[OS 공룡책] Ch11. Mass-Storage Structure
C-SCAN SchedulingDisk AttachmentDisk StructureFCFS SchedulingHDDHDD SchedulingMass-Storage StructureNVM SchedulingOSRAID StructureSCAN SchedulingSSTF SchedulingSwap-Space Management공룡책
Operating System
목록 보기
14/14

Chapter 11: Mass-Storage Structure
→ 보조저장장치 특성 살펴보는 Chapter
Overview of Mass-Storage Structure
HDD
- Magnetic disk의 모음
- secondary storage 보조저장장치 → 메인 저장장치 = memory
- direct access 지원 cf. tape : sequencial access
- Disk I/O time
-
random-access time
→ 원하는 sector 찾음
-
transfer time
→ sector에 있는 내용 bus를 통해 가져옴
-
disk controller overhead
→ 메모리보다 훨씬 많은 시간 소요
-
Moving-head Disk Mechanism
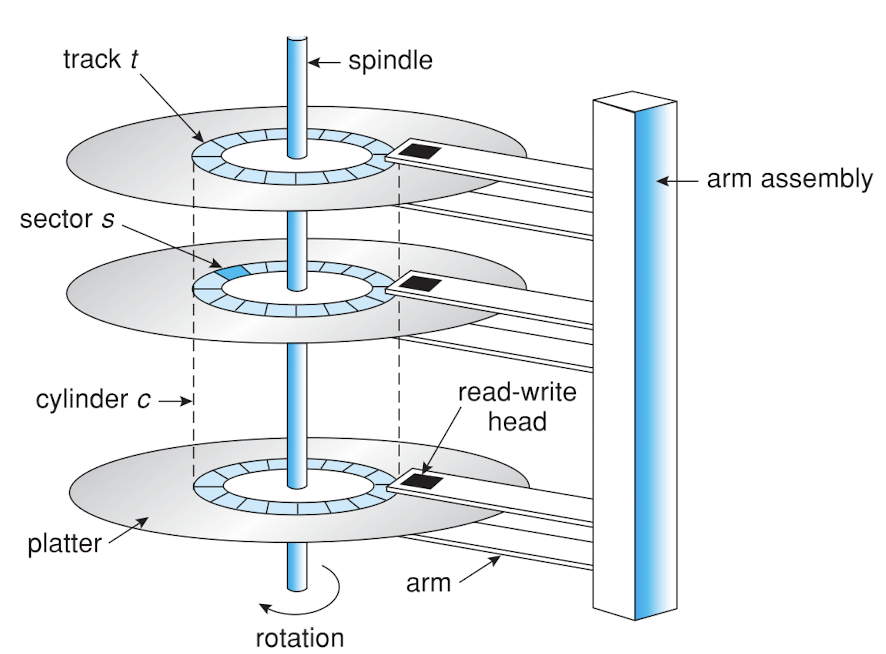
- arm : 원하는 실린더에 헤드 이동시키기 → seek time
- track : 반시계 방향으로 돌려서 원하는 sector에 맞추기 → rotation latency
Hard Disk Performance
- Access Latency(Average access time) = average seek time + average rotation time
- average latency
- 1/2 * latency(60/RPM)
- RPM : disk platter가 1분에 몇 바퀴 도는지 → 60/RPM : 초당 몇 바퀴 도는지
- 평균 반 바퀴
- Average I/O time
- average access time + (amount to transfer / transfer rate)
- controller overhead
- average access time + (amount to transfer / transfer rate)
- Example> 4KB block, 7200RPM, 5ms average seek time, 1Gb/s transfer rate, 0.1ms controller overhead
- average seek time : 5ms
- average rotation time : 1/2 * (60 / 7200) = 4.17ms
- controller overhead : 0.1ms
- transfer time : 4KB / 1Gb/s = 32 / 1024^2 = 0.031ms
- average I/O time for 4KB block = 9.27ms + 0.031ms = 9.301ms
Disk Structure
- disk : logical block으로 구성 → 하나의 sector 단위로 physical 주소(CHS)에 어떻게 매핑?
- CHS : 실린더 번호, 헤더 번호, 섹터 번호
- 1번째 platter 바깥쪽 섹터 : Sector 0 → … → n번째 platter 바깥쪽 → 1번째 platter 바깥에서 두 번째 섹터 → …
- angular velocity(각속도)
- 옛날엔 상수였음 → 각도별로 밀도 달라짐 (일관성 X)
- 요즘엔 ZBR(Zone Bit Recording) 사용 → 위치별로 비트 기록, 일정 각도당 들어가는 sector개수 상이
- 옛날엔 상수였음 → 각도별로 밀도 달라짐 (일관성 X)
Disk Attachment
- I/O bus
- ATA (advanced technology attachment) → parallel
- SATA (serial ATA) → serial
- eSATA : 외장하드도 연결
- USB (Universal Serial Bus)
- FC (Fiber Channel)
- ATA (advanced technology attachment) → parallel
- NVM : PCI 버스에 직접 연결된 NVM express 인터페이스 사용
HDD Scheduling
Disk Scheduling
- Disk I/O request
- input / output mode
- disk address
- memory address
- 전송할 sector 개수
FCFS Scheduling
- 실린더 번호 queue에 대기

