
우리 가게 앞에 누가 이쁜 눈사람 만들어놨더라😌 (눈코입이 커피콩인건 비밀)
1. Introduction
기존 방식의 한계
Atomic Units
많은 현재 NLP 시스템이 단어를 ‘원자 단위 (Atomic Units)’로 취급한다. 해당 취급 과정은 단어 간의 유사성 개념이 없고 어휘를 그저 인덱스로 표현할 뿐이다.
→ 그냥 의미가 따로 없는 단어들을 인덱싱 하는 것
문제점
이 방식은 단어 간 유사성 (Similarity)이라는 개념이 전혀 없다. 예를 들어 100번 인덱스 (Mango)와 101번 인덱스 (dog)은 숫자상으로는 가깝지만, 시스템은 이 둘이 1번 인덱스 (’Apple’) 보다 더 가깝다는 것을 알지 못한다.
기존 방식이 쓰였던 이유
이 방식은 단순하고(simplicity), 튼튼하며 (robustness), 적은 데이터로 학습시킨 복잡한 모델보다 엄청나게 많은 데이터로 학습시킨 간단한 모델 (N-gram)의 성능이 더 좋았기 때문에 인기가 많았다. N-gram 모델은 현재 사용 가능한 거의 모든 데이터로 학습시킬 수 있을 정도이다.
🔥N-gram Model?
자연어 처리에서 많이 사용되는 확률 기반 언어 모델을 말한다.
N-gram : 주어진 텍스트에서 단어의 나열을 분석하여 다음에 올 단어를 예측하는 것
다시 말해, 문장에서 다음 단어의 확률을 이전 n-1개의 단어만 보고 추정하는 확률 언어 모델이다.
bigram(2-gram)은 한 단어만(이전 1개) 보고, trigram(3-gram) 은 이전 2개를 본다.[n-gram의 예시]
An adorable little boy is spreading smiles.
위 예시 문장을 사용해서 알아보자.
- Unigrams : An, Adorable, little, boy, is, spreading, smiles
- bigrams : An adorable, adorable little, little boy, boy is ,…
- trigrams : An adorable little, adorable little boy, little boy is, …
- 4-grams : An adorable little boy, adorable little boy is , …
근본 아이디어 : 문장 확률을 체인룰로 분해하고 Markov 근사 (이전 n-1개만 영향)를 적용한다.
확률 추정 (MLE - 카운트 기반)
음.. 여기까지만 알아보도록 하자.
한계 도달
단순히 데이터만 늘리는, Scaling up하는 간단한 기술을 많은 작업에서 한계에 도달했다.
예를 들어, 자동 음성 인식이나 기계 변역 같은 분야에서는 고품질의 학습 데이터가 제한적이기 때문이다.
대안 제시
더 이상의 큰 성능 향상을 위해서는 더 발전된 기술 (more advanced techniques)에 집중해야 한다. 최근 머신러닝 기술이 발전하면서, 더 복잡한 모델을더 큰 데이터셋으로 학습시키는 것이 가능해졌고, 이들이 간단한 모델의 성능을 앞지르기 시작했다.
그 중 가장 성공적인 개념이 바로 단어의 분산 표현 (Distributed Representations of words)이다. → 논문이 제안하는 Word2Vec가 여기에 속한다.
1.1 Goals of the Paer
수십억 개의 단어 (huge data sets with billions of words)와 수백만 개 단어의 어휘집 (millions of words in the vocabulary)을 가진 거대한 데이터로부터 고품질의 단어 벡터 (high-quality word vectors)를 학습할 수 있는 기술을 소개하는 것이다.
이 논문에선느 단어 간의 선형 규칙성을 유지하는 새로운 모델 Architecture를 개발하여 벡터 연산의 정확도를 극대화하려 한다.
기존의 신경말 모델 (NNLM, RNNLM)의 복잡성을 유발하는 주 원인인 비선형 은닉 계층을 제거하여 계산 복잡도를 최소화하는 새로운 log-linear 모델 아키텍쳐 (CBOW 및 Skip-gram)을 제안한다.
