
프로그래밍 언어를 기계어로 다시 구현 (변환) 하는데는, 여러가지 방법이 존재한다.
Compilation
컴파일러를 통해 코드를 먼저 기계어로 번역한 뒤 실행하는 방식이다. C, C++, Java 등이 이에 해당한다. 이러한 컴파일 방식의 장점은 빠른 실행이다. 미리 컴파일러를 통해 기계어로 전부 번역해놨기 때문에 실행은 당연히 빠를 수 밖에 없다. 단점은 코드 전체를 한 번에 컴파일 해야 하므로, 번역 과정이 느리다는 것이다.
slow translation, fast execution
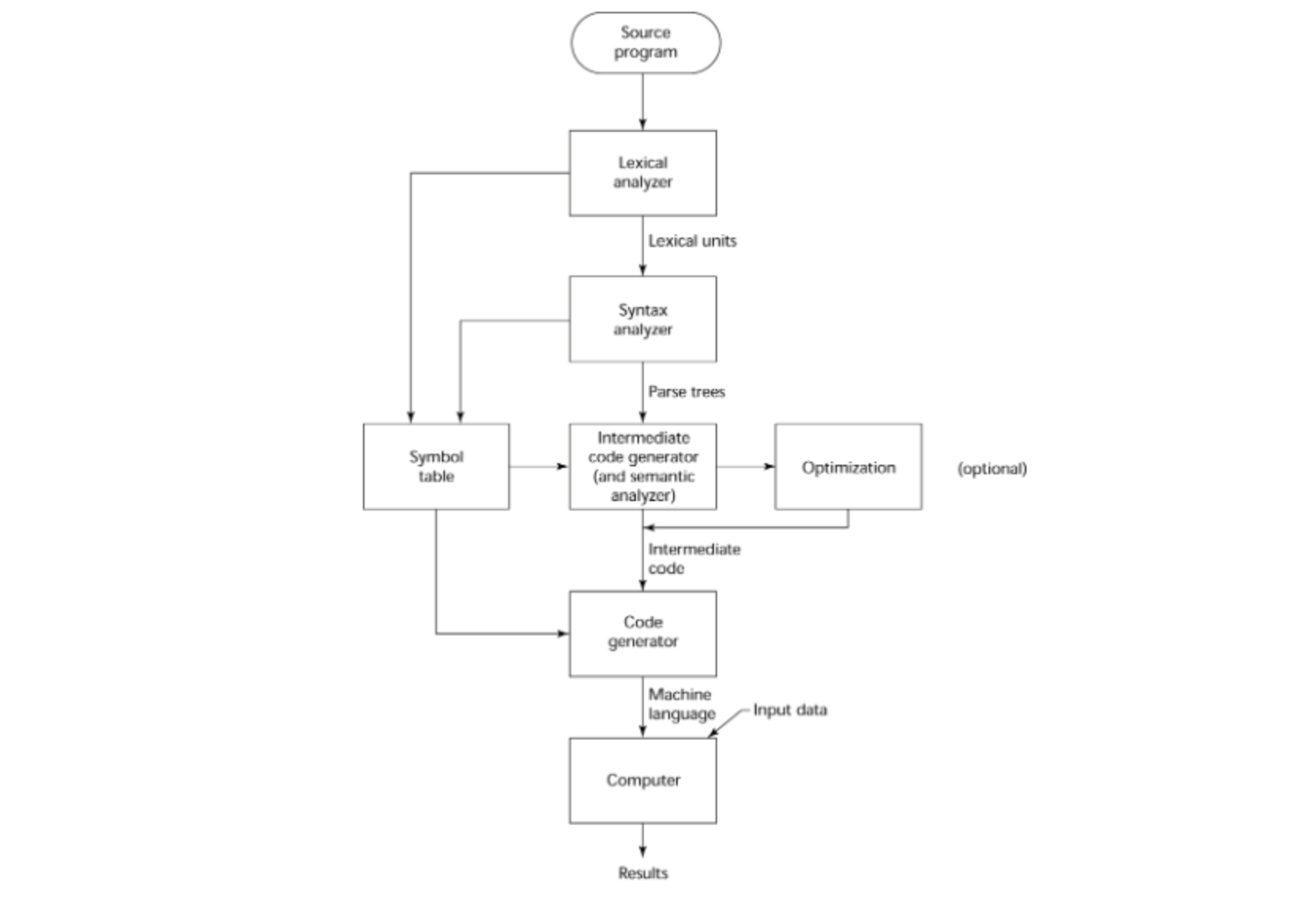
컴파일러를 통한 번역 과정은 다음과 같다.
