
학습할 것 (필수)
- 자바에서 예외 처리 방법 (try, catch, throw, throws, finally)
- 자바가 제공하는 예외 계층 구조
- Exception과 Error의 차이는?
- RuntimeException과 RE가 아닌 것의 차이는?
- 커스텀한 예외 만드는 방법
참고자료
예외처리에 대해 학습하기 전에, 근본적으로 예외처리(Exception)이 가져다주는 이점이 무엇인지 알아보자
(아래 코드들은 자바 공식문서에서 참조한 코드입니다.)
-
에러처리를 위한 코드를 일반 코드와 분리시킨다.
왜 분리시켜야 할까? 다음 예제를 보면 가슴 깊이 와닿을 수 있다.
readFile { open the file; determine its size; allocate that much memory; read the file into memory; close the file; }위 코드는 파일을 읽는
psedocode이다. 간단해 보이지만, 위 코드에는 문제가 있다.- 만약, 파일이 열리지 않는다면?
- 만약, 파일의 사이즈를 알아낼 수 없다면?
- 만약, 충분한 메모리를 할당할 수 없다면?
- 만약, 파일 메모리를 읽는 것에 실패한다면?
- 만약, 파일을 닫을 수 없다면?
정상적으로 작동하는 프로그램을 개발하기 위해, 예상되는 문제들에 대한 대응책을 마련해야 한다. 위 문제들은, 시스템 레벨에서 발생하는 문제이기 때문에 응용 프로그래머가 관리할 수 있는 문제가 아니다. 따라서 다음과 같이 에러를 처리해야 한다.
errorCodeType readFile { initialize errorCode = 0; open the file; if (theFileIsOpen) { determine the length of the file; if (gotTheFileLength) { allocate that much memory; if (gotEnoughMemory) { read the file into memory; if (readFailed) { errorCode = -1; } } else { errorCode = -2; } } else { errorCode = -3; } close the file; if (theFileDidntClose && errorCode == 0) { errorCode = -4; } else { errorCode = errorCode and -4; } } else { errorCode = -5; } return errorCode; }
당장은 에러를 잡아내서 처리할 수 있겠지만, 시간이 지난 뒤 위와 같은 스파게티 코드를 만나게 되는 것은 끔찍한 일이다. 따라서, 메인 로직이 수행되는 코드와 에러를 처리하는 코드를 분리해야 한다.
readFile {
try {
open the file;
determine its size;
allocate that much memory;
read the file into memory;
close the file;
} catch (fileOpenFailed) {
doSomething;
} catch (sizeDeterminationFailed) {
doSomething;
} catch (memoryAllocationFailed) {
doSomething;
} catch (readFailed) {
doSomething;
} catch (fileCloseFailed) {
doSomething;
}
}위와 같이 try, catch 구문을 추가함으로써 메인 로직 코드에 영향을 주지 않으면서, 에러를 처리할 수 있다. 당장은 exception 처리하는 코드를 분리하는 게 귀찮을 수 있지만, 추후 일 처리에 도움을 주기 때문에 반드시 구분해야 놓아야 한다.
-
에러를 콜 스택 위로 전파한다.
method1 { call method2; } method2 { call method3; } method3 { call readFile; }위 코드에서
readFile의 에러를 처리는method1에서 담당하고 있다. 따라서,readFile에서 에러가 발생한다면call stack을 거쳐method1까지 에러를 전달해야 한다. 따라서 아래와 같이 코드가 수정되어야 한다.method1 { errorCodeType error; error = call method2; if (error) doErrorProcessing; else proceed; } errorCodeType method2 { errorCodeType error; error = call method3; if (error) return error; else proceed; } errorCodeType method3 { errorCodeType error; error = call readFile; if (error) return error; else proceed; }하지만, 이 경우
method3와method2에서 코드가 중복된다는 단점이 있다. 또한,call stack이 깊어질 수록 중복되는 코드는 증가할 것이다.method1 { try { call method2; } catch (exception e) { doErrorProcessing; } } method2 throws exception { call method3; } method3 throws exception { call readFile; }try,catch구문을 통해 중복된 코드들을 줄일 수 있다.call stack위로 에러를 전달하는 메소드는throws키워드만 명시해두면 에러 발생 시, 자동으로 에러를call stack위로 전달한다. -
에러의 타입을 그룹화하고 구분지을 수 있다.
프로그램에서 발생한 모든
Exception은 객체이기 때문에, class의 계층구조와 동일하게Exception도 그룹화된다. 따라서 계층구조에서의 이점을 예외 처리에서도 적용시킬 수 있다.
