
10장. 다차원 공간 화일
다차원 공간 화일
- 다차원 데이터
- 전통적인 1차원 데이터 레코드 X
- CAD나 지리 정보 시스템에서의 선, 면, 위치와 같은 데이터
- 다차원 데이터를 나타내는 (x,y), (x,y,z)같은 차원당 하나의 값
- 단일 키 화일 구조로 처리 불가
- 다차원 인덱스 구조 필요
- 다차원 공간 화일
- 여러 개의 필드(차원)를 동시에 키로 사용
- 다차원 공간 화일을 트리로 표현
- k-d트리, k-d-B트리
- 격자 화일
- 사분 트리
- R-트리, R+-트리, R*-트리
- 다차원 인덱스 기법
- PAM (Point Access method)
- 다차원 점 데이터를 공간에서 저장, 검색하는 점 접근 방법
- k-d트리, k-d-B트리, 격자 화일
- SAM (Spatial Access Method)
- 선, 면, 다각형, 다면체같은 다차원 공간 데이터를 저장, 검색하는 공간 접근 방법
- R-트리, R*-트리, R+-트리
- PAM (Point Access method)
k-d 트리
-
k-dimensional 트리
- k차원의 점 데이터를 인덱스 하는 구조
- 이원 탐색 트리를 다차원 공간으로 확장
- 기본 구조와 알고리즘은 이원 탐색 트리와 유사 분기 조건 ≤
- 트리의 레벨을 내려가면서 차원의 필드값을 차례로 번갈아 비교 ex. 3차원의 경우 x→y→z→x→y→…
-
특징
- 메인 메모리상에서 동작하는 인덱스 구조
- 소규모의 다차원 점 데이터를 인덱싱할 때 적합 (PAM)
- 균형 트리X
-
삽입

- a(5,4) 삽입 : 루트, 2-d트리
- b(2,7) 삽입 : 루트의 x값과 비교 → 작으므로 왼쪽 자식 노드
- c(9,5) 삽입 : 루트의 x값과 비교 → 크므로 오른쪽 자식 노드
- d(3,1) 삽입 : 루트의 x값 비교 (왼쪽), b의 y값과 비교 (왼쪽)
-
검색 : 위치 (4,8)의 점은 무엇인가?
- 루트 a(5,4)에서 x값 비교 → 왼쪽 트리로
- b에서 y값 비교 → 오른쪽 트리로
- j발견 → 검색 완료
- 분기실패(NULL) → 레코드 존재X
- k-d트리의 높이 = h → 최악의 검색 시간 O(h)
-
삭제
- 삭제된 노드의 서브트리들에 대한 재구성 필요 (복잡)
-
단점