-
Lexical analyzer (어휘 분석기)
입력된 소스코드를 문법적으로 의미가 있는 단위까지 최대한 쪼갠다.
int, main, identifier -
Syntax analyzer (문법 분석, parser)
작성된 코드의 문법이 맞는지를 판단한다. parse tree라는 것을 생성하여 이를 판단하는데, 이는 다음 장에서 다루도록 하겠다. -
Intermediate code generator (semantic analyzer)
생성된 parse tree를 1차원으로 만들어 준다. 그림에서 보면 알겠지만, 한번에 기계어가 생성되는 것이 아니라, 중간 단계의 코드를 먼저 생성한다. 이러한 중간 코드는 특정한 기계에 종속되지 않으며, 타겟 머신 코드로의 번역을 보다 수월하게 해준다. -
Code generator
이전에 생성된 중간 단계의 코드를 가지고 실제 타겟 머신에 대한 기계어를 생성한다. 여기서 생성된 기계어는 해당 히드웨어에 종속적이게 된다.
Compilation 의 추가적인 용어들
Load module
load module 이란, 실행 가능한 이미지를 의미한다. 사용자의 코드와 시스템 코드 전체를 포함하며, 실행될 준비가 완료된 파일을 의미한다.
Linking and Loading
Linking
유저 코드와 함께 실행에 필요한 외부 라이브러리나 모듈을 모두 묶어서 하나의 실행 파일을 만드는 과정이다. .exe 파일을 만드는 과정이라고 생각하면 편하다.
