1. Programming Model
IPU가 다른 프로세서와 비교했을 때 가장 차별화되는 점은 tile에 위치한 코드의 병렬 실행이다. IPU가 프로그램을 실행할 때, 모든 tile이 해당 task에 대해 병렬 작업을 수행한다. 각각의 tile은 각각 다른 코드를 실행하고 로컬 메모리에 저장되어 있는 데이터에 대한 연산을 수행한다. tile은 연산이 끝나는 시점에 데이터를 서로 교환할 수 있다. 모든 tile이 이 작업을 수행하기 위해서는 반드시 동기화되어야 한다.
일반적으로 IPU 애플리케이션은 다차원 배열 데이터(텐서)를 저장하는 변수에서 동작한다. 이 작업은 각각의 서로 다른 tile에 저장된 변수 부분에서 tile 전체에 걸쳐 분산될 수 있다.
1.1. Graph representation
IPU 프로그램이 실행되면, 하나 이상의 텐서로부터 데이터를 읽어온 다음 그 결과를 다른 텐서에 쓴다. 텐서들은 여러 개의 tile에서 처리될 수 있고, 텐서의 일부에서 수행되는 작업은 가까이에 저장된다.
이 연산은 정점이 tile에 의해 실행되는 코드를 표현하는 그래프로 표현할 수 있다. 간선은 정점에 의해 계산되는 데이터를 의미한다. 만약 데이터가 vertex 코드를 실행중인 tile의 메모리에 있다면, 이 간선은 로컬 메모리에 읽고 쓴다는 것을 의미한다. 만약 다른 tile에 저장된 변수들이 있다면, 간선들은 exchange fabric을 통해 데이터를 주고 받는 것을 의미한다.
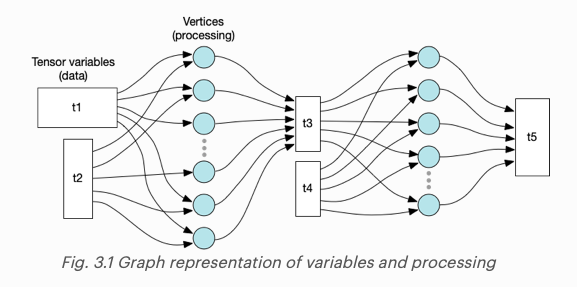
정점(vertex)에 의해 실행되는 함수는 간단한 산술 연산에서부터 텐서 데이터에 대한 reshape/transpose, N차원 컨볼루션 연산까지 어떤 것이든 될 수 있다.
다음은 부동 소수점 형식 데이터인 x, y를 입력으로 받고 두 데이터의 합을 출력(sum)하는 간단한 vertex이다. 해당 입력과 출력은 더 복잡한 연산을 수행하는 규모가 더 큰 그래프의 vertex에 연결될 수도 있다.
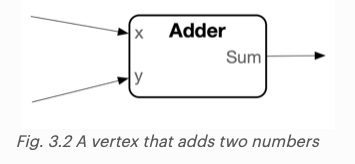
이 vertex를 실행하는 코드는 https://docs.graphcore.ai/projects/ipu-overview/en/latest/programming_tools.html#writing-vertex-code 에서 확인할 수 있다.
Poplar 프레임워크는 텐서 연산을 정의한 수많은 함수들을 포함한다. 그래프 생성과 vertex 코드 작성에 대한 더 많은 정보는 https://docs.graphcore.ai/projects/poplar-user-guide/ 에서 확인할 수 있다.
1.2. Executing code in parallel
하나의 그래프는 IPU 전역에 걸쳐 분산될 수 있기 때문에 모든 vertex는 병렬로 실행된다. 각각의 tile은 하나 이상의 vertex를 실행하고, 로컬 메모리에 저장된 데이터에 대한 연산을 수행하며, 다른 tile과 연산 결과를 주고 받는다.
병렬 실행되는 vertex의 집합은 compute set으로 불린다. 실행 순서는 모든 타일에 적재되는 control program에 의해 정의된다. 연산 그래프는 아래와 같이 나타낼 수 있다.