종합적으로 볼 때, 이 연구의 궁극적인 목표는 기존 신경망 모델이 처리하기 어려웠던 방대한 데이터를 효율적으로 활용하여, 단어 간의 복잡하고 미묘한 선형 규칙성을 정확하게 포착하는 가장 정확하고 고차원적인 단어 벡터를 계산하는 새로운 방법론을 제시하는 것이다.
1.2 Previous Work
NNLM은 Linear Projection Layer와 non-linear hidden layer를 가진 feedforward신경망을 사용한다. 단어의 벡터 표현과 통계적 언어 모델을 동시에 학습하는 방식이다.
이후 단어 벡터를 먼저 단일 은닉층 신경망으로 학습시킨 뒤, 이를 이용해 NNLM을 학습시키는 Architecture가 제안되었다. 이렇게 하면 전체 NNLM을 구축하지 않아도 단어 벡터를 학습시킬 수 있다.
이 논문은 바로 이 NNLM을 확장하고 단순한 모델을 사용하여 단어 벡터가 학습되는 단계에 집중한다.
기존 신경망 모델들이 단어 벡터 학습에 유용했지만 계산 복잡도가 높은 단점이 존재했다. 이러한 계산 효율성을 개선한 새로운 모델 (CBOW, Skip-gram)을 제안하게 된 배경이다.
2. Model Architectures
기존의 신경망 언어 모델(NNLM)들은 성능은 좋았지만, 학습 속도가 너무 느렸다. 이 논문은 정확도를 유지하면서 계산 복잡도를 획기적으로 낮추는 것을 궁극적인 목표로 한다.
모델의 학습 복잡도는 다음과 같이 정의할 수 있다.
- : Training Epochs (보통 3 ~ 50)
- : Number of Training Words (최대 10억 개)
- : Computational Complexity (모델별 아키텍쳐에 따라 상이)
2.1 Feedforward Neural Net Language Model (NNLM)
기존 NNLM은 입력(Input) → 투사(Projection) → 은닉(Hidden) → 출력(Output) 4단계로 구성된다.
NNLM 구조는 Projection 층과 Hidden Layer 사이의 계산이 복잡해진다. Projection layer의 값이 Dense하기 떄문이다.
모델의 복잡도 공식은 다음과 같다.
- : Length of Context (이전 단어의 개수, 보통 10)
- : Dimension of Word Vector (보통 500 ~ 2000)
- : Size of Hidden Laye (보통 500 ~ 1000)
- : Size of Vocabulary
[문제점]
항이 지배적이다. → 출력층에서 모든 단어()에 대한 확률을 계산해야 하기 때문이다. 비선형 은닉층()가 존재하여 연산량이 많다.
→ 이에 대한 해결책으로 Hierarchical Softmax를 사용하거나 훈련 중 정규화 되지 않은 모델을 사용하여 정규화된 모델을 완전히 피하는 것이다.
어휘의 이진 트리 표현을 사용하면 평가해야 하는 출력의 유닛 수가 약 로 줄어든다. 따라서 대부분의 복잡성은 에 의해 발생한다.
논문의 모델에서는 어휘가 Huffman Binary Tree로 표현되는 계층적 softmax를 사용한다. 이는 단어의 빈도가 신경망 언어 모델에서 클래스를 얻는 데 잘 작용한다는 결과를 따른다. Huffman Tree는 빈번한 단어에 짧은 이진 코드 할당 → 평가해야 하는 출력 유닛의 수를 더 줄인다.
Balanced Binary Tree는 개의 출력을 평가해야 하지만, Huffman Tree 기반의 계층적 softmax는 약 만 필요하다.
이는 신경망 LM에 대한 결정적인 속도 향상은 아니지만, 병목 현상이 항에 있기 때문에, 논문에서는 나중에 은닉층이 없는 구조를 제안할 것이다.
2.2 RNNLM (Recurrent Neural Network)
RNNLM은 NNLM의 [context length를 specify 해야하는] 특정 한계를 극복하기 위해서 제안되었다.
RNN 모델은 Projection layer가 없으며, input, hidden, 그리고 output layer만 존재한다. 이 모델의 특별한 점은 은닉층을 자기 자신과 연결하는 순환 행렬이 있으며, 시간 지연 연결을 사용한다는 것이다.
