- Objective
- introduces error type, redundancy, 오류 감지 및 수정
- block coding
- block coding 을 사용하여 error 를 감지하는 방법
- Hamming distance 개념
- cyclic codes
- CRC 설명
- 하드웨어에서 CRC를 쉽게 구현하고 다항식으로 표현하는 방법
- checksums
- 데이터 단어 집합에 대한 체크섬 계산방식
- 전통적인 체크섬에 대한 몇 가지 다른 접근 방식 제공
- forward error correction
1) introduces error type, redundancy, 오류 감지 및 수정
- types of errors
1) single-bit error : 1개의 bit 에서만 error
2) burst error : 2개 이상의 bit 에서 error
- redundancy : error 를 감지하거나 수저하기 위해 보내는 몇 가지 추가 정보
-> 이 추가정보가 길면 좋지 않음. ( overhead 가 커짐. )
- Detection and Correction
1) Detection : error 가 있다 / 없다 판별
2) Correction : error 가 있고 && 어디에 있는지, 몇 bit 인지 알아야 함.
- 따라서 Correction 이 Detection 보다 더 어려움.
2) Block coding
- datawords : message 를 각각 k bit 의 block 으로 나눈다.
- codewords :
각 block 에 r redundant bit 를 추가하여 길이가 ( k + r ) 인 block 을 생성.
- block coding 을 사용한 오류 감지
- dataword를 어떠한 Generator 를 사용하여 codeword로 변환
- codeword 를 받아 어떠한 Checker 를 사용해 Extract 할지 discard 할지 판별
- [ checker 의 판별 기준 ]
- receiver 는 valid codewords 의 list 를 가지고 있음.
- 받은 codewords 가 유효하지 않음을 list 에 대조해 판별
- Simple Parity bit : 1의 개수를 짝수로 만들기 위해 0 or 1을 붙임.
- 홀수개의 bit에서의 error 탐지 가능.
- 짝수개의 bit에서의 error 탐지 불가.
3) cyclic codes
- 어떠한 값으로 나눈 나머지를 붙여 message send 후 checker 를 통해 판별
- 순환코드의 장점
1) good performance in detecting
- single-bit errors
- double errors
- an odd number of errors
- burst errors.
2) 하드웨어 및 소프트웨어에서 쉽게 구현할 수 있음.
3) 특히 하드웨어에서 구현될 때 빠르다.

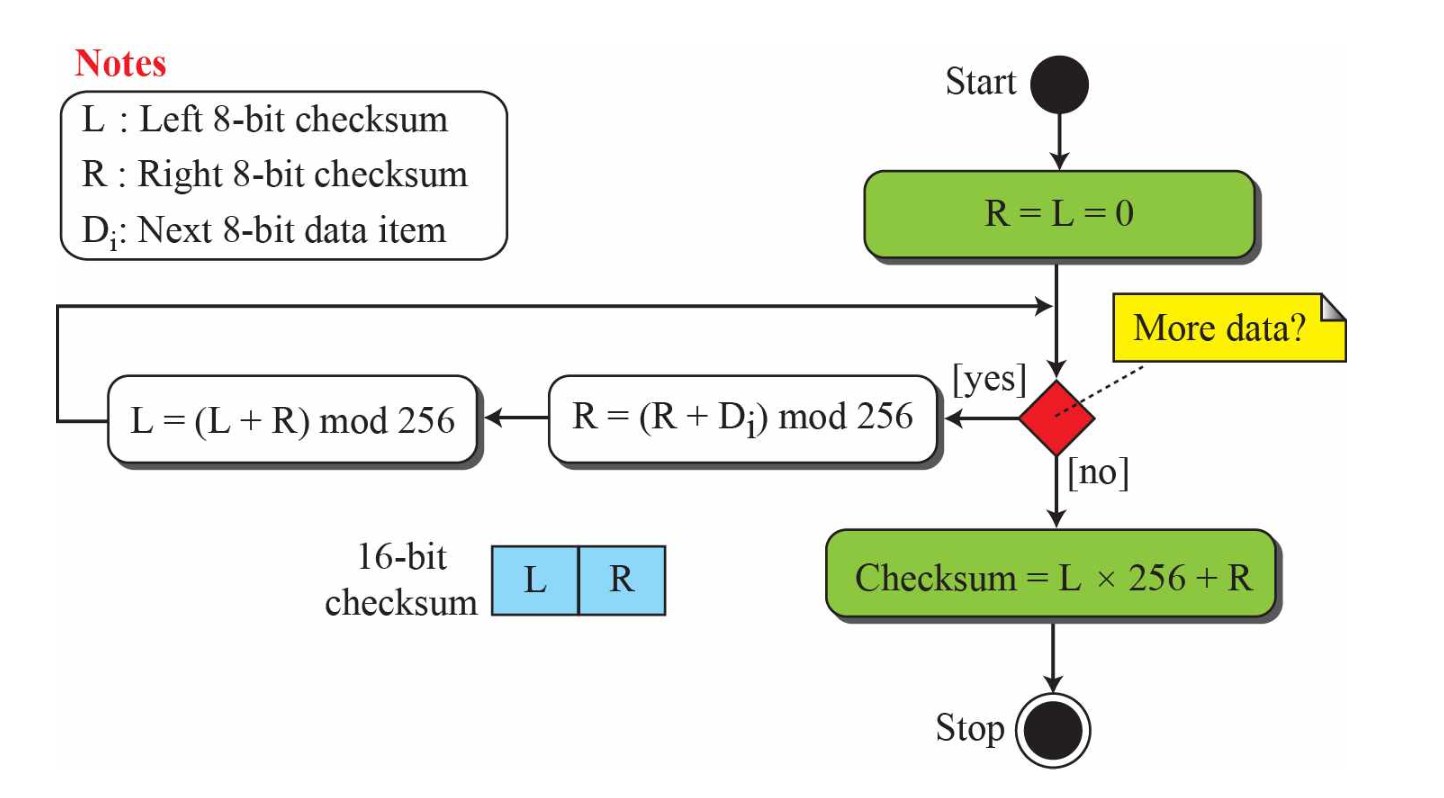
4) Checksums
- 모든 길이의 메시지에 적용할 수 있는 error-detecting technique
- checksum 은 data-link layer 가 아닌 network layer 에서 주로 사용됨.
- 보내는 message 각각의 bit 값들을 더한 값을 뒤에 추가해 message 전송.
- 이 뒤의 sum 을 비교해 오류를 확인.
- 하지만 이 방법은 각각의 bit 들의 순서를 고려하지 못한다는 단점 존재.
-> 1,3,2,4 ( 합계 : 10 ) == 1,2,3,4 ( 합계 : 10 )
- 순서를 고려못하는 단점을 보완하기 위해 나온 checksum : Fletcher's
- 앞, 뒤를 연관시켜놓으면 순서 고려 가능
-> 모든 것들이 서로에게 영향을 주기 때문에 순서가 바뀌면 값이 바뀜.