씨앗 정기활동 1-1 : 알고리즘 이해하기

자료구조 특강이라곤하지만, 사실 알고리즘을 이해하기 위한 필수과정이라고 말할 수 있을 것 같습니다.
왜냐하면 거의 모든 알고리즘에서 하나이상의 자료구조를 사용하기 때문입니다.
일단 저희는 알고리즘 소모임이니까 알고리즘에 대해서 말해보지 않을 수가 없습니다.
알고리즘
'알고리즘'이라는 단어를 어떻게 설명할 수 있을까요?
사람마다, 책마다 차이는 있겠지만 한 문장으로 설명한다면
"어떤 문제를 해결하기 위한 단계적인 절차"라고 할 수 있겠습니다.
단순히 컴퓨터나 기계적인 절차들뿐만 아니라
맛있는 파스타 레시피, 천안에서 홍대까지 가는 길찾기 등과 같이 일상적인 절차들 또한 알고리즘이라고 할 수 있겠습니다.
예를 들어봅시다.
만약에 우리학교가 있는 병천에서 홍대까지 가고 싶다면 어떻게 해야 할까요?
- 택시를 타고 홍대까지 가는 방법
- 셔틀버스를 타고 교대역에서 내린 후, 지하철을 타는 방법
- 청주공항에서 비행기를 타고 김포공항에서 내린 후, 공항철도를 타는 방법
위 3가지 방법은 모두 실행 가능한 방법들입니다. 그런데 이 중에 어떤 방법이 가장 좋은 방법일까요?
장단점을 이해해야 한다
철수는 돈이 아주 많습니다. 그 대신 차멀미가 심해서 차를 탈 수가 없습니다. 그렇다면 철수에게는 세 번째 방법이 괜찮아보이죠.
반대로, 민호라는 친구는 수중에 만원밖에 없습니다. 그래서 두 번째 방법을 이용해야 홍대까지 갈 수 있을 겁니다.
이처럼 각자 어느정도의 자원(돈, 시간 등)을 가지고 있는 지, 어떤 특성을 가지고 있는 지에 따라서 선택해야할 방식이 결정됩니다.
이는 컴퓨터나 프로그램에게도 마찬가지입니다.
속도, 용량, 보안, 편리성 등등 어떤 특성을 얼만큼 요구하냐에 따라 해결방법, 즉 알고리즘은 다르게 설계되어야 합니다.
컴퓨터의 자원
컴퓨터의 자원은 크게 시간과 공간으로 나뉩니다.
다시 말하면 속도와 용량을 말합니다.
과거에는 메모리의 성능이 현재만큼 뛰어나지 못했기에
공간자원의 중요성이 비교적 많이 강조되었으나
현재는 공간보다는 시간의 중요성이 더 많이 강조되고 있습니다.
시간 복잡도
시간복잡도에 대해서 모두 알고계신다면 얘기가 바로 본론으로 들어가면 되겠지만 아닌 분들도 분명 계실 것이므로 설명을 하도록 하겠습니다.
어떤 알고리즘의 속도, 즉 얼마나 빠른 지를 어떻게 말할 수 있을까요?
A라는 알고리즘은 동작하는데 3초가 걸린다.
이런식으로 말하면 될까요? 물론 그것도 틀렸다고 할 순 없습니다.
하지만 누군가는 컴퓨터실에서 굉장히 낡은 컴퓨터를 이용할 수도 있고, 다른 누군가는 피시방에서 최신 사양의 컴퓨터를 이용할 수도 있습니다. 제가 굳이 설명하지 않더라도, 그 두 컴퓨터의 성능차이가 프로그램의 실행속도 차이를 야기할 수 있다는 것을 우리는 알고 있습니다.
따라서 알고리즘의 시간적인 성능을 평가하기 위해선 객관적인 지표가 필요하고 우리는 그것을 시간복잡도라고 부릅니다.
우선 시간 복잡도의 정의는 '입력의 크기에 따라 실행되는 연산의 횟수'입니다. 이때 입력이란 '해당 알고리즘을 수행하기 위해 외부로부터 제공되는 자료'를 말하죠. "A + B = ?" 라는 식에서는 A와 B가 입력에 해당하고, "정수배열 C에서 가장 큰 값을 구하세요" 라는 문제에서는 C가 입력이 됩니다.
우리가 다룰 대부분의 알고리즘들은 입력의 크기가 커지게 되면 연산의 개수도 함께 커지게 됩니다. 그 때, 연산의 횟수가 얼마나 커지느냐 가 곧 알고리즘의 성능, 시간 복잡도인 것입니다.
어떤 알고리즘의 실제 실행시간은 연산의 개수에 의해 결정됩니다. 1개의 연산이 실행되는데 필요한 시간은 굉장히 작겠지만 연산횟수가 매우 커진다면 시간도 굉장히 많이 필요해질 것입니다.
개수가 매우 크다? 얼마나 클까요? 1억? 아니면 1조?
굉장히 애매합니다. 그렇다면 아예 무한대로 보내버리는 건 어떨까요?
점근적 표기법
그래서 고안된 것이 바로 점근적 표기법 입니다.
입력의 크기, N이 무한대로 커질 때 그 알고리즘의 연산개수를 N에 대한 식으로 나타낸 것을 말합니다.
lim, 극한에 대해서 배우셨다면 금방 이해하실 수 있을 겁니다.
100 + 1은 간단히 101이라고 쓰겠지만
∞에 1을 더한다면? 그저 무한대일뿐입니다.
예를 들어, 어떤 알고리즘의 연산횟수가 f(n) = 2n + 1 이라면
n = ∞ 에서의 연산횟수는 그냥 n이라고 표기하게 됩니다.
다시 말하면 점근적 표기법은 입력이 무한히 클 때, 알고리즘의 시간 성능을 평가하는 방법인 것입니다.
그리고 입력의 질에 따라서 세 가지의 상황으로 점근적 표기를 분류합니다.
최상의 경우에서의, 빅오메가 표기법(Big-Ω Notation)
평균의 경우에서의, 빅세타 표기법(Big-θ Notation)
그리고 최악의 경우에서의, 빅오 표기법 (Big-O Notation)
최상, 평균, 최악? 이게 도대체 무슨 말일까요?
최악, 최상, 평균의 경우
여기서 말하는 최악, 최상, 평균은 사용된 입력이 해당 알고리즘에 얼마나 적합한 지를 이야기합니다.
예제를 보겠습니다.
A = [9, 8, 7, 6, 5, 4, 3, 2, 1]
#1 : A에서 10을 찾기
#2 : A에서 5를 찾기
#3 : A에서 9를 찾기
#1은 10을 찾는 알고리즘입니다. 그런데 A에는 10이 없습니다.
결국 A는 9,8,..2,1까지 모두 탐색한 후에 10이 없다는 것을 알게 됩니다. 이처럼 알고리즘의 연산횟수가 최대가 되는 입력을 최악의 입력이라고 합니다.
#2는 5를 찾습니다. 배열 A에 중간정도의 5가 위치하고 있으므로 많지도 적지도 않은, 평균정도의 연산을 통해 5가 있다는 결과를 얻을 것입니다. 이렇게 평균정도의 연산횟수를 갖게하는 입력을 평균의 입력이라고 합니다.
#3은 9를 찾는데, 가장 첫자리에 9가 있습니다. 연산 한번만에 알고리즘은 종료될 것입니다. 그러므로 배열 A가 #3의 최상의 입력입니다.
빅오 표기법을 주로 이용하는 이유
위에서 봤던 #1을 다시보죠.
배열에서 10을 찾는 이 알고리즘을 평가해봅시다.
배열의 크기가 N일때, 이 알고리즘의 연산횟수 f(N)은 뭘까요?
아마도 여러분은 N이라고 답할 것입니다.
왜냐하면 이 알고리즘은 연산을 아무리 많이 하게되도 N번보다 많이 반복하지는 않을 것이니까요.
그래서 최악의 입력에서의 성능을 평가하기 위해 빅오 표기법을 많이 이용하는 것입니다.
그렇다고 해서 최상, 평균에 대해서 아예 다루지 않는 것은 아닙니다.
실제로 사용되는 알고리즘들 중 대다수가 평균적인 입력을 기대하며 사용되고 있습니다.
하지만, 최악의 입력에서 성능이 극도로 저하되는 알고리즘을 평범하게 사용하기는 힘들 것입니다.
빅오표기법, 그래서 어떻게 사용할까?
지금까지 점근적표기법, 그리고 빅오표기법이 왜 사용되는 지에 대해서 알아봤습니다.
이제 어떻게 사용하는 지 알아보겠습니다.
먼저 어떤 알고리즘의 연산횟수를 알아야 합니다. f(n)으로 나타내겠습니다.