→ 이를 통해 순환 모델은 과거의 정보를 은닉층 상태로 표현할 수 있는 일종의 Short Term Memory를 형성할 수 있다.
RNN모델의 훈련 복잡도는 다음과 같다.
여전히 가 병목이지만, 이는 계층적 소프트맥스를 사용하여 로 효율적으로 축소할 수 있기 때문에 대부분의 복잡성은 에서 나온다.
2.3 Parallel Training on Neural Networks
대규모 데이터 세트에서 모델을 훈련하기 위해서 DistBelif라고 불리는 Distributed Framework (대규모 분산 프레임 워크 위에 여러 모델 구현하는 방식) 방식을 사용했다.
이 프레임워크 하에서는 100개 이상의 모델 복제본을 사용하는 것이 일반적이며, 각 복제본은 데이터 센터의 서로 다른 머신에서 많은 CPU 코어를 사용한다.
3. New Log-linear Models
지금까지 계속 줄이고자 하는 계산 복잡성을 최소화하기 위해 단어의 분산 표현을 학습하기 위한 두가지 새로운 모델 구조를 제안한다. 이전 섹션에서의 중요한 포인트는
“대부분의 복잡성이 모델의 비선형 은닉층에 의해 발생한다”는 것이었다.
신경망만큼 데이터를 정밀하게 표현하지는 못하더라도, 훨씬 더 많은 데이터를 효율적으로 훈련할 수 있는 더 단순한 모델을 탐색하기로 결정했다. 이 새로운 Architecture는 저자들이 이전에 제안했던, 간단한 모델을 사용하여 연속 단어 벡터를 학습한 다음 그 위에 NNLM을 훈련하는 2단계 접근 방식을 직접적으로 계승한다.
새롭게 제안된 두 가지 log-linear 모델은 CBOW(Continuous Bag-of-Words Model)과 Skip-gram(Continuous Skip-gram Model)이다.
3.1 CBOW (Continuous Bag-of-Words Model)
CBOW는 문맥(context)를 기반으로 현재 단어를 정확하게 분류하는 것을 훈련 기준으로 삼는다.
NNLM과 유사한 구조로 비선형 은닉층이 제거되고 Projection layer가 모든 단어에 대해 공유된다. 따라서 모든 단어는 동일한 위치로 투영된다. (단어들의 벡터가 평균화된다.)
→ 이 구조를 단어의 순서가 투영에 영향을 미치지 않기 때문에 Bag-of-words 모델이라고 부른다.
이 모델을 CBOW라고 부르며, 표준 BoW와 달리 문맥의 연속 분산 표현을 사용한다.
구조 및 작동 방식
- 은닉 계층 제거 : Feedforward NNLM과 유사하지만, 결정적으로 비선형 은닉계층 제거
- 투사 계층의 공유 및 평균 : projection layer는 모든 단어에 대해 공유된다.
- 문맥 활용 (BoW) : 문맥 내 단어의 순서가 투영 결과에 영향을 미치지 않기 때문에 BoW라고 부른다.
- 연속 분산 표현 : 이 모델은 표준 BoW와 달리 문맥의 연속적인 분산 표현을 사용하기 때문에 CBOW라는 이름이 붙었다.
- 입력 문제 : 최상의 성능을 위해 CBOW는 입력으로 네 개의 미래 단어와 네 개의 과거 단어를 사용한다. (총 = 8 개의 문맥 단어)
- 가중치 행렬 공유 : 입력 계층과 투사 계층 사이의 가중치 행렬은 NNLM에서와 같은 방식으로 모든 단어 위치에 대해 공유된다.
계산 복잡도
- : Number of context words
- : Dimension of Vector
- : Size of Vocabulary
비선형 은닉 계층이 제거되었기 떄문에, 복잡성은 주로 소프트맥스 정규화의 효율성 ( 항)에 의존한다.
다음 장으로 넘어가기 전에 잠시 BoW에 대해서 조금 알아보자.
🔥 Bag of Words 란?
단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도 (frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법이다.
1. 갖고 있는 어떠한 텍스트 문서에 있는 단어들을 가방에다 넣고 섞는다.
