A review of dialogue systems: current trends and future directions 리뷰 (ODD 위주)
Dialogue System

논문
AI를 공부하기로 한 이상, AI에는 다양한 분야가 있음을 인지하고, 내가 그 중에서 어떤 분야에 대해 깊게 공부해 볼 것인지를 필연적으로 선택해야 하는 시점이 찾아오게 된다.
이러한 과정에서 내가 AI를 공부하고 싶어했던 근본적인 이유를 다시 되돌아보고 이와 관련한 분야를 검색해보니 NLP(Natural Language Processing) 중에서도 Dialogue System이 있었다.
옛날부터 사람과 대화하는 AI를 꿈꿔왔던 나에게 있어서는 굉장히 흥미로운 분야라고 느꼈고, 본 리뷰 논문을 통해 이 분야를 조금 얕게 알아보고자 한다.
미리 선언하지만, 조금 아래에 나올 TOD 보다는 ODD에 더 흥미가 크기 때문에, 리뷰라고는 하지만 ODD를 위주로 정리할 예정이다.
Introduction
-
Dialogue Systems는 chatbots, conversational systems/agents으로도 불린다. (이후에 논문 survey할 때 도움 될 듯.)
-
Dialogue System은 목적에 따라 TOD(Task-Orienged Dialogue System)와 ODD(Open-Domained Dialogue System)로 나뉘어진다.
-
TOD는 closed-domain setting에서 user가 특정한 행동을 취하거나 목적을 달성할 수 있도록 돕는 것을 말한다.
-
반면, ODD는 open-domain setting에서 entertainment를 주 목적으로 하며, user의 발화에 대해 문맥적으로 관련이 깊은 말을 함으로써 user의 참여도를 향상시키는 것을 말한다.
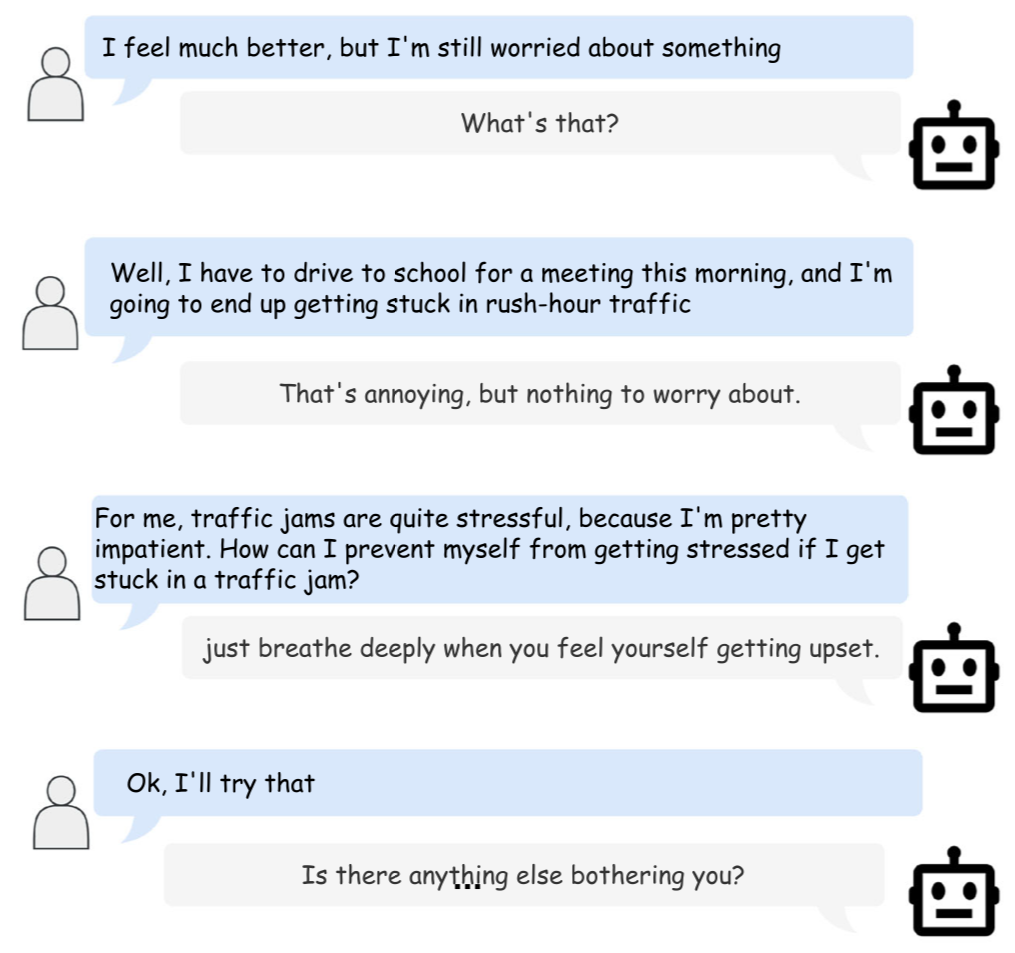 (ODD의 예시이다.)
