관계 데이터 모델 ?
관계 데이터 모델이란 데이터를 2차원 테이블 형태인 릴레이션으로 표현한 것으로, 지금까지 제안된 데이터 모델 중 개념이 가장 단순한 데이터 모델의 하나이다.
IBM 연구소의 E.F.Codd가 1970년대에 관계 데이터 모델을 최초로 제안하였으며, 1980년대 후반부터 여러가지 데이터 모델들이 새로 등장했지만 여전히 가장 널리 사용되는 DBMS이다. 대표적으로 오라클, MySQL 등이 있다.
관계 데이터 모델이 큰 성공을 이룬 요인으로는 여러가지가 있는데, 우선 바탕이 되는 데이터 구조로 간단한 릴레이션 (테이블)을 사용했다는 점이다. 또한 중첩된 복잡한 구조어가 없으며, 한번에 레코드들의 집합을 처리할 수 있다. 또한 고급 언어인 SQL을 제공함으로서, 숙련되지 않은 사용자도 쉽게 이해할 수 있다.
관계 데이터 모델에서는 선언적인 질의어를 통해 데이터에 접근하는데, 사용자는 원하는 데이터 (what) 만 명시하고, 어떻게 접근하는지 (how) 는 명시할 필요가 없다. 또한 응용 프로그램들은 데이터베이스 내의 레코드들의 어떠한 순서와도 무관하게 작성된다.
관계 데이터 모델의 기본적인 용어
-
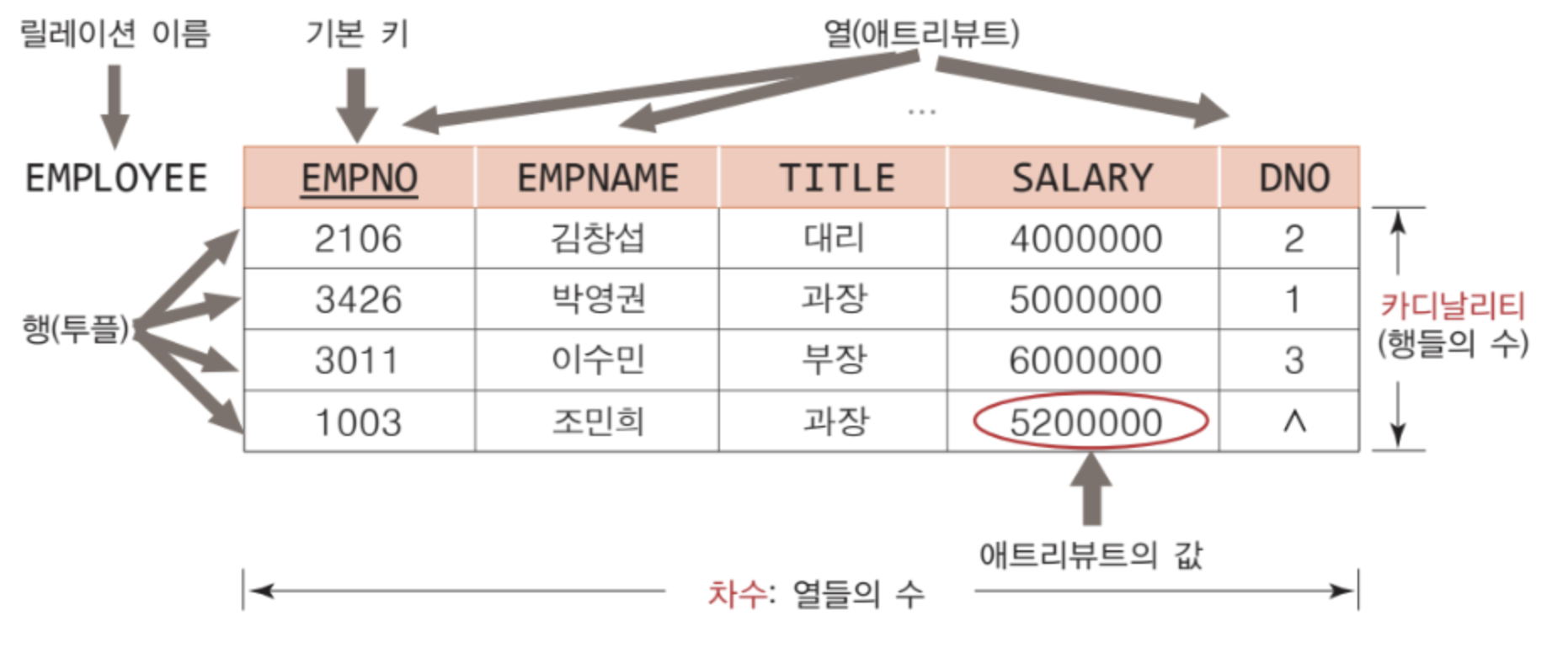
릴레이션 (relation) : 2차원의 테이블
-
레코드 (record) : 릴레이션의 각 행
-
튜플 (tuple) : 레코드를 좀 더 공식적으로 부르는 용어
-
애트리뷰트 (attribute) : 릴레이션에서 이름을 가진 하나의 열 (속성)
릴레이션 개념
- 도메인 (domain)