2. 해당 문서 내에 특정 단어가 번 등장했다면, 그 가방엔 개의 특정 단어가 있을 뿐, 순서는 더이상 중요하지 않다.BoW 만드는 과정
(1) 각 단어에 고유한 정수 인덱스 부여 → 단어 집합 생성하기
(2) 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터 생성
텍스트를 형태소 단위로 나누는morphs()함수란?
1.okt.morphs()
- 텍스트를 형태소 단위로 나눈다. 옵션으로는
norm,stems가 있다.
norm: normalize 약자로 문장을 정규화 한다.stem: 각 단어에서 어간을 추출하는 기능이다- 리스트 형태로 반환한다.
주의하기
영어는 몰라도 한국어는 조사 등의 이유로 제대로 BoW가 안된다.
불용어를 제거한 BoW 만들기
불용어 제거하는 일은 자연어처리 정확도를 높이기 위해 선택할 수 있는 전처리 기법이다.
영어의 BoW를 만들기 위해 사용하는 CountVectorizer는 불용어를 지정하면 불용어는 제외하고 BoW를 만들 수 있도록 불용어 제거 기능을 지원한다.


Continuous Skip-gram Model
Skip-gram은 두 번째로 제안된 Architecture로, CBOW와 유사하지만, 목표가 반대이다.
[구조 및 작동 방식]
- 목표 : CBOW가 문맥을 기반으로 현재 단어를 예측하는 것과 달리, Skip-gram은 현재 단어를 기반으로 문맥 내의 단어를 분류하는 것을 최대화하려고 시도한다.
- 분류기 : 연속 투사 계층을 가진 log-linear classifier를 사용하며, 현재 단어 입력으로 사용하여 해당 단어 앞/뒤의 특정 범위 내에 있는 단어들을 예측한다.
- 범위(Range) C : 단어 벡터의 품질은 예측 범위를 늘릴수록 향상되지만, 이는 계산 복잡도도 증가시키낟.
- 가중치 감소 : 현재 단어에서 더 멀리 떨어진 단얻르은 보통 덜 관련이 있으므로, 훈련 예제에서 멀리 있는 단어들을 덜 샘플링하여 가중치를 덜 부여한다.
- 훈련 과정 : 훈련 시, 를 최대 거리로 설정하고, 각 훈련 단어에 대해 <> 범위 내에서 임의의 숫자 을 선택한다. 현재 단어의 앞/뒤로 각각 개의 단어를 ‘정답 레이블’로 사용하여 개의 단어 분류를 수행한다. [논문에서는 ]
계산 복잡도
- : Maximum length of context
640차원의 단어 벡터를 사용하여 모델 Architecture 비교
- CBOW : Syntacnic(구문적) 작업에서는 NNLM보다 우수, semantic(의미적) 작업에서는 NNLM과 비슷한 성능을 보인다.
- Skip-gram : Syntactic(구문적) 작업에서는 CBOW보다 약간 나빴지만 (NNLM보다는 여전히 우수함). 의미적 작업에서는 다른 모든 모델보다 훨씬 나은 성능을 보인다.
결론적으로, 이 새로운 log-linear 모델들은 비선형 은닉계층을 제거하여 계산 효율성을 극대화 함으로써, 이전 모델들이 도달할 수 없었던 대규모 데이터 세트에서 고차원, 고품질 단어 벡터를 매우 빠르게 학습할 수 있게 했다.