- 균형트리 X → 트리의 높이 극단적으로 높아지면 성능 저하
k-d-B-트리
-
k-dimentional B-tree
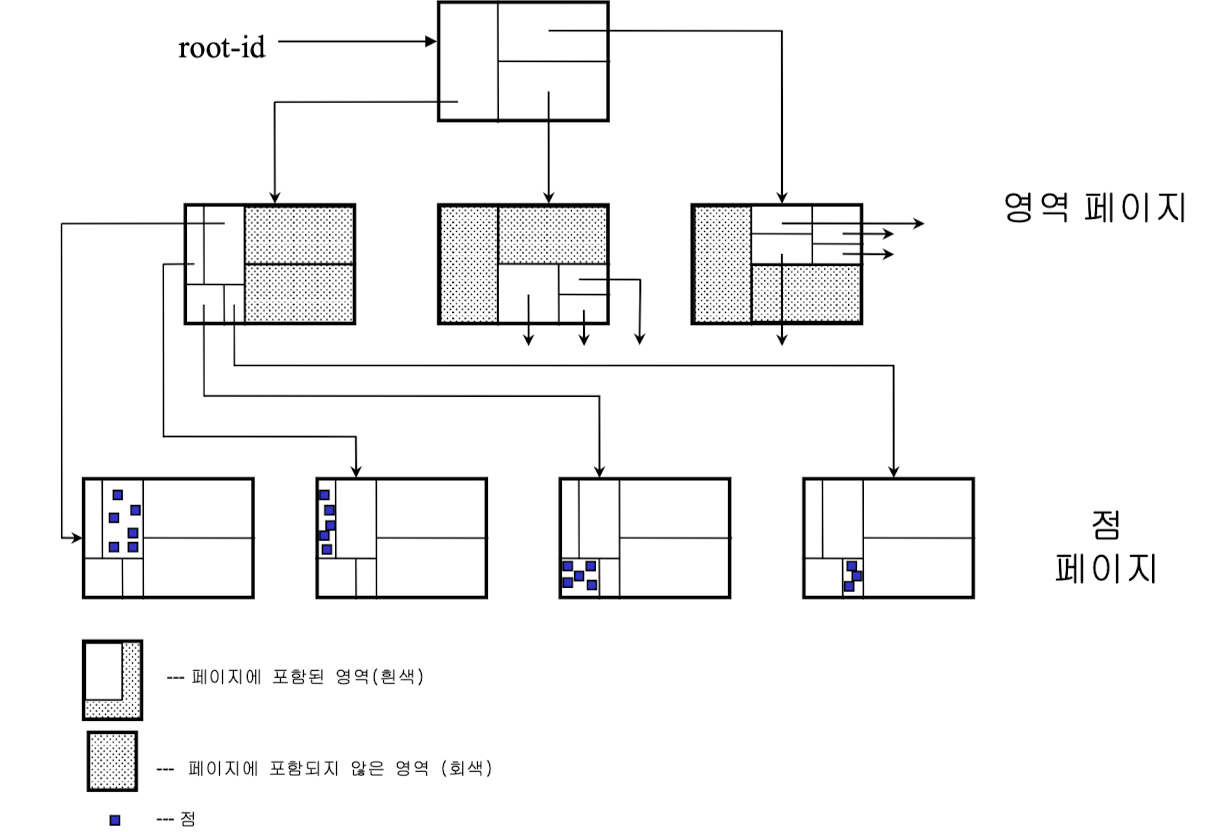
→ 2-d-B 트리 예
- k-d트리 + B-트리 특성 결합
- 디스크 기반으로 다차원 점 데이터 효율적으로 검색, 저장하기 위한 구조
- 일정 크기의 노드로 구성된 다원 탐색 트리
- 균형 트리 : 루트에서 리프 노드까지의 탐색 경로 길이 모두 동일
-
다중키 레코드 검색을 위한 인덱스 레코드 구조
- (key0, key1, …, keyK-1, 주소)
- keyi : 도메인 i에 속하는 탐색 키
- k : 차원(필드) 수
- 주소 : 이러한 키 값을 가진 데이터 레코드가 저장된 주소
-
범위 질의 지원
- 범위 질의
- 레코드를 검색하는 조건으로 도메인에 해당하는 탐색 키 값을 그 키 값의 범위(두 개의 경계값)로 명세하는 질의
- 각 탐색 키 값 min(i), max(i)로 명세
- min(i) ≤ key(i) ≤ max(i)
- 점 = 카티션 프로덕트 = (도메인0 도메인1 … * 도메인k-1)의 한 원소
- 영역 = C와 같은 성질을 만족하는 모든 점 Xi들의 집합 C : min(i) ≤ Xi ≤ max(i) → min(i), max(i)는 도메인i의 원소
- 점은 Xi만 저장 → k개의 필드 값을 가진 하나의 레코드 인스턴스에 해당
- 영역은 min(i), max(i)를 저장 → k개의 필드 값에 대한 범위 조건을 만족하는 레코드의 집합
- 범위 질의
-
구조
- 루트 페이지와 자식 페이지로 구성
- 페이지
- 영역 페이지
- <영역, 페이지-id> 쌍의 엔트리들을 포함하는 노드
- 점 페이지
- <점, 주소> 쌍의 엔트리들을 포함하는 단말 노드
- 주소 : 점 데이터 레코드가 저장되어있는 주소
- 영역 페이지
- 페이지 크기 = 디스크 페이지 크기
- 엔트리 삽입 후 오버플로 → 분할 연산 필요
- 엔트리 삭제 후 언더플로 → 합병 연산 필요
-
특성
- 각 페이지 = 노드
- 영역의 페이지-id = 노드 포인터
- k-d-B트리 = root-id가 가리키는 다원탐색트리
- 영역 페이지
- 공백이거나 널 포인터 포함 X
- 소영역으로 완전 분리 분할 가능
- 소영역의 합 = 부모 영역