도메인이란, 한 애트리뷰트 안에 나타날 수 있는 값들의 집합을 의미한다. 프로그래밍 언어의 데이터 타입과 유사하다고 할 수 있다. 예를 들어 학생 정보 릴레이션에서 학번이라는 애트리뷰트에는 정수, 이름 애트리뷰트에는 문자열만 들어갈 수 있음을 의미한다. 각 애트리뷰트의 도메인 값들은 원자값의 형태를 가져야 하며, 동일한 도메인이 여러 애트리뷰트에서 사용될 수 있다.

- 차수 (degree)
한 릴레이션에 들어있는 애트리뷰트들의 수를 의미한다. 유효한 릴레이션의 최소 차수는 1이며, 릴레이션의 차수는 자주 바뀌지 않는다.
-
카디날리티 (cardinality)
릴레이션의 튜플 수를 의미한다. 유효한 릴레이션이 카디날리티 0을 가질 수 있으며, 릴레이션의 카디날리티는 시간이 지나면서 계속 변하게 된다. -
널 (null) ^
알려지지 않음 또는 적용할 수 없음을 나타내기 위해 널을 사용한다. 예를 들어, 사원 릴레이션에 새로운 사원에 관한 튜플을 입력하는데, 신입 사원의 DNO (부서번호)가 결정되지 않았을 수도 있다. 널은 숫자 도메인의 0 이나, 문자열 도메인의 공백과는 다른 개념이다. -
릴레이션 스키마
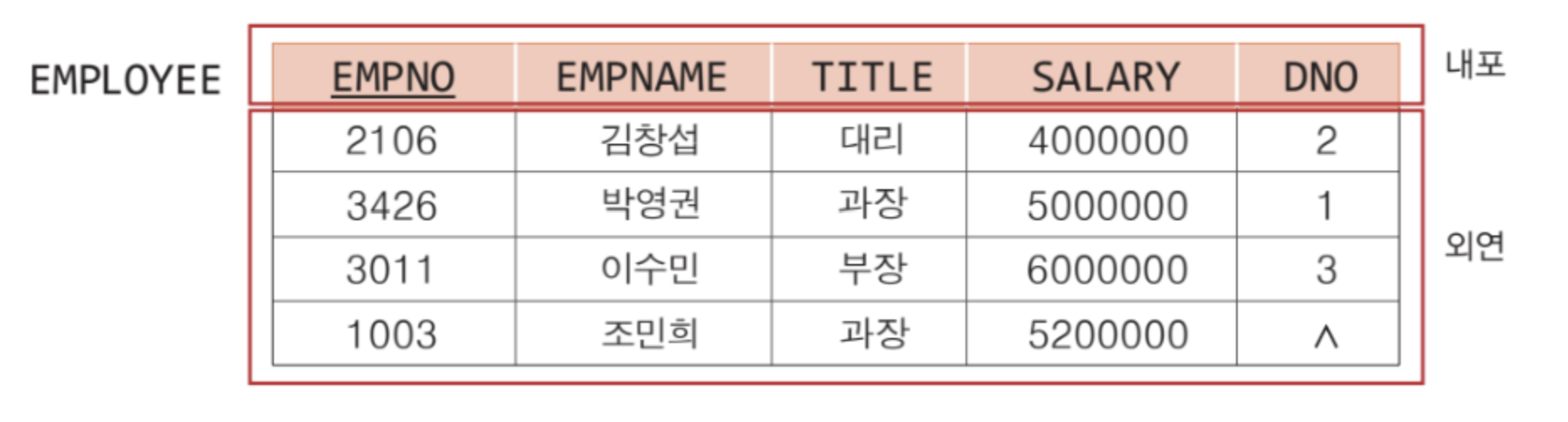
릴레이션 스키마는 릴레이션의 이름과 릴레이션 애트리뷰트들의 목록을 저장하고 있다. 릴레이션을 위한 framework라고 생각할 수 있다. 내포 (intension) 라고 부르기도 한다. -
릴레이션 인스턴스
어느 시점에 릴레이션에 들어있는 튜플들의 집합을 의미한다. 시간의 흐름에 따라 계속 변하며, 일반적으로 릴레이션에는 현재의 인스턴스만 저장된다. 외연 (extension) 이라고도 부른다.