Exception이란?
정의 : 프로그램 명령들의 정상적인 흐름을 방해하는 것이며, 프로그램이 동작하는 중에 발생하는 이벤트를 말한다.
메소드 내에서 오류가 발생하면, 메소드는 객체를 만들어 이를 런타임 시스템에게 전달한다. Exception Object라고 불리는 객체는 타입과 그것이 발생했을 때의 프로그램 상태를 포함하고 있는 ‘오류에 관한 정보’를 담고 있다.
Exception 객체를 생성하고 이를 런타임 시스템에 보내는 것을 throwing an exception이라고 말한다.
Exception이 처리되는 과정
메소드가 exception을 던진이후, 런타임 시스템은 해당 exception을 다루는 대상을 찾으려 한다. exception을 처리할 가능성이 있는 대상들의 집합은 오류가 발생한 메소드로 이동하기 위해 호출된 메소드의 순서 목록이다. 이러한 메소드의 목록을 call stack이라고 한다.
콜 스택

런타임 시스템은 exception을 처리하는 코드 블락을 포함하고 있는 메소드를 찾기 위해 call stack을 조사한다. 이러한 코드 블락을 exception handler라고 부른다. 조사는 오류가 발생한 메소드에서 시작되며 call stack을 따라 메소드를 호출했던 메소드로 역 순서로 진행된다. 적절한 handler를 찾았다면, 런타임 시스템은 handler에게 exception을 전달한다. 만약 exception 객체와 handler가 다루는 exception type이 일치할 경우, 해당 handler는 적절하다고 여겨진다.
exception handler가 선택된 것을 보고 catch the exception이라고 말한다. 런타임 시스템이 call stack을 모두 조사했는데도 적절한 exception handler를 찾지 못했다면, 런타임 시스템은 종료된다.
exception handler를 찾기 위해 조사하는 과정

Catch 또는 Specify 요구사항
잘 만들어진 자바 프로그램이라면 Catch or Specify에 대한 요구사항을 충족시켜야 한다. 이 말은, exception을 throw할 수 있는 코드는 반드시 아래 요소들에 둘러쌓여야 한다는 의미이다.
exception을catch하는try문.try는 반드시exception을 처리하는handler를 제공해야 한다.- 메소드는
exception을throw할 수 있음을 명시해야 한다. 메소든는throws키워드를 통해exception리스트를 제공할 수 있다.
위의 요구사항을 충족시키지 못하는 코드는 컴파일 되지 않는다. 그러나, 모든 exception들이 Catch or Specify 요구사항의 대상이 되는 것은 아니다. 이러한 이유를 알기 위해서 exception의 기본 세 가지 기본 카테고리를 알아야 한다. 셋 중 하나만 요구사항의 대상이 된다.
The Three kinds of Exceptions
exception의 첫 번째 종류는 the checked exception이다. checked exception은 잘 만들어진 어플리케이션이 반드시 예상하고 대응해야 하는 예외적인 상황들을 말한다.
java.io.FileReader를 예시로 들겠다. 사용자로 부터 파일의 이름을 입력받아 해당 파일을 읽어들이는 프로그램이 있다. 만약, 사용자가 존재하지 않는 파일 이름을 입력할 경우, FileReader의 생성자는 java.io.FileNotFoundException을 throw할 것이다. 잘 만들어진 프로그램이라면, 위 exception을 catch한 뒤 적절한 대응을 해야한다.
위 예시처럼, checked exception은 Catch or Specify 요구사항의 대상이 된다. Error와 RuntimeException을 제외하고 모든 Exception들은 checked exception이다.
exception의 두 번째 종류는 error이다. 이 exception은 어플리케이션의 외부에서 발생하는 예외적이 상황을 말하며, 해당 어플리케이션은 보통 이를 예상하지 못하며 대응하지 못한다. 예를 들어, 어플리케이션이 성공적으로 파일을 열었다고 하자. 하지만, 하드웨어나 시스템의 문제로 인해 파일을 읽는 것이 거부될 수 있다. 이러한 상황에서 java.io.IOError가 throw될 것이다. 어플리케이션은 이러한 문제를 사용자에게 알리기 위해, 해당 exception을 catch할 지 결정해야 한다. 그러나 프로그램에서 stack trace를 출력하고 종료되는 것또한 타당한 방법이다. error는 catch or specify 요구사항의 대상이 아니다.
exception의 세 번째 종류는 runtime exception이다. 이 exception은 어플리케이션 내부에서 발생하지만, 어플리케이션이 예상하거나 대응할 수 없는 예외적인 상황을 말한다. 이에 대해 보통 프로그래밍 버그라고 여겨진다. 예를 들어, 정상적인 파일명을 사용자에게 입력받았지만, 내부 로직 오류로 인해 null을 FileReader 생성자에 넣었다고 하자. 해당 생성자는 NullPointerException을 throw할 것이다. 어플리케이션은 이 exception을 catch할 수 있지만, 애초에 버그를 제거하는 것이 더 옳은 방법이다.
