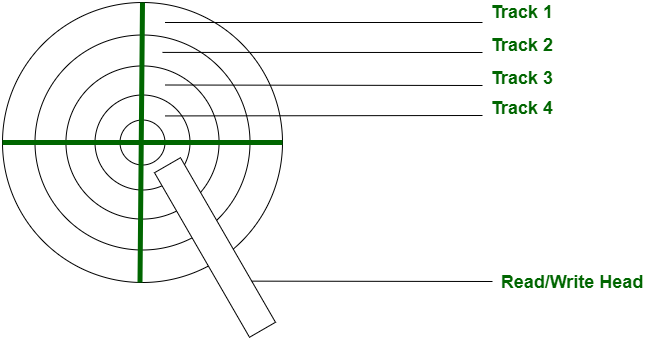
HDD는 프로세스에서 원하는 섹터를 읽기 위해 disk arm이 물리적으로 움직이게 된다. 따라서 섹터를 읽는 순서가 HDD의 성능에도 영향을 미치게 된다.
따라서 OS에서는 HDD에 대한 데이터 읽기 / 쓰기 요청이 오면 이들을 리스트에 저장한 다음, 적절한 알고리즘을 통해 처리 순서를 결정한다.
지금부터 프로세스가 HDD의 데이터를 요청할 때, OS가 어떻게 처리하는지 알아보도록 하자!
FCFS Scheduling
First Come First Serves (FCFS) 알고리즘은 이름 그대로 먼저 온 요청부터 처리하는 것이다. 방법이 간단하고 요청에 대한 처리가 공평할 수는 있지만, 일반적으로 빠른 서비스를 제공하지는 못하는 방법이다.
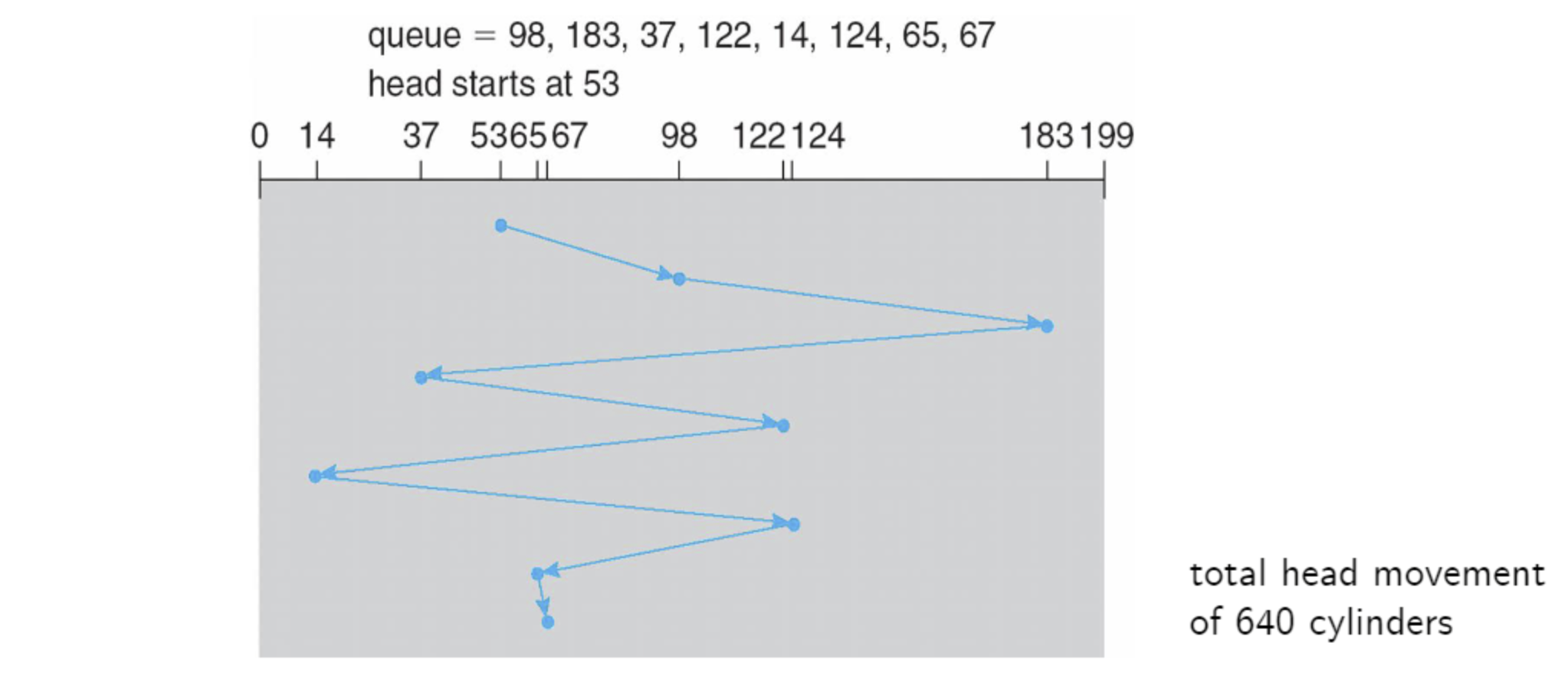