-
관계 데이터베이스 스키마
하나 이상의 릴레이션 스키마들로 이루어짐. -
관계 데이터베이스 인스턴스
하나 이상의 릴레이션 인스턴스 모임으로 구성됨.
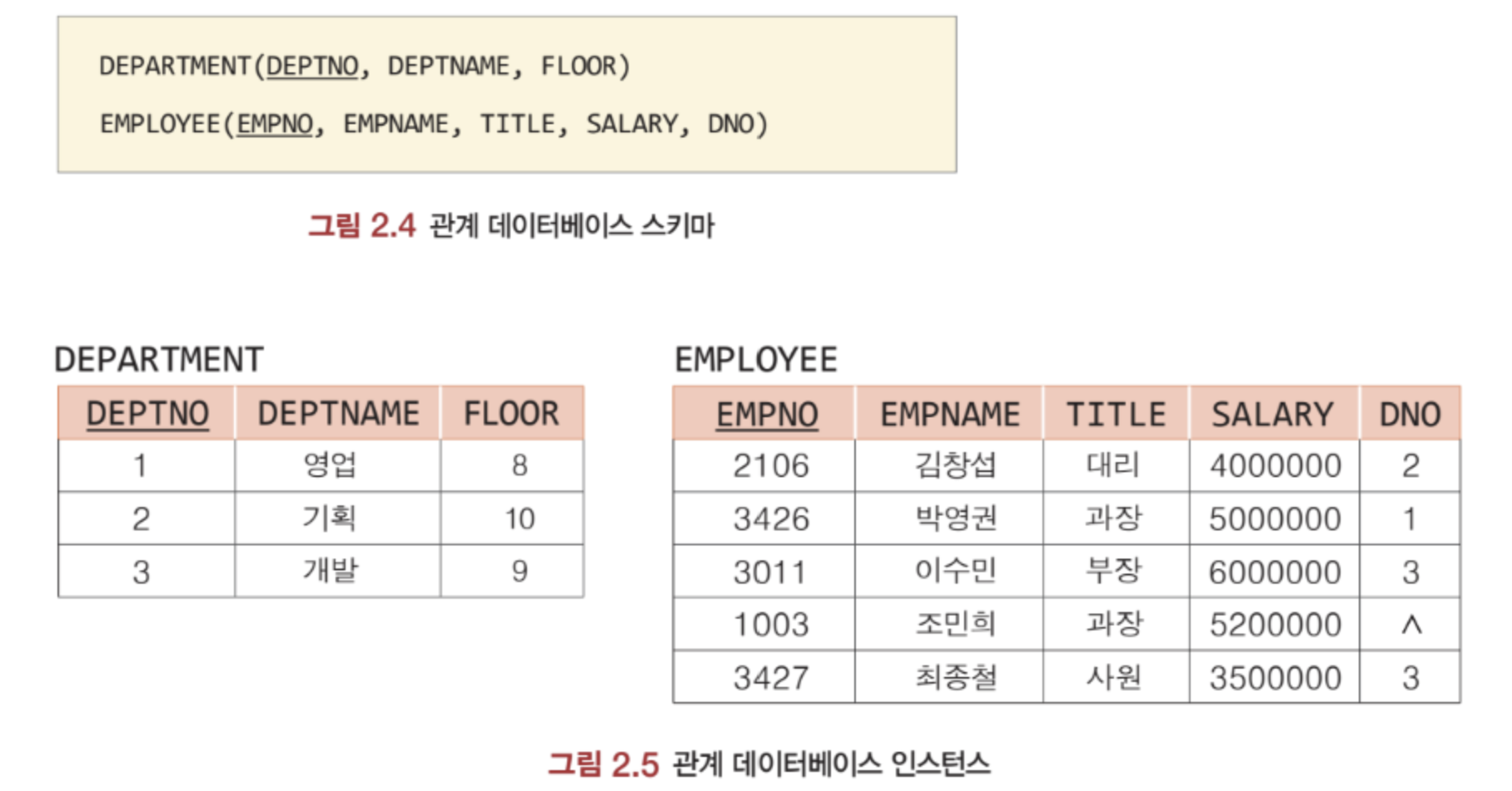
릴레이션의 특성
각 릴레이션은 오직 하나의 레코드 타입만 포함한다. 즉, 동일한 애트리뷰트를 가진 튜플들의 집합으로 이루어져 있다는 의미이다. 한 애트리뷰트 내의 값들은 모두 동일한 도메인이며, 동일한 튜플이 두 개 이상 존재하지 않는다. 튜플을 구별할 수 있는 키가 존재하며, 키를 이용하여 유일한 하나의 튜플을 식별할 수 있다.