- 모든 단말 페이지까지의 경로 길이 동일
- 루트 페이지 = 영역페이지 → 페이지 소영역들의 합 = 화일 전체의 영역
- 자식 페이지 = 점 페이지 → 점 페이지에 있는 모든 점들은 부모 영역에 포함
-
검색

- k-d-B트리가 지원하는 범위 질의 = 질의 영역으로 표현
-
부분 범위 질의
→ 차원이 모두 범위로 명세
-
부분 일치 질의
→ 차원의 일부가 점, 나머지는 범위
-
완전 일치 질의
→ 모든 차원이 점으로 명세
-
- 질의 영역을 만족하는 모든 레코드 검색 알고리즘
-
root-id = NULL → 종료
아니면 변수 page는 루트 페이지 가리킴
-
변수 page가 점페이지 가리키면
- 질의 영역에 속하는 <점, 주소> 검사
- 그 주소에 해당하는 레코드 검색
-
변수 page가 영역 페이지인 경우
- 질의 영역과 중첩되거나 포함되는 모든 <영역,child-id>에 대해 차례로 변수 page가 이 페이지를 가리키게 함
- 다시 2번 수행
-
- k-d-B트리가 지원하는 범위 질의 = 질의 영역으로 표현
-
삽입
-
원소 값 xi에 따라 영역 Ix * Iy 분할하는 방법
- x’이 구간 Ix에 포함되는 경우에 구간 Ix = [minx, maxx]는 영역 Ix * Iy를 다음과 같이 두 소영역으로 분할
- [minx, x’] * Iy : 왼쪽 영역
- [x’, maxx] * Iy : 오른쪽 영역
- x’이 구간 Ix에 포함되는 경우에 구간 Ix = [minx, maxx]는 영역 Ix * Iy를 다음과 같이 두 소영역으로 분할
-
원소 값 xi에 따라 점페이지 분할 방법
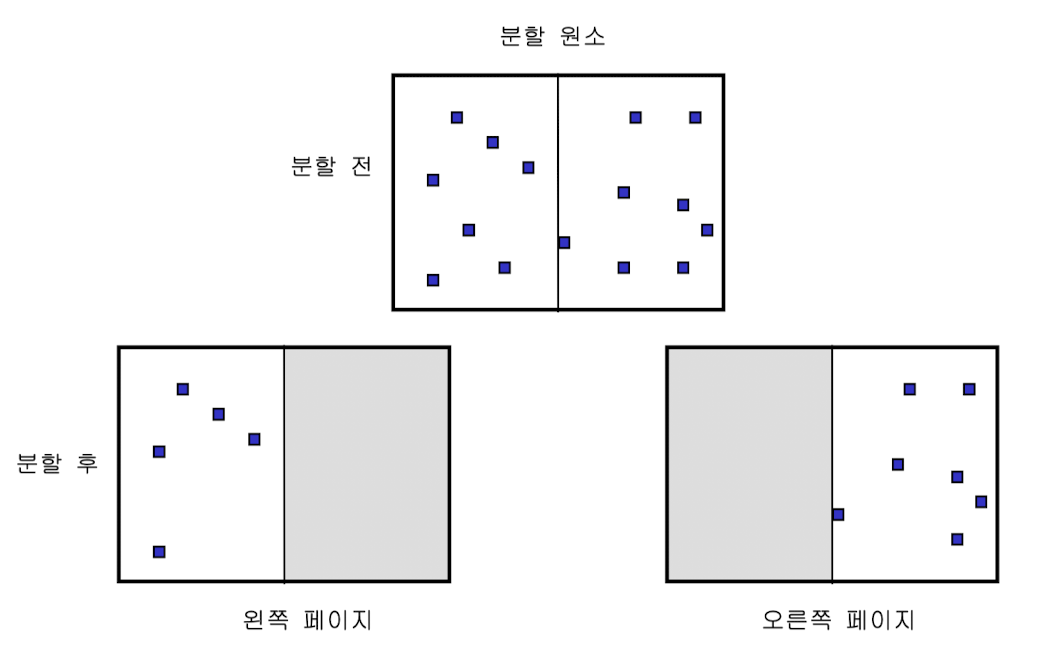
- x’ 값에 따라 점 페이지를 오른쪽 점 페이지와 왼쪽 점 페이지로 분할
- 모든 <점, 주소> 쌍에 대해 x의 값과 x’의 값 비교
- 오른쪽 or 왼쪽 점 페이지로 이동
- 원래의 점페이지는 삭제
-
원소 값 xi에 따라 영역 페이지 분할 방법
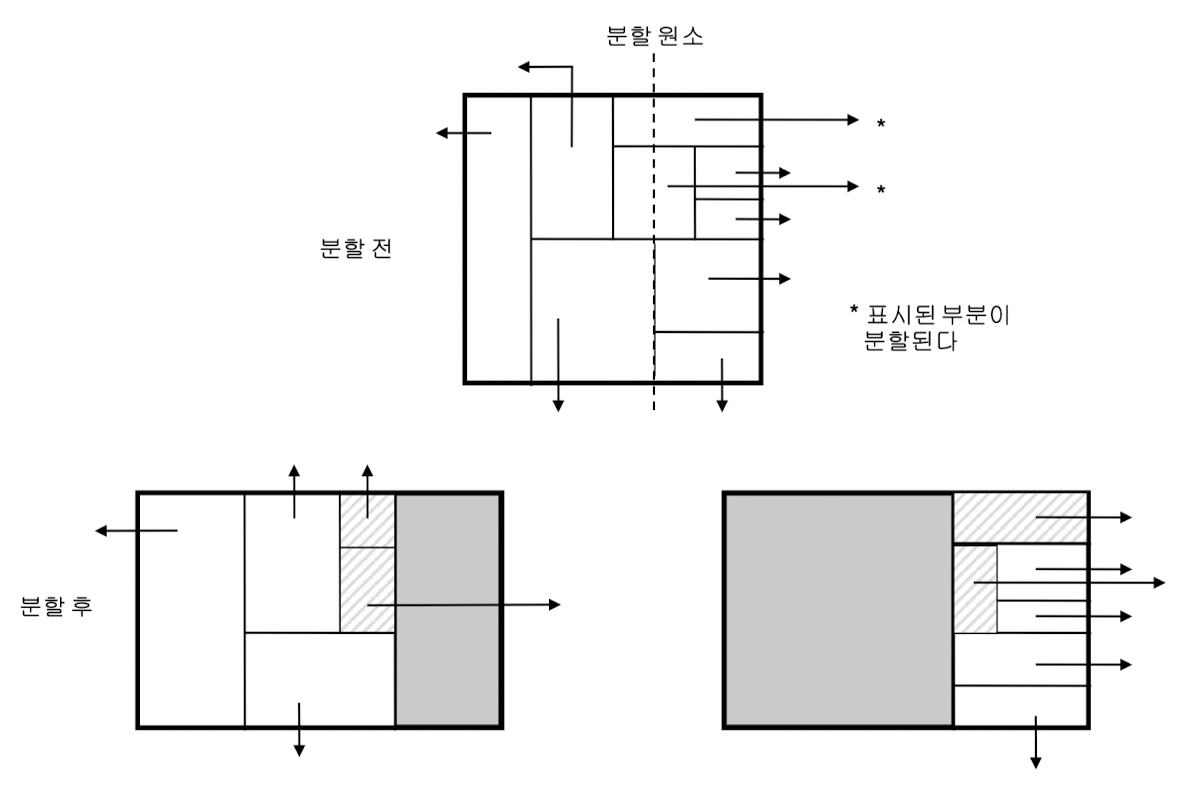
- x’에 따라 영역페이지를 오른쪽, 왼쪽 영역 페이지로 분할
- 모든 <영역, 페이지-id> 쌍 엔트리를 오른쪽, 왼쪽 페이지로 이동
- 원래의 페이지는 삭제
-
영역의 엔트리들 분할 방법