큐에는 프로세스의 요청이 담겨 있으며, 프로세스가 원하는 데이터가 있는 sector를 저장하고 있다. 따라서 sector의 위치를 상관하지 않고 먼저 입력된 요청부터 처리하는 것을 확인할 수 있다. 위의 예제에서는 총 640개의 실린더를 움직였다고 나온다.
SCAN Algorithm
SCAN 알고리즘은 elevator 알고리즘이라고도 불린다. 그 이유는 disk arm이 한쪽 방향으로만 쭉 움직였다가, 다시 그 반대방향으로 움직이기 때문이다. 마치 엘레베이터가 올라갔다 내려가는 거랑 비슷한 원리이다.
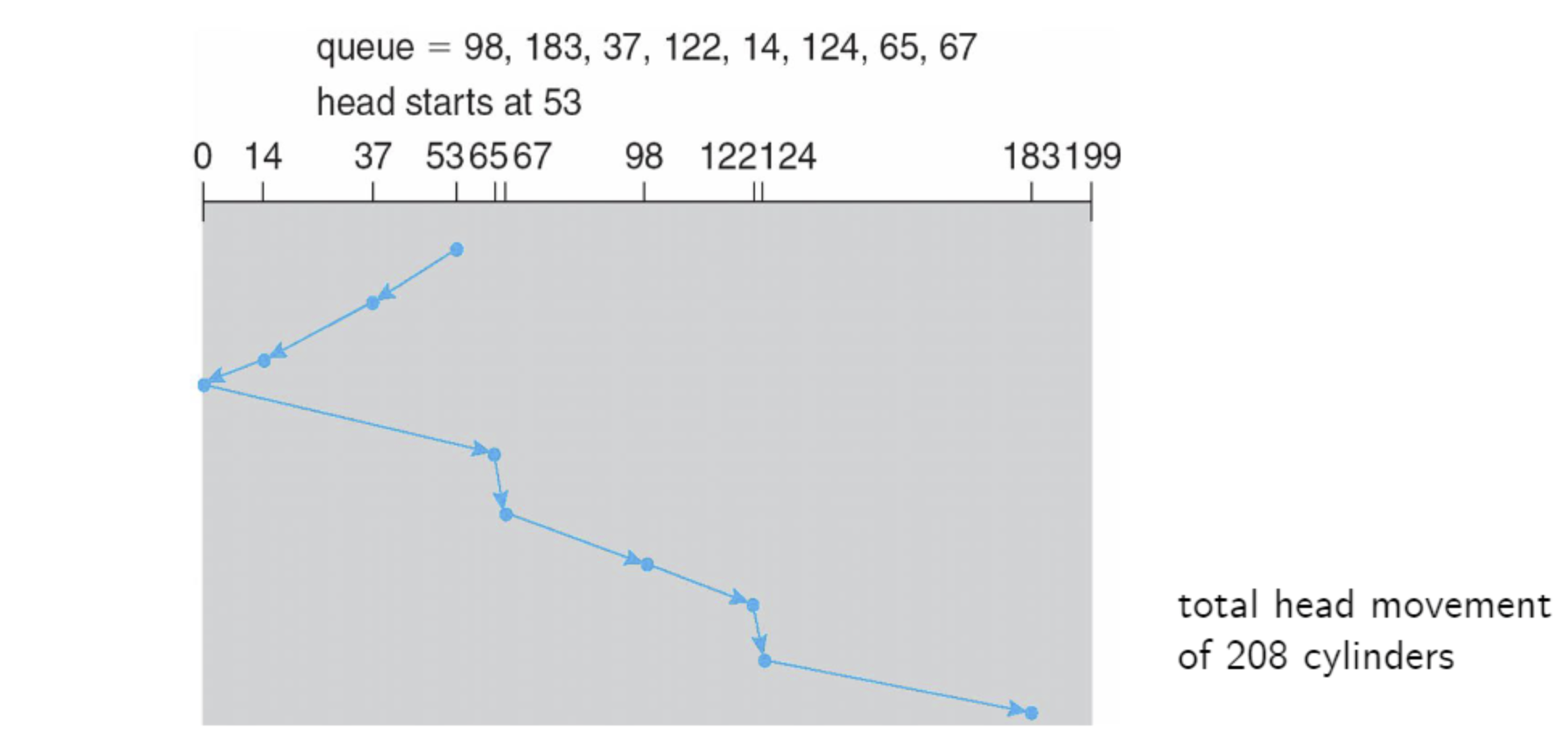
다만, 한가지 주의할점은 반드시 끝 지점을 찍고 반대 방향으로 움직인다는 것이다. 위의 예제에서도 알 수 있지만, disk arm이 내려가는 방향부터 시작해서 0을 찍고 다시 반대 방향으로 움직인다. FCFS 알고리즘에 비해서 더 적은 실린더를 지나갔음을 알 수 있다.
자신이 진행하고 있는 경로의 요청받은 모든 섹터를 거치면서 움직인다.
C - SCAN Algorithm