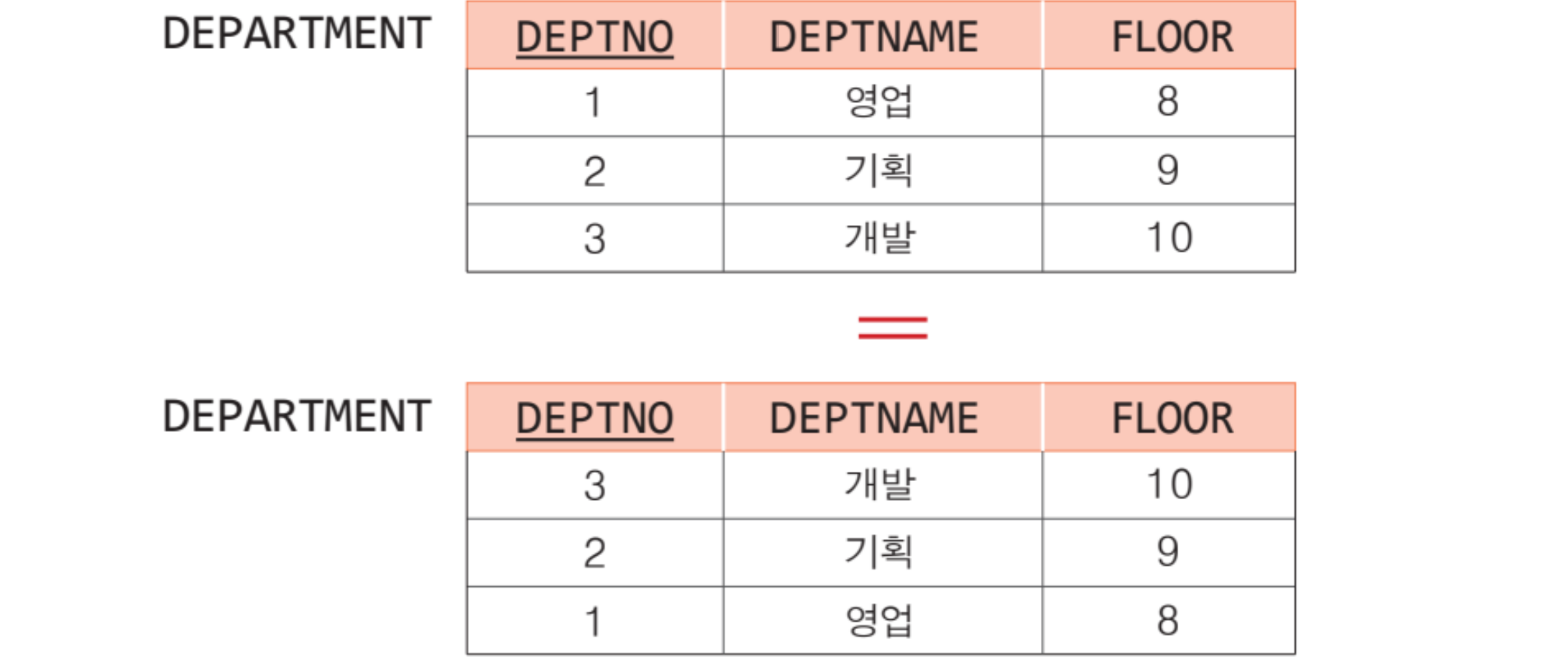
- 튜플들의 순서는 중요하지 않음.