Figure 1
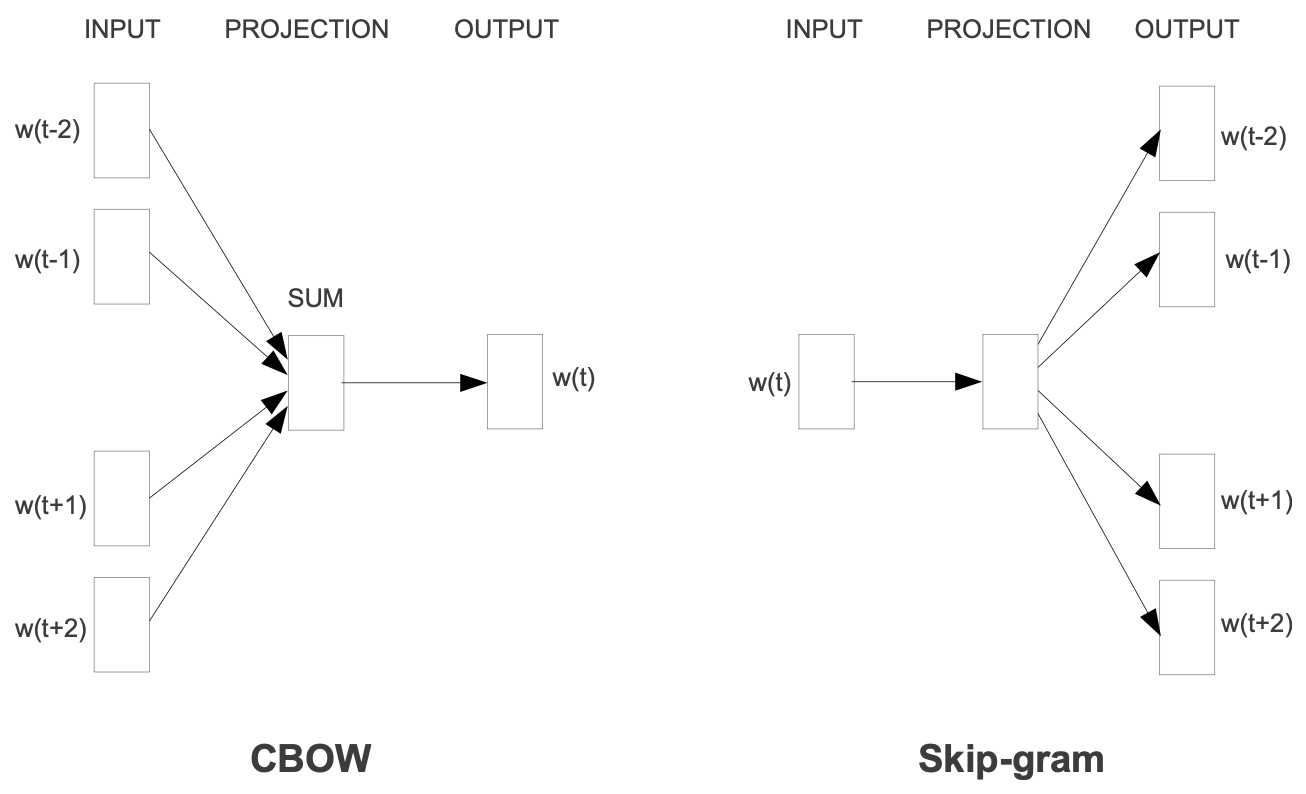
[Figure 1]은 논문에서 제안한 두 가지 새로운 log-linear model Architecture. 즉, CBOW와 Skip-gram을 시각적으로 비교하여 보여준다.
두 모델 모두 기존의 신경망 언어 모델(NNLM)의 복잡성을 유발했던 비선형 은닉 계층이 제거된 단순화된 구조를 사용한다.
| 구성 요소 | CBOW | Skip-gram |
|---|---|---|
| 입력 (INPUT) | 문맥 단어들 등 | 현재 단어 |
| 목표 / 출력 (OUTPUT) | 문맥을 기반으로 현재 단어 를 예측한다. | 현재 단어를 기반으로 주변 문맥 단어들 를 예측한다. |
| 투사 계층(PROJECTION) | 모든 문맥 단어 벡터가 동일한 위치로 투사된 후 합산(SUM)또는 평균화된다. 이 계층은 연속적인 분산 표현을 사용한다. | 현재 단어 벡터가 투사 계층을 거쳐 출력 계층으로 전달된다. |
| 작동 원리 | 주변 단어들의 정보를 모아 중심 단어를 예측한다. | 중심 단어 하나를 이용해 주변 단어들을 개별적으로 예측한다. |
요약
- CBOW : 문맥(Context) 단어들을 입력으로 받아 현재 단어 를 예측한다. 이는 비선형 은닉 계층이 제거되고 투사 계층이 공유되며 단어 벡터들이 평균화된다는 점에서 Feedforward NNLM과 유사하다.
- Skip-gram : 현재 단어 를 입력으로 받아 특정 범위 내의 주변 문맥 단어들을 예측한다.