이 때, 빅오 표기법으로 나타내는 O(g(n)) 의 수학적 정의는 다음과 같습니다.

무슨 말인지 잘 모르겠죠?
그렇다면 아까 제가 한 말만 기억하세요.
예를 들어, 어떤 알고리즘의 연산횟수가 f(n) = 2n + 1 이라면
n = ∞ 에서의 연산횟수는 그냥 n이라고 표기하게 됩니다.
이 예시들을 보면 더 명확히 이해되실겁니다.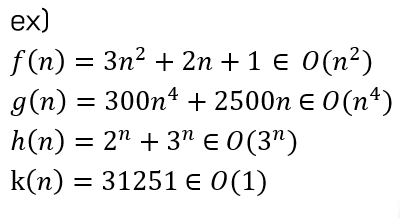
사실 f(n)이 나와있는 상태에서 빅오표기법으로 나타내는 것은 전혀 어렵지 않은 작업입니다.
진짜 재미(?)는 f(n)을 모르는 상황이죠.
그러나 오늘은 이미 너무 많은 것을 얘기하느라 저도 여러분도 지쳤을테니
다음에 살펴보도록 하겠습니다.
다음 글은 씨앗 정기활동 1-2 (주제 : 선형자료구조) 로 돌아오겠습니다. 감사합니다.
끝으로
혹시 글을 읽으시고 질문이나 피드백이 있으시다면 언제든지 남겨주시기 바랍니다.
더 나은 자료와 내용을 담을 수 있게끔 노력하겠습니다. 감사합니다.