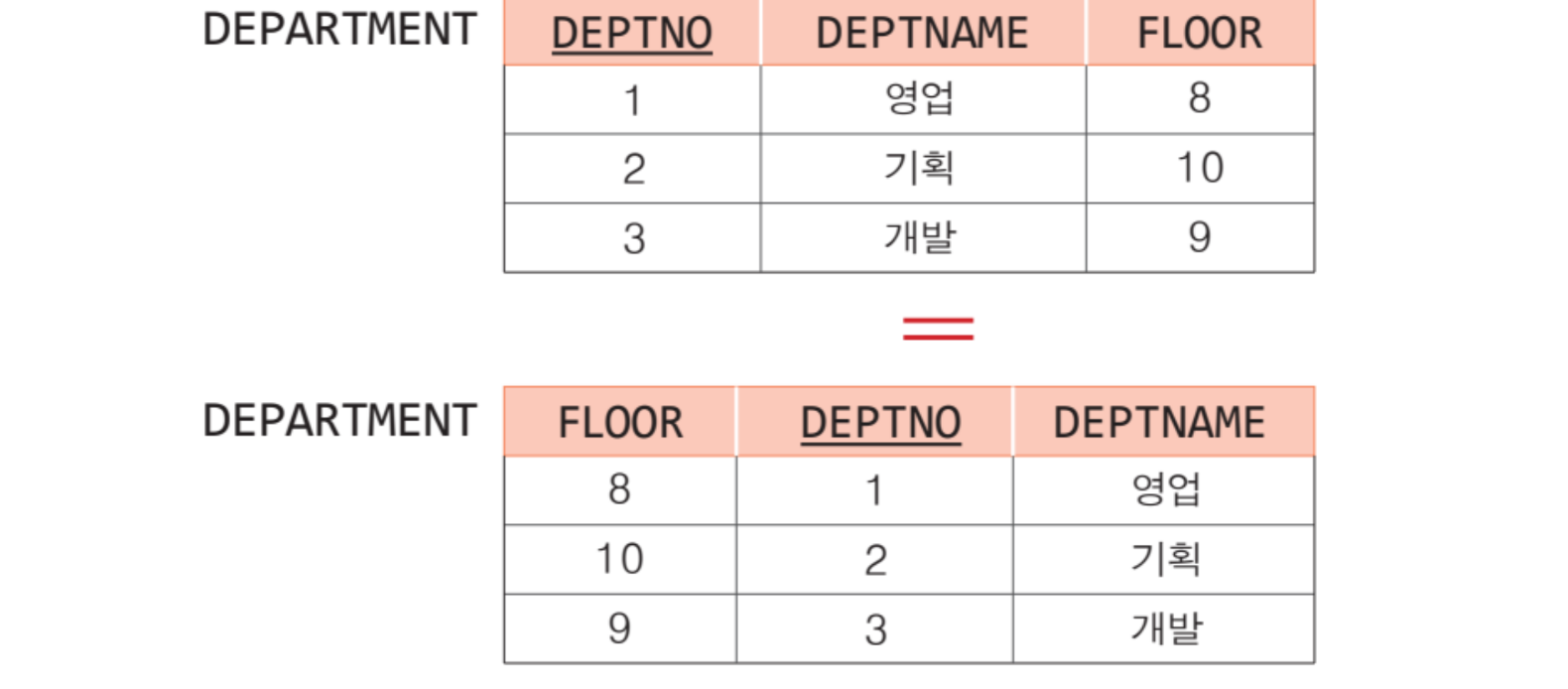
- 애트리뷰트들의 순서는 중요하지 않음.
- 각 애트리뷰트는 원자값을 가져야 함.