- 영역이 x’의 왼쪽 : <영역, 페이지-id>를 왼쪽 영역 페이지로 이동
- 영역이 x’의 오른쪽 : <영역, 페이지-id>를 오른쪽 영역 페이지로 이동
- x’이 영역 중간 가로지르면 : 영역을 x’값에 따라 두 개의 소 영역으로 분할 → 각각 오른쪽, 왼쪽 페이지에 첨가
-
인덱스 레코드 <점, 주소> 쌍 삽입하는 알고리즘
-
root-id = NULL
- 점 페이지 생성
- <점, 주소> 엔트리 저장
-
<점, 주소> 쌍이 삽입되어야 할 페이지를 완전 일치 질의 수행으로 탐색
- 페이지 여유 공간 있으면 <점, 주소>쌍 페이지 삽입 후 종료
-
점 페이지에 오버플로 발생
- 엔트리 등분할 수 있는 적절한 도메인i의 원소 Xi 선택
- 페이지 분할, 엔트리 이동
-
분할된 페이지의 부모 영역 페이지에 있는 원래의 <영역, 페이지-id>를 새로운 <왼쪽 영역, 페이지-id>, <오른쪽 영역, 페이지-id>로 대체
- 엔트리 증가로 페이지 오버플로 되면 영역 페이지 다시 분할 → 4 다시 실행
- 엔트리 증가로 페이지 오버플로 되면 영역 페이지 다시 분할 → 4 다시 실행
-
루트 페이지가 분할하게 되면 새로운 루트 페이지 생성하여 조정
→ k-d-B트리의 높이 하나 증가
-
-
-
삭제
-
점 페이지에서 <점, 주소> 쌍을 완전 일치 질의로 검색 후 삭제
-
공간 이용률 높이기 위한 재구성
- 합병 : 두 영역의 엔트리들을 하나의 큰 페이지로 통합
- 언더플로 : 두 형제 영역을 합병 or 엔트리들 재분배
-
두 영역의 합이 보다 큰 직사각형 형태의 영역을 구성하게 되면 합병 가능
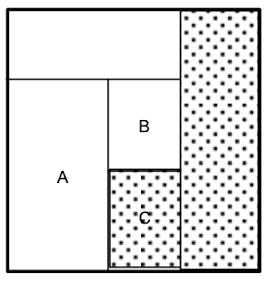
→ (A, B), (A, C) 합병 불가
→ (B, C)는 가능
-
격자 화일
-
격자 화일
- 공간상의 점 데이터를 저장하는 다차원 인덱스 구조
- 전체 공간을 격자로 분할 → 격자 단위로 데이터 저장
- 격자의 크기 = 데이터 삽입에 따라 분할되어 작은 격자로 변환
-
특징
- 디스크 기반 → 대용량의 다차원 데이터 처리
- 해싱 기반 → 일반적으로 두 번의 디스크 접근으로 데이터 탐색
-
구성

- K-차원 격자 화일
- k개의 선형 눈금자 + k-차원의 격자 배열로 구성된 격자 디렉터리로 관리
- 디렉터리가 해싱 역할 수행