(ODD의 예시이다.) -
Dialogue System은 user가 하는 말을 이해할 필요가 있고, 관련있거나 정확한 응답을 제공하기 위해 그 말이 어떠한 유형인지 알아볼 필요가 있다. (TOD, ODD 모두 해당)
-
user는 한 번의 발화에 여러 가지를 요청할 수도 있고, 목표 달성을 위해 질문을 할 수도 있다. (A도 해주고 B도 해줘. C를 하려면 어떻게 해야돼?)
-
사람과 사람 간의 대화를 모방하려면 user의 행동과 대화 내역이 다 필요하다.
본 논문의 목적은 다음과 같다.
- To review current approaches, data sets, evaluation metrics and platforms used for dialogue systems.
- To perform an in-depth analysis of reinforcement learning-based approaches.
- To identify gaps and future directions in the research on dialogue systems.
또한, 이러한 목적을 달성하기 위해 발생하는 Research Questions는 다음과 같다.
- What approaches are used in the two different types of dialogue systems?
- What data sets and data set domains are used to develop dialogue systems?
- What evaluation metrics are used to assess dialogue systems?
- What attempts have been made to interleave ODD with TOD?
- How is RL applied to dialogue systems?
- What are the gaps in the researsh on dialogue systems?
일단 이렇게 적기는 했는데, 결국은 ODD가 위주일 것이다.
본 논문을 읽으면서 자주 나오는데 뜻을 잘 몰랐던 단어들이 있어, 논문을 정리하는 과정에서 나올 때 마다 잠깐씩 등장할 예정.
interleave: 끼워넣다.
Background
Dialogue System의 main component는 다음과 같다.
- Natural Language Understanding (NLU)
- Dialogue Manager (DM)
- Natural Language Generation (NLG)
이제 이것들을 하나씩 살펴보자.