- Static linking
외부 라이브러리나 모듈을 실행 파일에 포함시켜 독립적인 실행 파일을 만드는 것이다. 실행 파일이 커지지만, 실행 과정에서 별도의 외부 라이브러리를 로드할 필요는 없다. 하지만 동일한 라이브러리가 여러 실행 프로그램에서 동시에 로딩되면 메모리 낭비가 심해질 수 있다. - Dynamic linking
외부 라이브러리를 실행 과정에서 필요할 때 참조하여 실행하는 것이다. 따라서 실행파일에는 외부 라이브러리의 주소만 저장되어 있고 실제로 로드하는 건 실행 과정 중에 일어나게 된다. 불필요한 라이브러리를 로드하지 않아도 되고, 새롭게 release 된 라이브러리들을 이용할 수도 있어서 더 효율적이다.
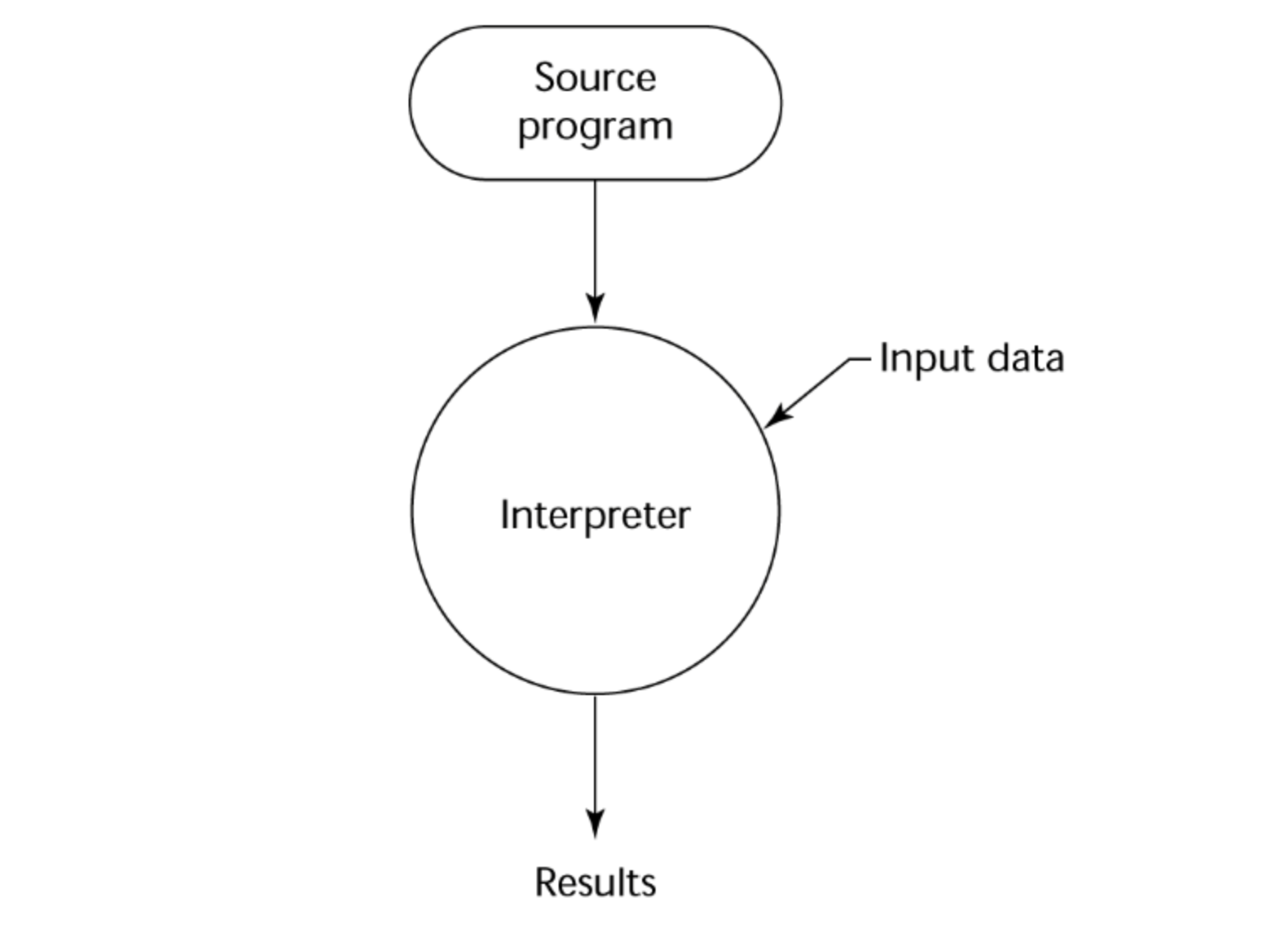
Pure Interpretation
순수하게 인터프리터만 사용하는 언어이다. 미리 컴파일하지 않고 프로그램을 실행할 때, 한 줄 씩 읽어서 기계어로 번역한다. 한 줄 씩 번역하기 때문에, 소스코드나 symbol table이 메모리 상에서 계속 필요해 메모리 효율이 좋지 않다. 또한 for 문과 같은 반복문이 있을 때, 하나의 loop를 끝내고 다시 또 처음으로 돌아가서 번역해야 하기 때문에 실행 시간이 매우 느리다.
Hybrid Iplementation Systems
Compilation 과 pure interpretation을 적절히 섞어서 사용하는 방식이다.