자바에서 예외 처리 방법(try, catch, throw, throws, finally)
The try Block
exception handler를 만들기 위한 첫 단계는 exception을 throw하는 코드를 try 블럭으로 감싸는 것이다.
try{
code
}
catch and finally bloacks ...code 에서 exception을 throw하는 것을 try 블럭에서 알아차릴 수 있다. 다만, catch 블럭이 없다면 아무런 효과가 없게 된다.
public class ThrowTest {
void throwException(){
try{
throw new IOException();
}
}
}위 코드를 컴파일 하면, 아래와 같은 컴파일 에러가 발생한다.
java: 'try' without 'catch', 'finally' or resource declarationstry 블럭만 있고, catch 블럭이나 finally 블럭이 없다면 컴파일 되지 않는다.
컴파일되는 상황을 연출하기 위해, catched exception인 IOException을 uncatched exception인 NullPointerException으로 치환하겠다. 그리고 finally 블락을 추가한다.
public class ThrowTest {
void throwException(){
try{
throw new NullPointerException();
}finally {
System.out.println("Throw Exception!");
}
}
}
public class Main {
public static void main(String[] args) {
ThrowTest throwTest = new ThrowTest();
throwTest.throwException();
}
}위 코드의 실행결과는 다음과 같다.
Throw Exception!
Exception in thread "main" java.lang.NullPointerException
at example.ThrowTest.throwException(ThrowTest.java:8)
at example.Main.main(Main.java:8)try 블럭만 있고 exception을 실질적으로 처리하는 catch 블럭이 없기 때문에, 위 메소드에서 exception을 throw하게 된다.
또한, uncatched exception을 throw했기 때문에 컴파일상에서는 문제가 발생하지 않지만, 런타임에서 문제가 발생하게 된다. 만약, catched exception인 IOException이라면 컴파일에서 먼저 오류가 발생할 것이다.
요약하자면, try 블럭만 가지고는 아무런 의미가 읎다.
The catch Blocks
catch 블럭에서는 실질적으로 exception을 잡아내고 처리하는 로직을 담고 있다.
try{
} catch(ExceptionType name){
} catch(ExceptionType name){
}ExceptionType은 handler가 처리할 수 있는 exception의 type을 말한다. 해당 타입은 반드시 Throwable 클래스를 상속받은 클래스의 이름이어야 한다. catch 블럭 내부에는 exception handler가 실행될 때 호출되는 코드들을 포함한다. 런타임 시스템은 throw된 exception의 타입과 일치되는 exception handler를 실행한다.
public class ThrowTest {
void catchException(){
try{
throwIndexOutOfBoundsException();
throwIOException();
}catch (IndexOutOfBoundsException e){
System.out.println("Catch IndexOutOfBoundsException");
}catch (IOException e){
System.out.println("Catch IOException");
}
}
void throwIndexOutOfBoundsException(){
throw new IndexOutOfBoundsException();
}
void throwIOException() throws IOException {
throw new IOException();
}
}
public class Main {
public static void main(String[] args) {
ThrowTest throwTest = new ThrowTest();
throwTest.catchException();
}
}
// 실행결과
// Catch IndexOutOfBoundsException위 코드에서 먼저 IndexOutOfBoundsExceptioin이 throw된다. 해당 Exception을 첫 번째 catch 블럭에서 잡아 출력문을 출력한다. 그런데, IOException을 throw하는 코드가 있음에도 두 번째 catch 블럭의 코드가 실행되지 않고 있다. 이 이유는 try 블럭에서 Exception이 throw되면, 다음 코드를 실행하지 않기 때문이다.