4. Results
논문은 단어 벡터의 품질을 측정하기 위해 기존에 주로 사용되던 ‘비슷한 단어 나열’ 방식 대신, 단어 벡터의 대수적 연산(Algebraic Operations)를 통해 구문적(Syntactic) 및 의미적(Semantic) 규칙성을 측정하는 새로운 테스트 방법을 사용한다.
예를 들어 벡터() - 벡터() + 벡터()을 계산한 후 벡터 공간에서 가장 가까운 단어를 찾는 방식이다.
4.1 Task Descriptions
단어 벡터의 품질을 측정하기 위해 5가지 유형의 의미적 질문과 9가지 유형의 구문적 질문을 포함하는 포괄적인 테스트 세트 (Semantic-Syntactic Word Relationship test set)를 정의했다.
- 의미적 질문 (Semantic Questions) : ‘수도-국가’ (예 : Athens - Greece, Oslo - Norway), ‘도시-주’, ‘통화’, ‘남성-여성’ 등의 관계를 포함한다. (총 5가지 유형)
- 구문적 질문 (Syntactic Questions) : ‘형용사-부사’, ‘비교급’, ‘최상급’, ‘현재 분사’, ‘과거형’, ‘복수 명사’ 등의 형태학적 관계 포함
테스트 세트는 총 8,869 개의 의미적 질문과 10,675 개의 구문적 질문으로 구성되어 있다.
4.2 Maximization of Accuracy
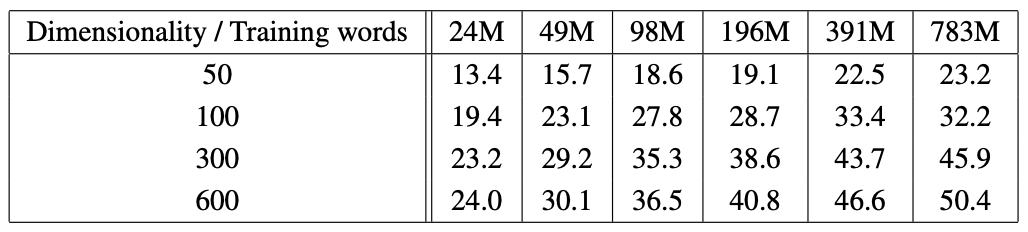
[Table 2]는 CBOW Architecture를 사용하여 제한된 어휘 (가장 빈번한 30k 단어)와 다양한 차원의 수() 및 훈련 데이터 양에 따른 정확도를 보여준다.
[Table 분석]
- 차원 및 데이터의 상호작용 : 데이블에서 볼 수 있듯, 어느 시점 이후에는 차원을 추가하거나 훈련 데이터를 더 추가하는 것이 효용 체감을 보인다. 따라서 정확도를 높이기 위해서는 벡터 차원 ()과 훈련 데이터의 양을 함께 늘려야 한다.
- 계산 복잡도와 균형 : Equation 4에 따르면, 훈련 데이터 양을 두 배로 늘리는 것은 벡터 크기를 두 배로 늘리는 것과 계산 복잡도가 증가 측면에서 거의 동일하다.
- 최고 성능 : 제한된 어휘를 사용했을 때 600차원에서 가장 많은 훈련 데이터(783M 단어)를 사용했을 때 50.4%의 최고 정확도를 기록했다.
4.3 Comparison of Model Architectures
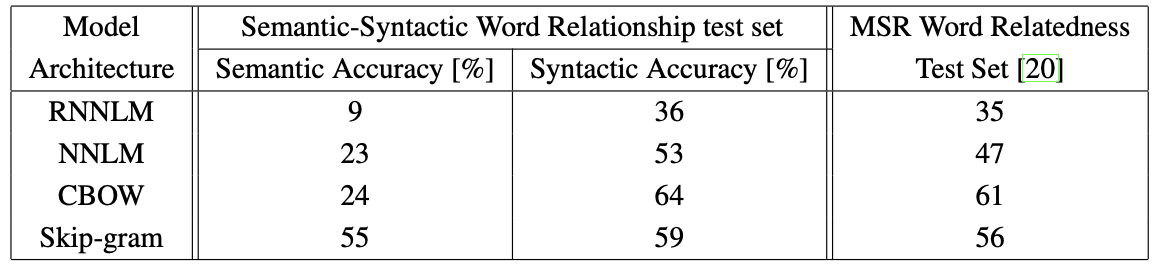
[Table 3]는 640차원 벡터를 사용하여 동일한 데이터 (320M 단어, 82K 어휘)로 훈련된 모델 아키텍쳐들을 비교한 결과이다.