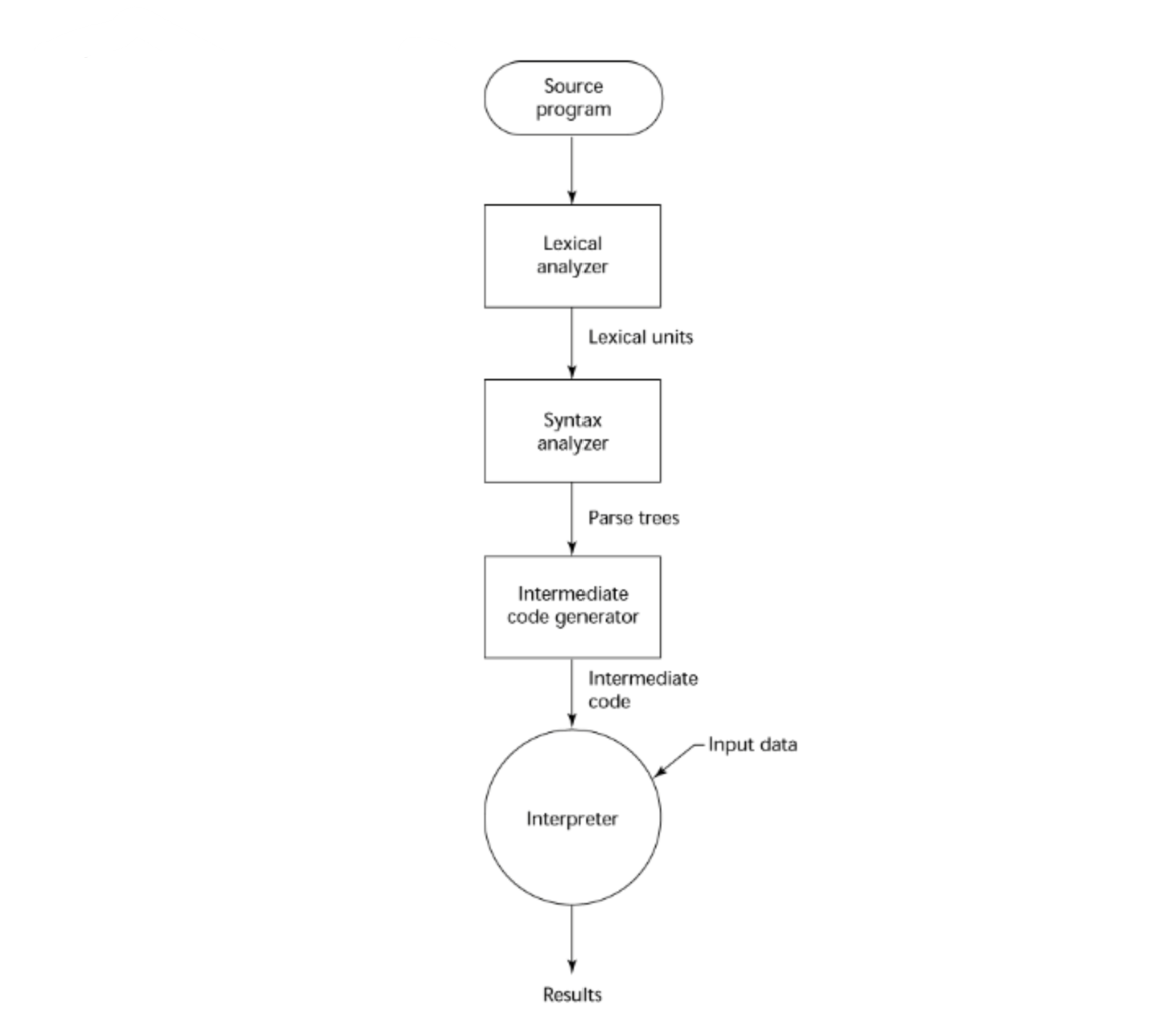
앞선 compilation과 pure interpretation의 흐름도가 절반씩 섞여 있는 것을 확인할 수 있다. 기계어로의 번역이 용이한 중간 단계 언어로 컴파일한 후 이 코드를 interpreter로 번역하는 것이다.
이러한 하이브리드 방식에서 더 진화된 버전이 있다.
Just-in-Time Implementaion Systems
JiT 시스템은 자주 사용되는 코드를 버리지 않고 저장했다가 사용하는 방식이다. 인터프리터가 자주 사용되는 코드가 나올 때마다 번역하는 것은 그리 효율적이지 못하다. 따라서 컴파일러가 중간 언어로 컴파일을 할 때, 자주 사용되는 코드를 캐치하여 미리 컴파일러가 기계어로 번역하는 것이다. 해당 코드는 인터프리터가 번역하지 않고, 컴파일러에 의해 번역된 코드를 가져오게 된다. JVM, .NET, V8 (JavaScript) 등이 이러한 방식을 사용한다.