Natural Language Understanding
- NLU는 user의 발화의 Semantics(의미론적 요소)를 파악하는 것이 핵심이다.
- 이러한 Semantics는 종종 데이터셋에서 dialogue acts로써 등장한다.
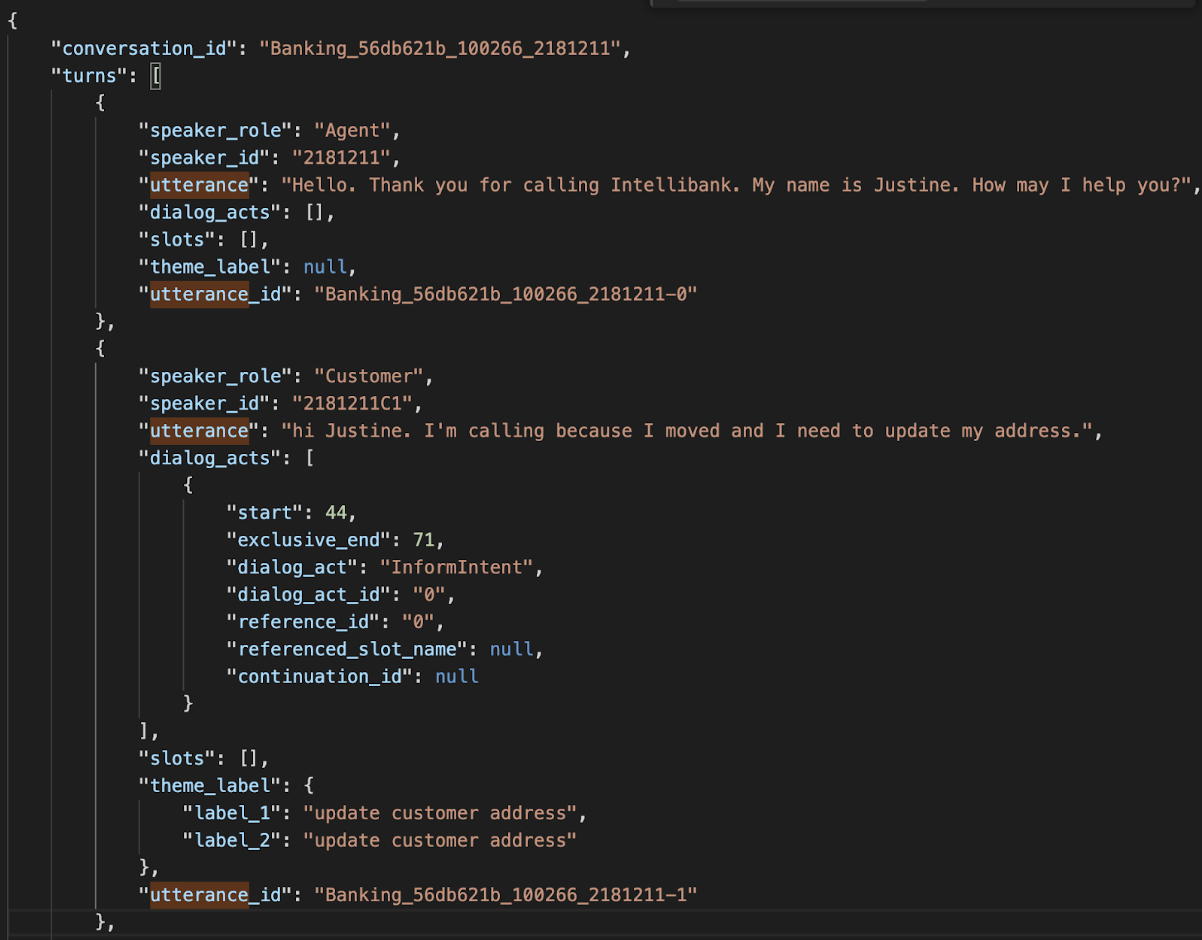 프로젝트가 끝나면 정리할 DSTC12인데, 해당 Track에서도 dialogue_acts로써 의미론적 요소가 들어가 있다.
프로젝트가 끝나면 정리할 DSTC12인데, 해당 Track에서도 dialogue_acts로써 의미론적 요소가 들어가 있다. - NLU module은 특정한 턴에 포함된 중요한 정보를 추출하는 것을 목적으로 한다.
NLU는 두 가지 core task가 있다.
- Intent Classification (IC)
- Slot Filling (SF)
IC는 classification task로 취급되고, SF는 sequence-labelling task로 취급된다.
Dialogue Manager
-
DM은 user와 system 사이의 상호작용을 관리하는 중요한 요소이다.
-
TOD에서는 DM이 주로 DST(Dialogue State Tracker), Dialogue Policy로 이루어져 있다.
-
DST는 각 turn에서 Dialogue의 input, history를 추적하여 현재의 Dialogue State를 결정하는 역할을 한다.
-
Dialogue Policy는 System의 Action을 선택해야 하기 때문에, Dialogue State의 영향을 크게 받는 편이다.
Natural Language Generation
- Dialogue Policy가 Action을 선택하고 나면, NLG module은 user가 이해할 수 있는 언어로 Semantic Representation에서 Response로 mapping을 진행한다.
Dialogue System은 Response를 어떻게 Generation하는가에 따라 세 가지로 분류가 된다.
- Retrieval-Based Systems
- Generative Systems
- Hybrid Systems
Retrieval-Based Systems
-
얘는 미리 정해진 답변 형식, 또는 미리 수집된 human conversations repository에서 답변을 도출하는 형식이다.
-
High-Quality, Grammatically Correct, Fluent Response를 보장하지만, Repository 안에 없는 응답은 할 수 없다.