추가적으로, ExceptionType에서도 다형성이 적용된다.
public class ThrowTest {
void catchException(){
try{
throwIndexOutOfBoundsException();
}catch (RuntimeException e){
System.out.println("Catch RunTimeException");
}catch (IndexOutOfBoundsException e){
System.out.println("Catch IndexOutOfBoundsException");
}
}
void throwIndexOutOfBoundsException(){
throw new IndexOutOfBoundsException();
}
}IndexOutOfBoundsException은 RuntimeException을 상속받고 있다. 때문에 두 번째 catch 블럭이 아닌, 첫 번째 catch 블럭에서 IndexOutOfBoundsException을 처리할 것이다. 그런데 사실 위 코드는 애초에 컴파일 되지 않는다.
java: exception java.lang.IndexOutOfBoundsException has already been caught두 번째 catch 블럭은 실행될 일이 없는 불필요한 코드이기 때문에 컴파일되지 않는다.
The finally Block
finally 블럭은 try 블럭이 종료된 이후 항상 실행되는 블럭이다. try 블럭에서 예기치 못한 오류가 발생하더라도 반드시 실행됨을 보장한다. 추가적으로 finally 블럭은 exception handling 이상으로 더 유용하게 사용된다. try 블럭에서 return, continue, break에 의해 cleap up 코드를 지나치게 되더라도 finally 블럭에 clean up 코드를 넣음으로서 이를 해결할 수 있다.
(그러나 try 블럭 또는 catch 블럭이 실행되는 도중 JVM이 종료된다면 finally 블럭은 실행되지 않을 수 있다.)
public class FinallyTest {
void test(){
try{
return;
}finally {
System.out.println("method is returned");
}
}
}
public class Main {
public static void main(String[] args) {
FinallyTest finallyTest = new FinallyTest();
finallyTest.test();
}
}
// 실행결과
// method is returned일반적인 코드라면, return 이후에 코드는 실행되지 않는다. 하지만, finally 블럭을 둠으로써 return을 통해 메소드가 종료되기 직전에 finally 코드가 실행되는 것을 확인할 수 있다.
(굉장히 유용하게 사용될 것 같다!)
throw and throws
위 두 키워드가 헷갈릴 수 있기 때문에 의미를 명확히 하고자 한다.
- throw : 코드 상에서 Exception을 throw할 때 사용
- throws : 메소드가 Exception을 throw한다는 것을 나타내기 위해 메소드에 붙여지는 키워드. 어떤 Exception 리스트를 명시하도록 도와줌.
The try-with-resources Statement
try-with-resources statement는 하나 혹은 여러 개의 리소스를 try 문에 명시해놓은 것이다. 여기서 리소스는 프로그램이 종료된 이후 반드시 close되어야 하는 객체를 말한다. try-with-resources statement는 try문이 종료된 이후 명시된 리소스들이 close되는 것을 보장한다. 여러 리소스에 적용할 때는 세미콜론을 사용한다. 단! Closeable이나 AutoCloseable 인터페이스를 구현한 클래스만 리소스가 될 수 있다.
try-with-resources statement는 일반적인 try 블럭처럼 catch 블럭과 finally 블럭을 추가할 수 있다. 이 경우 명시된 리소스들이 close된 이후 catch 블럭과 finally 블럭이 실행된다.
public class TryWithResourcesTest {
String test(String path) throws IOException {
try(FileReader fr = new FileReader(path);
BufferedReader br = new BufferedReader(fr)){
return br.readLine();
}
}
}위 코드는 FileReader 객체와 BufferedReader 객체가 close되는 것을 보장한다.
그런데, “그냥 finally 블럭에서 처리하면 되지 않아요?”라는 의문이 들 수 있다. 다음 예시를 보자.
public class TryWithResourcesTest {
String test(String path) throws IOException {
FileReader fr = new FileReader(path);
BufferedReader br = new BufferedReader(fr);
try {
return br.readLine();
} finally {
br.close();
fr.close();
}
}
}위 코드도 동일하게 FileReader 객체와 BufferedReader 객체를 close하는 것처럼 보인다. 정상적으로 동작할 때는 그러하지만, 다음 상황을 생각해보자.
br.readLine()에서 Exception을 throw한다면 finally 블럭으로 넘어갈 것이다. 그런데, br.close()에서도 Exception을 throw한다면 fr.close()는 호출되지 않게 된다. 즉, 위 코드는 close를 보장하지 못한다.
그러나! “GC(garbage collector)가 나중에 메모리를 정리하면서 close해주겠죠!”라고 생각할 수 있다. 마찬가지로, 다음 상황을 생각해보자.
GC가 메모리를 정리하기 전에 JVM이 종료된다면 어떻게 될까? close되지 못했던 BufferdReader 객체에 대한 정보가 소실된다. OS에서 해당하는 file을 close하려면 해당 파일에 대한 정보가 필요한데, 그 정보를 더 이상 찾을 수 없기 때문에, OS에서는 해당 파일을 계속 사용하고 있다고 생각할 수 있다. 즉, resource leak이 발생한다.
