Background
최근, chatbot의 개발 및 릴리즈에 상당한 추진이 있었다. Chracter.ai의 chatbot에서 ChatGPT, Bard까지, 채팅을 이용해 봇을 튜닝하는 유저들의 경험은 매우 뜨거운 주제가 되었다. 이러한 뜨거운 관심에 오픈소스의 출현과 오픈소스 대체제가 등장함으로써 기름을 붓는 상황이 되었다.
The Current Environment of Open Source Chatbots
위의 chat모델의 성공에는 두 가지의 비결이 존재한다: 1) instruction finetuning 2) Reinforcement Learning through human feedback (RLHF). 그 동안 앞서 제시한 모델들을 학습시키기 쉽게 만드는 수 많은 오픈 소스 프레임워크(trlX, trl, DeepSpeed Chat and ColossalAI)를 제작하는 노력이 있었으나 두 패러다임을 적용시킬 수 있는 open access, open source 모델들이 부족해 왔었다.
그리고 최근, Open Assistant, Anthropic, and Stanford에서 즉시 사용가능한 public RLHF 데이터셋을 만들기 시작했다. 이 데이터셋들은 trlX에서 제공하는 RLHF의 간단한 training과 결합되어 여기서 소개하는 최초의 large-scale instruction finetuned, RLHF model인 Stable Vicuna의 중추이다.
Introducing the First Large-Scale Open Source RLHF LLM Chatbot
StableVicuna는 LLaMA 13b 모델에 instruction finetune을 진행한 Vicuna v0 13b에 추가적인 instruction finetuning과 RLHF를 진행한 모델이다.
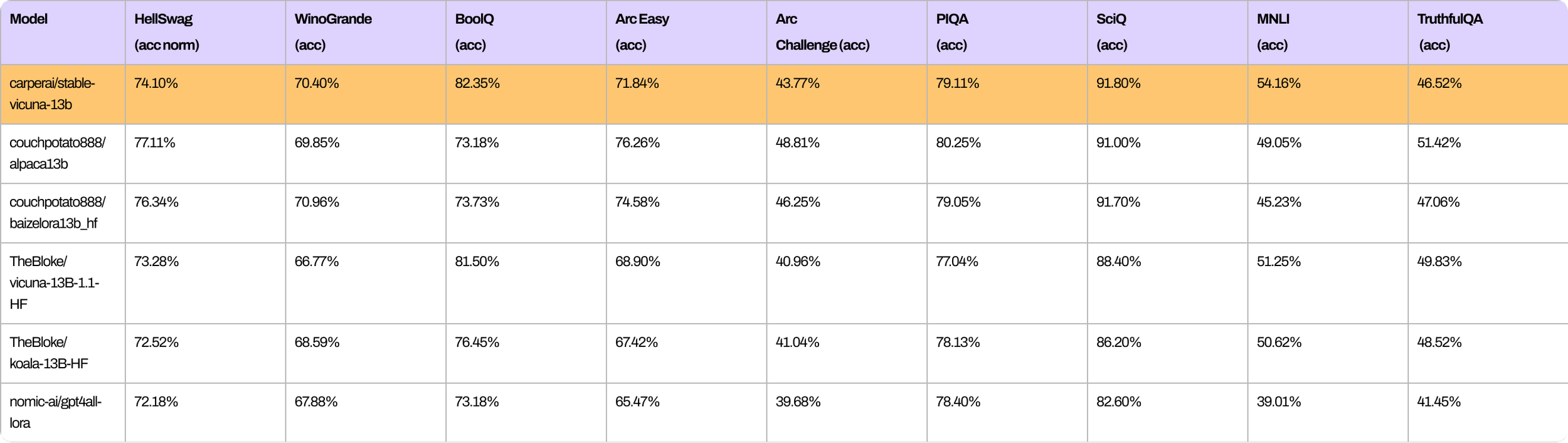
위 표는 StableVicuna와 비슷한 크기의 open source chatbot들의 성능을 StableVicuna와 비교한 자료이다(StableVicuna의 강력한 성능을 확인할 수 있다).
StableVicuna의 강력한 성능을 위해, Vicuna를 base model로 삼고, 전형적인 3단계의 RLHF pipeline을 수행했다(https://arxiv.org/abs/2009.01325, https://arxiv.org/pdf/2203.02155.pdf 에 의해 요약되었다).
구체적으로, base Vicuna를 3개의 데이터셋을 혼합하여 supervised finetuning(SFT)을 진행했다.
-
OpenAssistant Conversations Dataset (OASST1)
사람이 생성 및 주석을 단 assistant 스타일 데이터셋으로, 35개의 언어로 된 66,497개의 대화 트리로 나뉘어 있으며 총 161,443개의 대화를 포함하고 있다.
-
GPT4All Prompt Generations
GPT-3.5 turbo를 이용해 생성된 437,605개의 prompt-response 쌍을 가지고 있는 데이터셋.
-
Alpaca
text-davinci-003엔진으로 생성된 52,000개의 instruction-demonstraition을 가지고 있는 데이터셋.
먼저, trlX를 통해 아래 RLHF 선호도(preference) 데이터셋을 사용해 STF모델에서 가장 최초로 초기화되는 점수 모델을 학습시킨다.
-
OpenAssistant Conversations Dataset (OASST1)
해당 데이터셋은 7213개의 preference 예제를 포함하고 있다.
-
Anthropic HH-RLHF
AI assistant가 도움이 되었는지, 유해한 결과를 내보냈는지에 관한 데이터셋으로 160,800개의 human-labeled 데이터를 가지고 있다.
-
Stanford Human Preferences (SHP)
요리에서 철학에 이르기까지 18개의 서로 다른 주제 영역에서 questions/instructions에 대한 응답에 대한 348,718개의 집단적 human preference 데이터 세트다.
최종적으로, StableVicuna에 도달하기 위해 SFT모델에 RLHF를 적용을 trlX로 PPO(Proximal Policy Optimization) reinforcement learning을 수행한다.