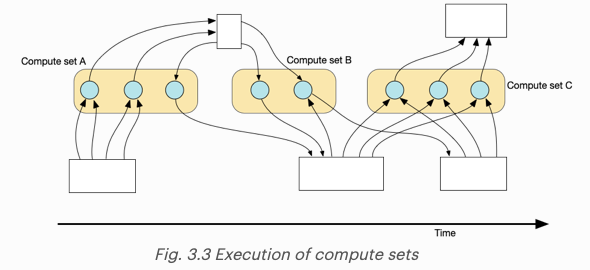
IPU는 task를 여러 단계에 걸쳐 실행하는 bulk-synchronous parallel (BSP) 방식을 사용한다. 각 단계는 다음과 같이 구성되어 있다.
- local compute
- global synchronous
- data exchange
compute 단계에서는, 모든 tile이 로컬 데이터에 대한 연산을 수행하며 병렬 실행된다. 각각의 tile들은 실행을 마친 후에 동기화 상태로 진입한다. 모든 tile이 동기화 상태에 진입했을 때, IPU는 tile끼리 데이터를 서로 복제하는 exchange 단계에 진입한다.

exchange 단계 이후에, 이 과정은 반복된다. tile은 compute 단계로 진입하면서, 로컬 데이터를 이용하여 연산을 수행하고 exchange 단계동안 새로운 데이터를 받아온다.
프로그램은 exchange 단계와 compute 단계를 번갈아가며 실행하면서 계속 진행된다. 타임라인에서 볼 수 있듯이, 각각의 tile들은 sync, exchange, compute 단계를 순서대로, 그리고 반복해서 실행하는 것을 확인할 수 있다.

각 단계는 모든 tile에 걸쳐 병렬 실행되지만, 모든 IPU는 sync, exchange, compute 단계로 구성된 연속적인 방식으로 일련의 단계를 실행하는 것으로 보일 수 있다.
실행 순서를 결정하기 위해서 각 tile은 control program을 포함한다. 이는 compute, exchange 단계 실행을 제어하기 위해 호스트에 의해 모든 타일에 적재된다.
sync와 exchange 단계는 일반적으로 Poplar 라이브러리에 의해 제어되기 때문에 사용자는 별도로 다룰 필요가 없다.
1.3. Host interface
호스트는 코드와 초기 데이터를 IPU에 적재하면서 시작한다. 이는 여러 개의 control program을 포함할 수 있다.
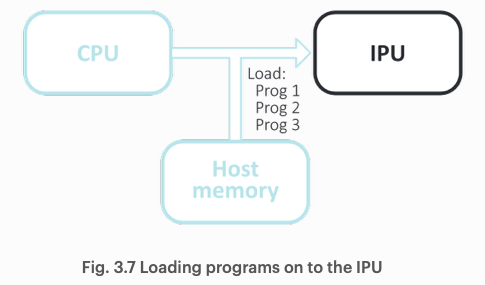
프로그램이 배치되면, 프로그램 실행을 위해 필요한 모든 코드와 자료 구조들이 IPU의 분산 메모리에 위치된다. CPU는 적절한 vertex를 실행하기 위해 여러 control program 중 하나를 실행하라는 명령을 가속기에 전달할 수 있다.
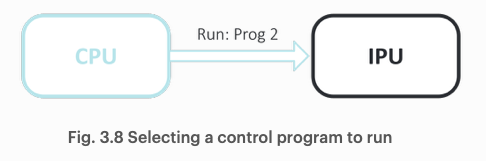
프로그램이 실행되는 동안, 가속기는 호스트 메모리로부터 데이터를 읽거나 쓰는 작업을 진행할 수 있다. 예를 들면, 프로그램은 신경망 모델(모델은 이미 프로세서에 위치해있다.)을 훈련시킬 때 훈련 데이터를 프로세서로 가져오라는 명령을 내릴 수 있다.