Generative Systems
-
주로 Auto-Regressive Model이 사용되어, 이전의 단어 생성을 참고해가며 계속해서 단어를 생성해낸다.
-
seq2seq같은 Neural Generative Model이 주로 사용된다.
-
data set에 존재하지 않는 응답을 낸다는 장점이 있지만 문법적으로 옳지 않거나, 관계가 없는 응답을 낼 수 있다는 단점이 있다.
Hybrid Systems
- Retrieval-Based와 Generative의 장점을 각각 합치자는 의미에서 나온 방법으로, Repository에서 먼저 응답을 찾은 다음, Generative로 정제 과정을 거쳐 답변을 만들어낸다.
Current Approaches in Dialogue Systems
이전의 Research Questions의 첫 번째 질문은 다음과 같았다.
"What approaches are used in the two different types of dialogue systems?"
Dialogue Systems는 우선 modular(= pipeline)이나 end-to-end 방식으로 발전해왔다.
-
modular는 framework의 각 component를 각각 학습시킴으로써, interpretability, stability 측면에서 장점이 있다.
-
end-to-end는 모든 component를 한 번에 학습시킨다.
-
end-to-end의 이러한 방식은 새로운 domain에 대한 scalability 측면에서 장점이 있고 deployment의 cost가 낮다는 장점이 있다.
Open-Domain Dialogue Systems
앞에서 강조했듯, ODD 위주로 볼 것이다.

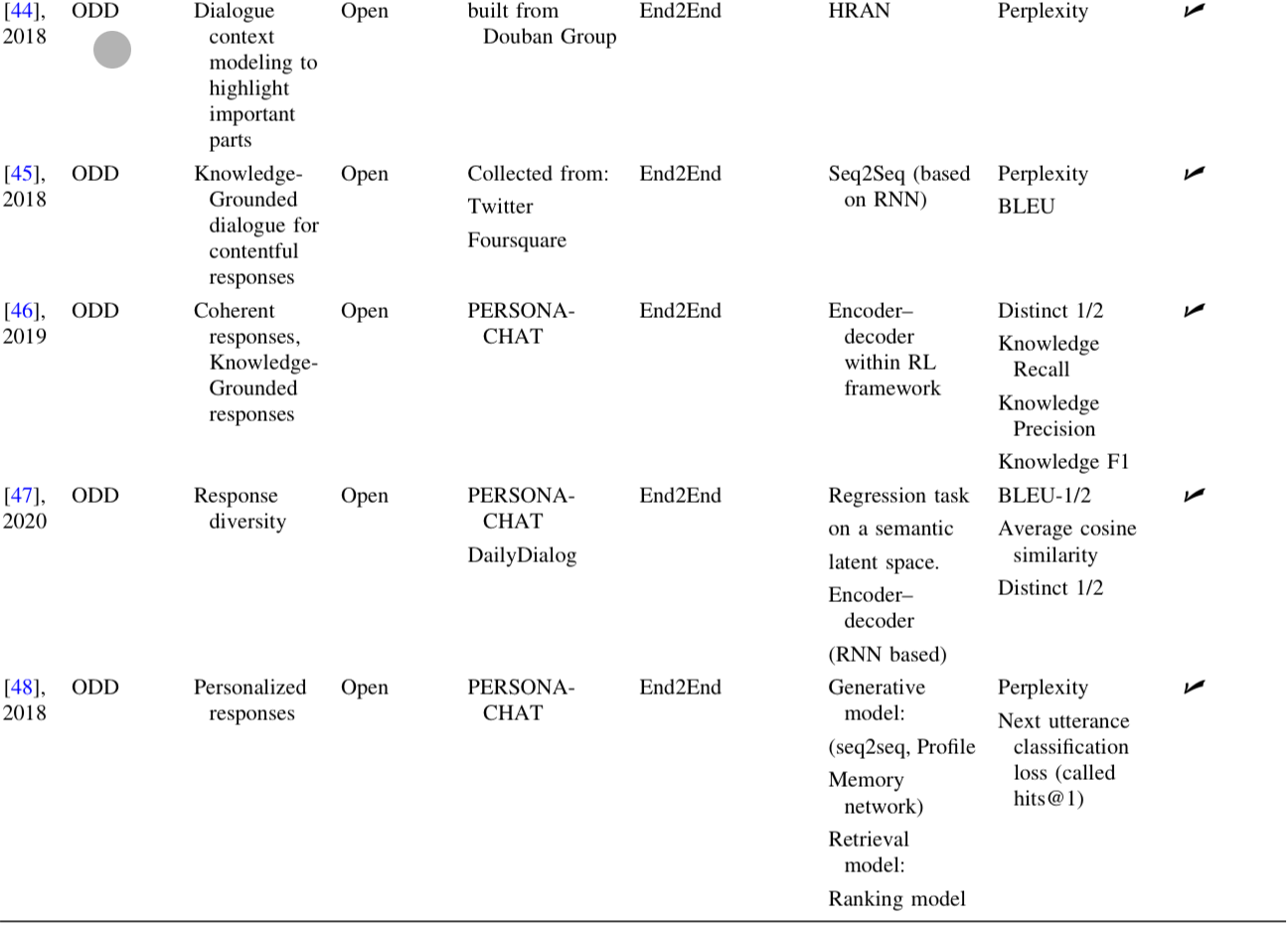
 캡쳐가 예쁘게 되지는 않긴 하는데.. 어쩔 수 없는걸로..
캡쳐가 예쁘게 되지는 않긴 하는데.. 어쩔 수 없는걸로..
아무튼 표를 보면 알 수 있듯, ODD System에 대해서는 모든 연구들이 end-to-end 방식의 접근을 사용하였다.
앞서 설명한 것 처럼, ODD 방식은 user의 참여도를 높이는 것을 주 목적으로 하고 있으며, Dialogue Skill의 향상을 통해 이루어진다.
Skill은 흥미로운 주제에 대해 얘기를 하는 것, 정서적인 공감을 하는 것 등으로 이루어져 있다.
표를 통해 ODD-Related Research Problem을 알 수 있다.
Dialogue System Modeling
-
Context Awareness는 user의 Current Message와 Dialogue History를 포함한다.