[Table 분석]
- NNLM vs RNNLM : NNLM 벡터는 RNNLM보다 훨씬 더 나은 성능을 보인다. 이는 RNNLM의 단어 벡터가 비선형 은닉계층에 직접 연결되어 있는 반면, NNLM은 투사 계층이 별도로 존재하기 때문인 것으로 추정된다.
- CBOW의 강점 : CBOW 아키텍쳐는 구문적 작업에서 NNLM보다 더 나은 성능을 보이고, 의미적 작업에서는 NNLM과 거의 비슷한 성능을 보인다. CBOW는 구문 정확도에서 64%로 가장 높았다.
- Skip-gram의 강점 : Skip-gram 아키텍쳐는 구문적 작업에서는 CBOW보다 살짝 낮았지만 (여전히 NNLM보다는 우수함), 의미적 작업에서는 다른 모델들보다 월등히 뛰어난 성능을 보인다.
4.4 Large Scale Parallel Training of Models
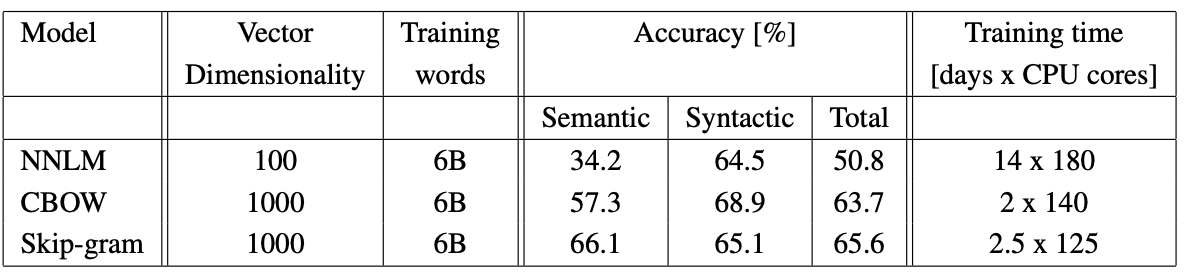
[Table 6]는 Dis-tBelief 분산 프레임워크를 사용하여 Google News 60억 단어 데이터 세트에서 훈련된 모델들의 결과이다.
[Table 분석]
- 대규모 훈련의 이점 : NNLM이 100차원 벡터를 훈련하는 데에 14일이 걸리는 반면, CBOW와 Skip-gram은 1000차원의 고차원 벡터를 60억 단어 데이터 세트에서 2~2.5일 만에 훈련했다. 이는 새로운 모델들이 기존 모델 대비 엄청난 계산 효율성을 제공함을 보인다.
- 최고 정확도 : Skip-gram 모델은 1000차원에서 의미 정확도 66.1%로 가장 높았으며, 전체 정확도 65.6%로 가장 뛰어난 성능을 보여준다.
- 효율성 : 분산 프레임워크의 오버헤드에도 불구하고, CBOW와 Skip-gram 모델은 대규모 훈련에서 매우 효율적이며, NNLM이 1000차원 벡터로 훈련될 경우 너무 오래 걸려 완료하기 어렵다는 점과 비교된다.
4.5 Microsoft Research Sentence Completion Challenge

[Table 7]은 Skip-gram 모델의 성능과 기존 모델의 결과를 요약하여 보여준다.
Microsoft Research challenge
- 목표 : 1,040개의 문장에 대해, 각 문장에서 누락된 단어를 식별하는 것이다.
- 각 문장에는 하나의 단어가 빠져있고, 다섯 가지의 선택지 목록 중 하나의 단어를 선택해야 한다.
기존 성과 및 비교
이 논문이 작성될 당시, RNNLM이 55.4%로, SOTA를 기록한다.