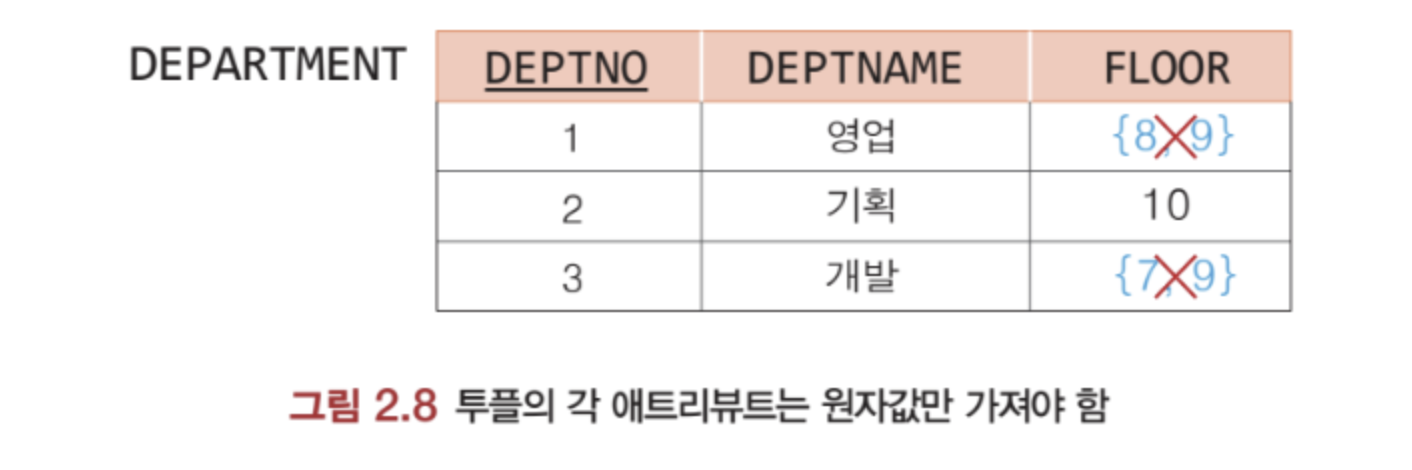
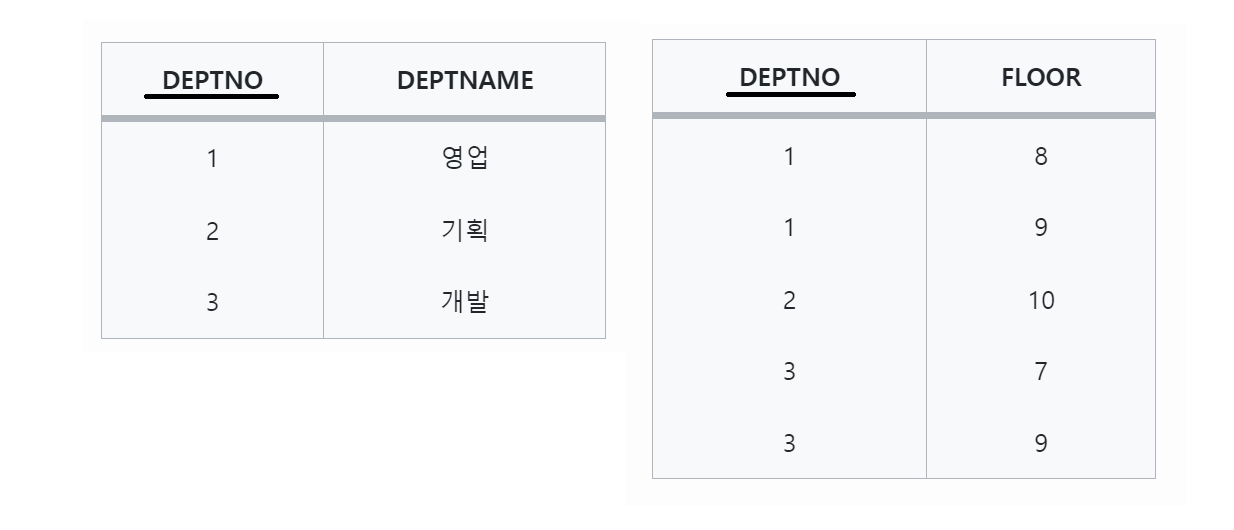
따라서 아래의 그림처럼 부서 번호를 키로 하여 참조하는 릴레이션을 따로 작성하는 것이 일반적인 방법이다.