-
Dialogue History에서 중요한 부분에 집중할 수 있게 Hierarchical Neural Network에 Attention Mechanism을 도입하는 등의 시도가 있었다.
Knowledge-Grounded Dialogue Systems
-
Knowledge에 기반한 ODD System은 user의 input에서 entities와 topics를 recognize해야 한다.
-
이 분야에서의 주 연구 주제는 ODD System에 Real-World Facts를 어떻게 주입시킬지 이다.
ground: AI에게 정보를 제공하다.
Response Coherence and Diversity
-
Coherence는 Dialogue 내에서 Logic과 Consistency를 보존하는 능력이며, ODD System에서 중요한 요소이다.
-
Diversity 측면에서의 문제점은 Data set에서 "It's OK.", "I don't know." 처럼 너무 빈번하게 등장하는 응답이 존재한다는 점이다.
Personality-Based Responses
-
몰입감 있는, 개인의 성향에 맞춘 Dialogue System을 통해 Response의 Quality를 향상시킬 수 있다.
-
Persona Information을 넣기 위해 Transformer-Based Model에 새로 Embedding Layer를 추가하는 연구도 존재한다.
-
Automatic and Human Evaluations는 fine-tuning보다 Computational Resources가 훨씬 낮은 prompt-tuning을 통해 Personalized Dialogue System을 만들어내는데 성공했다.
Empathetic Responses
-
감정을 인식하는 것, 그에 따라 적절하게 반응하는 것은 중요한 Conversational Skill이다.
-
이걸 시도한 논문은 꽤 있었지만, Natural Language로 복잡한 감정을 표현하는 것과 대화의 흐름에서 user의 감정 변화를 detecting하는 것은 여전히 중요한 도전 과제로 남아있다.
Datasets and Domains
Research Question의 두 번째 질문은 다음과 같았다.
"What data sets and data set domains are used to develop dialogue systems?"
ODD System을 developing하는 데에는 주로 PERSONA-CHAT과 DailyDialog 라는 Dataset을 사용한다.
추가적으로, TOD에는 MultiWOZ 라는 Dataset이 주로 사용된다고 한다.