- 640 실린더만큼 이동 → seek time만 고려 (rotation time은 고려 X)
- 구현 용이
SSTF Scheduling
- Shortest Seek Time First : 가장 가까운 실린더부터

- 246 실린더만큼 이동
- 이동 개수 최소화
- 성능 가장 좋음 : request만 고려
- starvation 발생
SCAN Scheduling
- SCAN algorithm = Elevator algorithm
-
일정 방향으로만 계속 이동
→ 끝까지 가면 방향 전환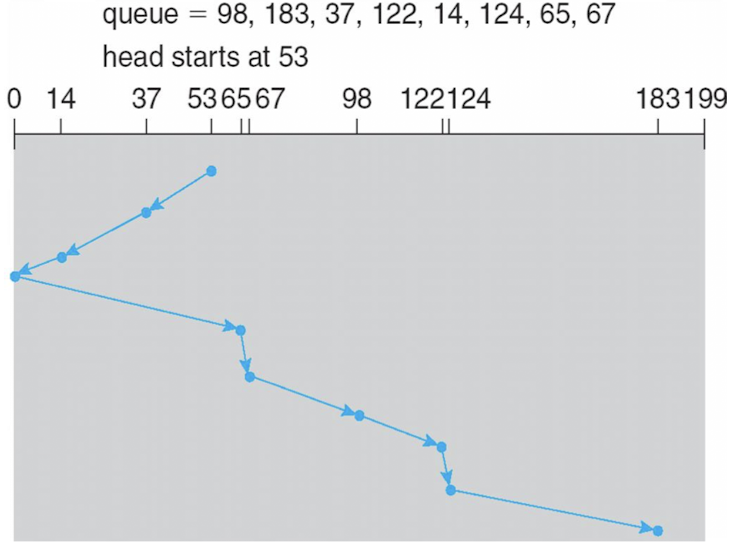
-
- 236 실린더만큼 이동
- 반대방향 가장 먼 실린더가 너무 오래 기다림
- 0까지 굳이 가지 않고 바로 트는 것 = look 방식
C-SCAN (Circular SCAN) Scheduling
- 항상 한 방향으로만 이동
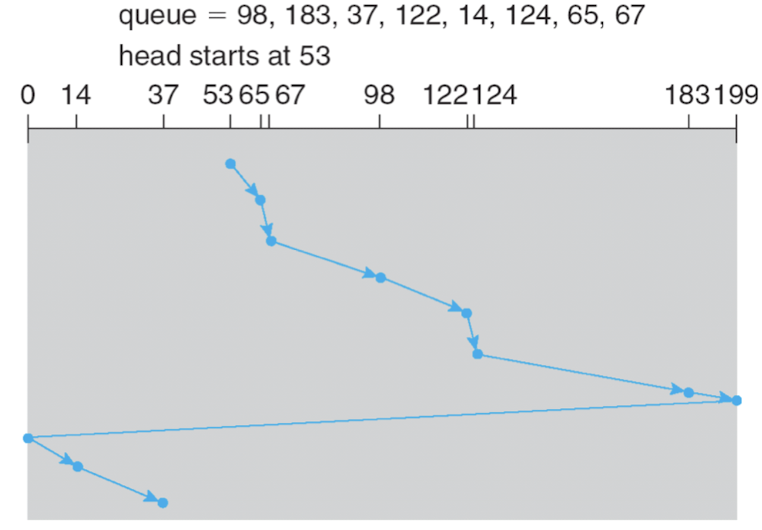
- 382 실린더만큼 이동
- 너무 오래 기다리는 실린더 존재 X
- 끝까지 굳이 가지 않는 것 = c-look 방식
NVM Scheduling
Nonvolatile Memory Device (NVM)
- SSD (비휘발성 메모리), USB 드라이브
- 장점
- HDD보다 높은 신뢰성 (고장 X)
- 탐색 지연시간X → 빠른 속도
- 에너지 효율적
- 단점
- 높은 가격, 작은 용량, 짧은 수명 (제한적 용도, writing 용량 제한)
- 페이지 단위 읽고 쓰기 가능하지만 덮어 쓸 수 X
- 삭제 : 여러 페이지로 구성된 블록 단위로
NAND 플래시 제어기 알고리즘
- 덮어쓰기 X → valid page, invalid page 존재
- Flash Translation Layer (FTL)
- 유효한 데이터를 포함하는 논리 블록 추적
- 유효하지 않은 가용공간 → garbage collection
- 과잉 공급(over-provisioning) 기법
- 유효한 데이터를 이동시킬 여분의 공간
- 마모 평준화(wear leveling)에 도움됨 → 모든 블록이 최대한 골고루 펴지게
NVM Scheduling
- seek time 필요 X → 간단한 FCFS 정책
- Linux의 NOOP 스케줄러 → FCFS 정책 + 인접한 요청 병합하도록 수정
- NVM 쓰기 성능
- 장치가 얼마나 찼는지, 얼마나 마모되었는지 따라 상이
- write amplication (쓰기 증폭) → valid page 옮기는 과정에서 불필요한 쓰기 작업 발생
- 복습 kernel의 기능
- virtualization
- process 추상화
- memory 가상화
- virtual memory
- concurrency
- thread
- synchronization : 일관성 유지
- persistency
- file system
- virtualization
Swap-Space Management
Swap-Space Management
- swap-space
- memory랑 똑같이
- 드라이브에 분산 사용
- swap map
- 각각의 swap-space마다 몇 개씩 할당 등의 부가적 정보들 테이블 형태로 유지
RAID Structure
RAID Structure
- 고려사항
- Performance
- Reliability
- 원래 RAID의 시초 = 안전성
- mean time to failure
- 고장날 때까지 걸리는 평균 시간
- 클수록 좋음
- mean time to repair
- 수리할 때 걸리는 시간
- 짧을수록 좋음
- mean time to data loss
- 데이터를 잃을 확률
- 1 / N * Pf
RAID Levels
-
RAID 0: non-redundant striping
- 백업 X
-
RAID 1: mirrored disks