Circular Scan 알고리즘은 SCAN 알고리즘과는 다르게 한 쪽 방향에서만 데이터를 읽는다는 것이다. SCAN 알고리즘에서는 내려가면서도 데이터를 읽고, 다시 올라가면서도 데이터를 읽었다. 하지만 C-SCAN 알고리즘은 올라가면서 데이터를 읽었다면 다시 0으로 내려갈 때는 데이터를 읽지 않고, 0에서부터 출발하면서 올라가면서 데이터를 읽는다.
굳이 왜? 라는 의문이 들 수 있다.
C - SCAN 에서 굳이 이런 방식으로 데이터를 처리하는 이유는 공정성을 높이기 위해서이다. SCAN 알고리즘에서는 처음 disk arm 이 움직이는 방향에 따라 데이터 처리 속도가 일관적이지 않다는 것이다.
즉, 헤더가 53에서 출발을 할때, 43번 섹터는 disk arm이 내려가는 방향부터 시작한다면 접근 속도가 매우 빠를 것이다. 하지만 만약 올라가는 방향부터 시작한다면? 시작 방향에 따라 데이터 처리 속도가 매우 달라진 다는 것이다. 따라서 C - SCAN 에서는 disk arm의 출발 방향에 따라 데이터가 일관적이지 않은 속도로 처리되는 것을 줄이고자 한쪽 방향에서만 데이터를 처리하는 것이다.