PERSONA-CHAT
-
Main Purpose는 Dialogue System에 Personality를 더하는 것이다.
-
1,155개의 persona가 있으며, 각 persona는 적어도 5개의 profile sentence가 있다.
-
2명의 crowdsourced worker가 1,155개 중 랜덤으로 persona를 배정받아, 10,907개의 Dialogue를 만들었다. (진짜 고생했네..)
DailyDialog
-
13,118개의 Dialogue로 구성되어 있고, 한 Dialogue에 평균적으로 7.9 turn의 대화가 이루어졌다.
-
Intention, Emotion Information으로 labeling 되어있다.
Evaluation Methods
Research Question의 세 번째 질문이다.
"What evaluation metrics are used to assess dialogue systems?"
Dialogue System의 성능을 어떻게 평가할 것인가?
이 분야에 대한 공부를 시작할 때 제일 처음 가졌던 의문이었던 것 같다.
Evaluation에는 두 가지 주요 접근 방식이 있다.
Automatic Evaluation과 Human Evaluation
근데 이 마저도 애매한게, ODD가 제공할 수 있는 수용 가능한 응답의 범위가 상당히 넓기 때문에, ODD System의 Evaluation은 도전 과제로서 남아있으며 연구가 진행중에 있다.
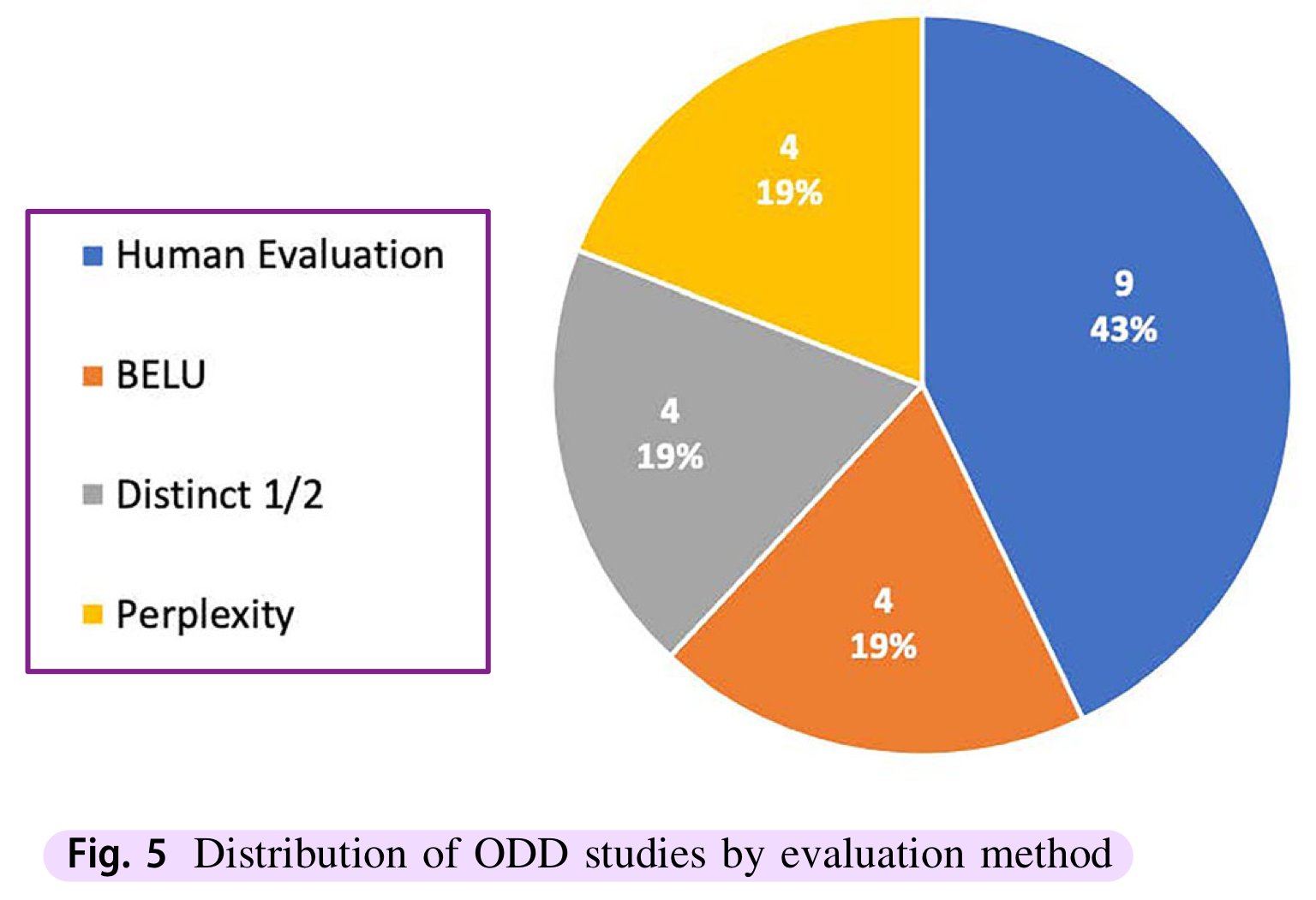 표를 보면 알겠지만, ODD는 주로 Human Evaluation으로 이루어진다. (...)
