INSERT
일반적으로 온라인 트랜잭션 서비스에서 INSERT 문장은 대부분 1건 또는 소량의 레코드를 INSERT하므로 성능에 대해 고려할 부분이 많지 않다. 또한 INSERT와 SELECT 성능을 동시에 빠르게 만들 수 있는 테이블 구조는 없어 테이블의 용도에 따라 테이블 구조를 선택해야한다.
1. 기본 폼
-- INSERT INTO 테이블명(컬럼1, 컬럼2, ...) VALUES(데이터1, 데이터2, ...)
INSERT INTO salaries(emp_no, salary, from_date, to_date)
VALUES(10001, 60117, '1896-06-26', '1987-06-26');
-- INSERT INTO 테이블명 VALUES(데이터1, 데이터2, ...)
INSERT INTO table_name VALUES('10001, 60117, '1896-06-26', '1987-06-26')2. INSERT IGNORE
INSERT IGNORE은 유니크 인덱스가 중복되거나 데이터 타입이 일치하지 않아서 INSERT를 할 수 없는 경우에도 INSERT를 할 수 있게한다. IGNORE 사용시 에러가 경고 수준의 메시지로 바뀐다.
주로 INSERT하고자 하는 데이터가 정교하지 않아도 되는 경우 사용한다.
-유니크 인덱스가 중복되는 경우
-- salaries 테이블의 프라이머리 키는 (emp_no,from_date)
INSERT IGNORE INTO salaries(emp_no, salary, from_date, to_date)
VALUES(10001, 60117, '1896-06-26', '1987-06-26'),
VALUES(10001, 60118, '1896-06-26', '1987-06-26'),
VALUES(10001, 60119, '1896-06-26', '1987-06-26');
INSERT IGNORE INTO salaries
SELECT emp_no, (salary+100), '2020-01-01', '2022-01-01'
FROM salaries WHERE to_date>='2020-01-01';
-데이터 타입이 불일치할 경우
-- NOT NULL칼럼인 emp_no와 from data에 null을 입력
-- 이 경우 각 타입의 기본값으로 바뀌어 저장되게 됨
INSERT IGNORE INTO salaries VALUES(NULL,NULL,NULL,NULL)
2. INSERT ... ON DUPLICATE KEY UPDATE
INSERT ... ON DUPLICATE KEY UPDATE은 유니크 인덱스의 중복이 발생하면 UPDATE의 역할을 수행한다.
-- salaries 테이블의 프라이머리 키는 (emp_no,from_date)
INSERT IGNORE INTO salaries(emp_no, salary, from_date, to_date)
VALUES(10001, 60117, '1896-06-26', '1987-06-26'),
ON DUPLICATE KEY UPDATE salary=salary+1최초로 저장되는 경우에는 INSERT가 수행되고 이미 레코드가 존재한다면 ON DUPLICATE KEY UPDATE절 이하의 내용이 실행된다.
3. LOAD DATA
LOAD DATA는 CSV 파일 포맷 또는 일정 규칙을 지닌 구분자로 구분된 데이터 파일을 읽어 MySQL 서버의 테이블로 저장한다. 일반적으로 INSERT 명령과 비교했을 때 매우 빠르다. 하지만 단일 스레드 및 단일 트랜잭션으로 실행되기 때문에 데이터가 매우 크다면 단일 스레드기 때문에 실행 시간이 길어지고, 단일 트랜잭션이기 때문에 LOAD DATA문장이 시작한 시점부터 UNDO LOG가 삭제되지 못하고 유지돼야 한다.
4. 성능을 위한 테이블 구조
4-1 PRIMARY KEY와 INSERT
대량 INSERT를 해야하는 경우에는 INSERT될 레코드들을 프라이머리 키로 미리 정렬하여 INSERT 문장을 구성하는 것이 좋다. MYSQL은 B-TREE(?)로 프라이머리 키의 인덱스를 저장하기 때문에, LOAD DATA 문장이 레코드를 INSERT 할때마다 프라이머리 키를 검색하여 레코드가 저장될 위치를 찾아야한다. 각 프라이머리 키가 너무 다른 값을 가지고 있다면 B-TREE(?)에서 이곳저곳 랜덤한 위치의 페이지를 메모리로 읽어와야 하기 때문에 처리가 더 느려진다. 반면 프라이머리 키로 정렬이 되있다면, 다음에 INSERT할 레코드의 프라이머리 키 값이 직전에 INSERT된 값보다 항상 크기 때문에 메모리에는 프라이머리 키의 마지막 페이지만 적재되 있으면 새로운 페이지로 메모리로 가져오지 않아도 레코드를 저장할 위치를 찾을 수 있다. 그렇기 때문에 INSERT에 최적화된 테이블을 생성한다면 AUTO-INCREMENT 칼럼이 효과적이다.
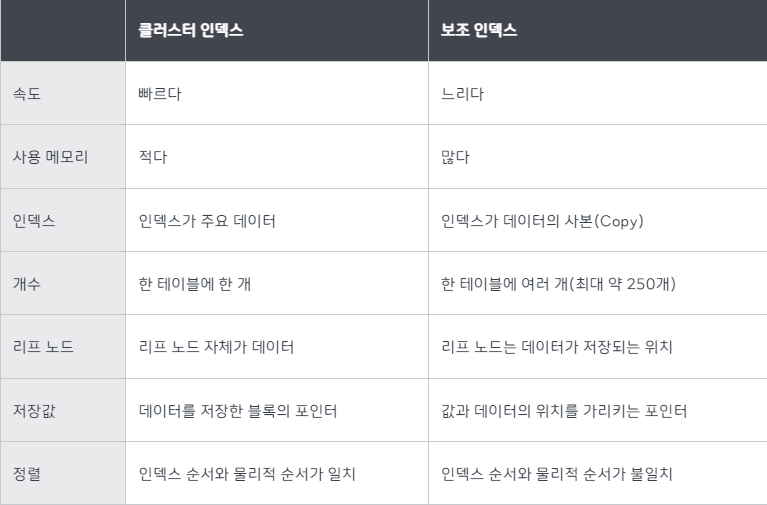
4-2 세컨더리 인덱스와 INSERT
세컨더리 인덱스는 SELECT 문장의 성능을 높이지만, 반대로 INSERT 성능은 떨어진다. 만약 세컨더리 인덱스도 정렬된 수서대로 INSERT될 수 있다면 더 빠른 성능을 높일 수 있지만 현실적으로 힘들다. MYSQL에서는 보통 클러스터키를 제외한 UNIQUE키는 세컨더리 인덱스가 된다.
4-3 CLUSTERING INDEX VS SECONDARY INDEX