- 사용 가능 공간 1/2
- reliability 증가
-
RAID 2: memory-style error-correcting codes
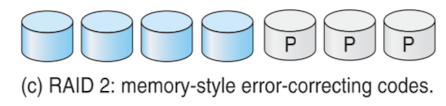
-
RAID 3: bit-interleaved parity
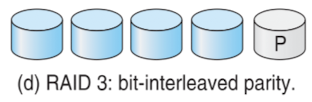
- parity : even, odd (1의 개수 홀수로) → 각 자리에 xor 0 연산해주면 parity bit 결정됨
- 오류 여부 인지 가능
- parity : even, odd (1의 개수 홀수로) → 각 자리에 xor 0 연산해주면 parity bit 결정됨
-
RAID 4: block-interleaved parity
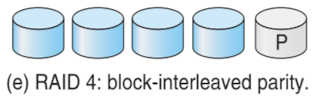
- block 단위로 parity 계산
-
RAID 5: block-interleaved distributed parity

-
RAID 6: P+Q redundancy
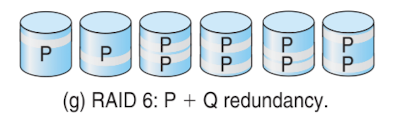
- parity 2개 → error 측면에서 좀 더 안정적
- parity 2개 → error 측면에서 좀 더 안정적

숭실대학교 컴퓨터학부 21