따라서, 직접 close하려고 하지말고, try-with-resources statement 사용하여 close처리하는 것이 정신 건강에 이로울 것으로 보인다.
자바가 제공하는 예외 계층 구조
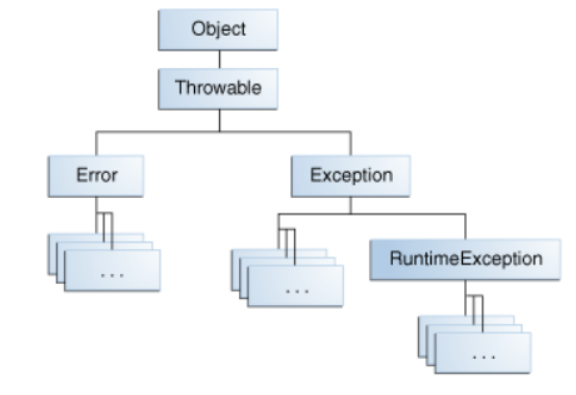
Exception과 Error의 차이는?
- Exception : 어플리케이션 내부에서 발생하는 오류를 나타내는 객체.
- Error Class : JVM에서 동적 링킹이 실패하거나, 하드웨어 적으로 문제가 발생했을 때 JVM은 Error를 throw한다. 즉, 어플리케이션 외부에서 발생한 문제일 때 Error 객체가 throw된다.
RuntimeException과 RE가 아닌 것의 차이는?
- RuntimeException : API를 잘못 사용했을 때 발생하는 Exception. Uncatched Exception.
- RE가 아닌 것 : Catched Exception.
간략한 정의는 위와 같지만, 자바 코드를 짜면서 바로 알 수 있다.
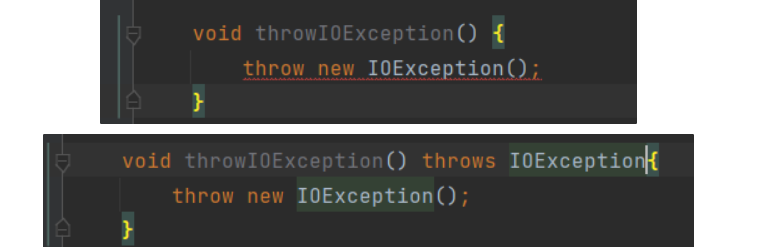
IOException은 RE가 아닌, catched exception이다. catch 또는 specify 요구사항이 적용되는 대상이다. 따라서, 해당 처리를 수행하지 않으면 컴파일 되지 않는다.

그에 반해, IndexOutOfBoundsException은 RuntimeException이며, uncatched exception이다. 따라서, exception에 대한 어떠한 처리를 하지 않더라도 정상적으로 컴파일된다. 하지만, 런타임에 unhandled exception이 발생할 것이다.
checked exception과 unchecked exception으로 구분하는 이유는?
unchecked exception은 정상적으로 컴파일되기 때문에, 편하게 개발하려고 RuntimeException을 상속하여 Custom Exception을 만들 수도 있다. 하지만, 이건 catch or specify 요구사항이 가지고 있는 의도에 어긋나는 행동이므로 피해야 한다.
throw될 수 있는 exception에 대한 정보는 API에서 parameter, return type 만큼이나 중요한 존재이다. 해당 API를 사용하는 개발자는 어떤 exception이 발생할 수 있는지 를 미리 알고 대처할 수 있다.
“그렇다면 RuntimeException도 checked exception으로 처리하면 되지 않을까?”라는 의문이 들 수 있다. 그러나, 만약 그렇게 한다면, 단순하게 List를 사용할 때에도 IndexOutOfBoundsException와 같은 exception들을 전부 메소드에 throws를 통해 명시해야 될 것이다. 이게 무슨 의미일까? unchecked exception은 발생해서는 안되는 exception임을 의미한다. 개발자가 잘못 개발했을 때 unchecked exception이 발생하는 것이다. 따라서, unchecked exception이 되도록 발생하지 않도록 개발해야 한다.
그리고, 편리함을 위해 Custom Exception이 RuntimeException을 상속하도록 한다면, 해당 클래스를 사용하는 개발자 입장에서, 제대로 만들어진 API가 아니라는 생각이 들 수 있다. 유의하자!
커스텀한 예외 만드는 방법
public class CustomException extends Exception{
public CustomException(String errorMessage){
super(errorMessage);
}
}