표를 보면 알겠지만, ODD는 주로 Human Evaluation으로 이루어진다. (...)
BLEU
-
Bilingual Evaluation Understudy의 줄임말로, Generated Responses의 Fluency를 측정한다.
-
Dialogue System이 만든 Candidate Response와 사람이 작성한 Reference Sentence 간의 matching n-grams 개수로 계산한다. (이 때, n은 1에서 4 사이의 값을 주로 사용한다고 한다.)
Perplexity
-
Model이 Human Response를 얼마나 잘 예측하는지를 측정하는 지표이다.
-
Perplexity 값이 낮을수록 성능이 좋다는 걸 나타낸다.
Distinct-1/2
-
Generated Response의 Diversity를 측정하는 지표이다.
-
Distinct Uingrams, Bigrams를 모든 Response에 대해 Total Number of Generated Words로 나눈 값으로 계산한다.
Human Evaluation
-
cost도 높고, 평가 결과도 되게 주관적이다.
-
그럼에도 BLEU 같은 Automatic Evaluation으로는 평가할 수 없는 요소가 분명히 존재하기에, 대부분의 논문은 Automatic Evaluation에 Human Evaluation을 같이 곁들인다.
-
Human Evaluation에도 종류가 존재하는데, 사람에게 직접 Dialogue System과 대화를 해보라고 시킨 뒤 설문지를 작성하는 방식이 있고, platform을 통해 crowdsourcing worker들에게 평가를 맡기는 방법이다. (다수의 의견을 받는 것.)
사실 이 뒤에도 흥미로운 내용들 자체는 꽤 있지만, 거의 Reinforcement Learning (RL)에 관한 내용들 위주라 ODD 관련 정리는 여기까지 하도록 하자..
이제 본 리뷰 논문에서 reference로 사용한 논문들도 차근차근 읽어보면 뭔가 공부가 되지 않을까 싶다.
[3] DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset
(https://arxiv.org/abs/1710.03957)
[15] Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey
(https://arxiv.org/abs/2105.04387)
[44] Hierarchical Recurrent Attention Network for Response Generation
(https://arxiv.org/abs/1701.07149)
[45] A Knowledge-Grounded Neural Conversation Model
(https://arxiv.org/abs/1702.01932)
[46] Know More about Each Other: Evolving Dialogue Strategy via Compound Assessment
(https://arxiv.org/abs/1906.00549)
[47] Generating Dialogue Responses from a Semantic Latent Space
(https://arxiv.org/abs/2010.01658)
[48] Personalizing Dialogue Agents: I have a dog, do you have pets too?
(https://arxiv.org/abs/1801.07243)
[49] Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory
(https://arxiv.org/abs/1704.01074)
[50] Transformer-based Empathetic Response Generation Using Dialogue Situation and Advanced-Level Definition of Empathy
(https://ieeexplore.ieee.org/document/9362067)
[51] Grounding in social media: An approach to building a chit-chat dialogue model
(https://arxiv.org/abs/2206.05696)
[52] Building a Personalized Dialogue System with Prompt-Tuning
(https://arxiv.org/abs/2206.05399)