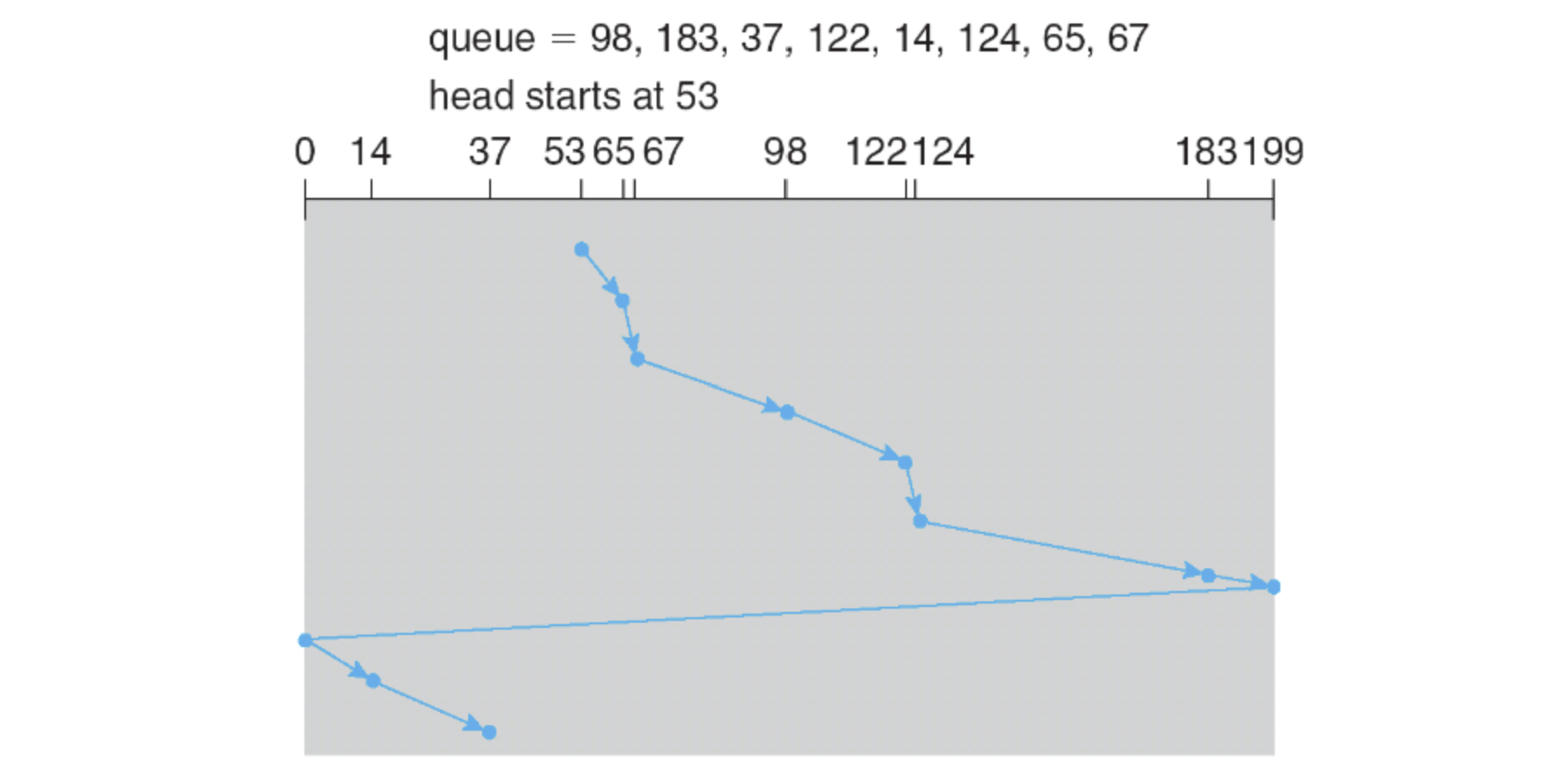
C - SCAN도 마찬가지로 반드시 끝 지점을 찍고 반대방향으로 움직인다.
HDD Scheduling algorithm을 평가하면서 움직인 실린더의 개수를 측정하였다. 이때, SCAN, C - SCAN 알고리즘에서 0과 끝 지점을 찍을 때 움직이는 거리도 포함해서 계산한다.