Skip-gram 모델의 적용
새로운 모델 구조 중 하나인 Skip-gram 아키텍쳐를 이 문제에 적용하여 성능을 평가한다.
- Skip-gram 모델은 (50M 단어) 데이터 세트로 훈련되었으며 640차원의 단어 벡터를 사용했다.
- 테스트 세트의 각 문장에 대해, 누락된 단어를 입력으로 사용하고 해당 문장의 주변 단어들을 모두 예측함으로 점수를 계산한다.
Result
- Skip-gram 모델을 단독으로 사용했을 때에는 48%로, LSA similarity보다 더 나은 성능을 보이지 못했다. → Skip-gram 모델에서 얻은 점수는 RNNLM에서 얻은 점수와 상호 보완적인 것으로 나타난다.
- Skip-gram 점수와 RNNLM점수를 가중 조합한 결과, 58.9%라는 새로운 최고 성능을 달성했다.
5. Examples of Learned Relationships
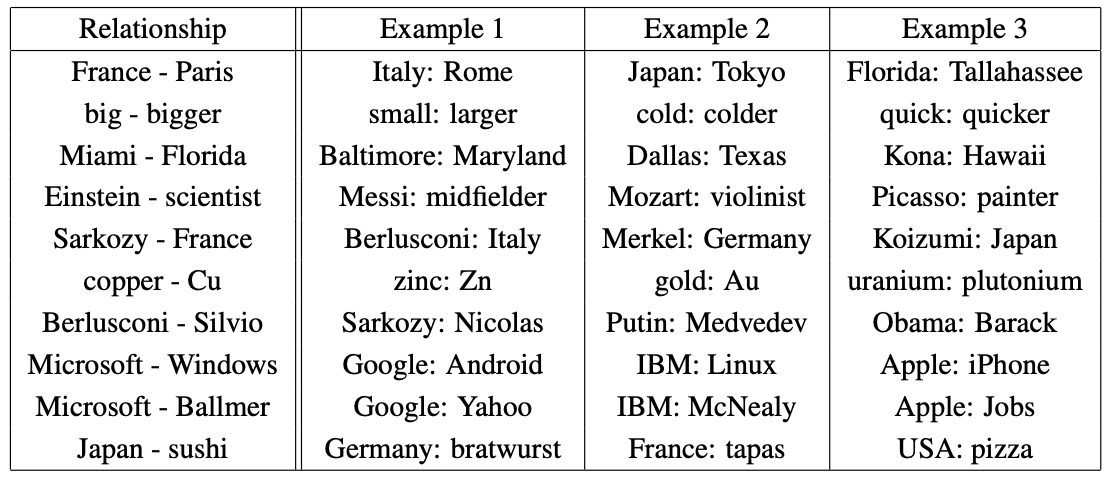
Skip-gram 모델을 사용했을 때 학습된 관계의 예시들이 [Table 8]에 나온다.
- 지리적 관계 (수도) : France - Paris + Italy Rome
- 비교급 : big - bigger + small larger
- 위치적 관계 (도시-주) : Miami - Florida + Baltimore Maryland
- 직업/역할 : Einstein - scientist + Messi midfilder
- 인물-국가 : Sarkozy - France + Berlusconi Italy
이러한 결과는 단순한 단어 유사성을 넘어서, 단어 벡터가 복잡한 선형 규칙성(Linear Regularities)를 포착하고 있음을 보여주며, 이는 기계번역, 정보 검색 등 향후 NLP 애플리케이션의 중요한 구성 요소가 될 것으로 예상된다.
6. Conclusion
인기 있는 신경망 모델 (Feedforward 및 순환)에 비해 매우 간단한 모델 아키텍쳐를 사용하여 고품질 단어 벡터를 훈련할 수 있음을 관찰했다.
DistBelief 분산 프레임워크를 사용하면 기본적으로 무제한의 어휘 크기를 위해 1조 개의 단어가 포함된 말뭉치에서도 CBOW 및 skip-gram 모델을 훈련할 수 있어야 하는데, 이는 유사한 모델에 대해 이전에 발표된 최상의 결과보다 몇 배 더 큰 규모이다.