- 선형 눈금자
- 각 차원별 눈금 정보 표현
- 메인 메모리에 유지
- 격자 배열
- 선형 눈금자에 의해 분할된 격자 블록으로 구성
- 각 격자 블록에는 데이터 페이지를 가리키는 페이지 번호 저장
- 격자 배열, 페이지 → 디스크에 저장
- 기본적으로 하나의 격자 블록당 하나의 데이터 페이지 → 두 개 이상의 격자 블록이 하나의 데이터 페이지 공유 가능
- K-차원 격자 화일
-
삽입
- 하나의 격자 블록을 통해 페이지 P1 저장
- P1 만원 : 격자 x = 10으로 격자 분할 → 페이지 P2 할당 → 분할된 두 페이지 P1, P2 = twin → x > 10 레코드들 P2로 이동
- 페이지 P1 오버플로 발생
- y = 5로 격자 분할 → 페이지 P3 할당
- P1에 있는 y<5인 레코드들 P3으로 이동
- P2는 원하지 않게 분할된 두 격자가 공용
- P3 오버플로 발생
- x = 5로 격자 분할 → 페이지 P4 할당
- 레코드 분할
-
격자 화일의 질의

- 메모리에 선형 눈금자 유지
- x=7, y=2인 데이터 탐색
-
선형 눈금자 (SX, SY) 검사
- x = 7 : SX의 두 번째 범위
- y = 2 : SY의 첫 번째 범위
-
격자 배열 인덱스 (2,1) 결정
-
디스크에 있는 격자 배열 G[2,1] 접근
→ 데이터 페이지 번호 P3 검색
-
디스크 데이터 페이지 P3 접근
→ 페이지 P3에서 데이터 d 검색
-
- 두 번의 디스크 접근으로 데이터 접근 가능 → 격자 배열, 데이터 페이지
-
삭제
- i 삭제 → P3, P4는 하나의 페이지 P3로 합병 가능
- P3의 트윈 P1은 합병된 격자 블록만 사용
- x=5에 의한 분할 제거 → 격자 블록 합병, 선형 눈금자 수정
- i 삭제 → P3, P4는 하나의 페이지 P3로 합병 가능
사분 트리
- 사분 트리
- 공간을 반복적으로 분해하는 성질을 가진 계층적 자료 구조 표현
- 영역 사분 트리 : 2차원 영역 데이터 표현
- 점 사분 트리 : 다차원 점 데이터 표현
- 구분
- 표현하고자 하는 데이터 유형
- 공간 분해 방법
- 해상도(resolution) : 분해 레벨 정도를 고정 or 가변
- 표현 대상 데이터
-
점, 영역, 곡선, 표면, 볼륨 데이터
-
곡선이나 표면같은 개체의 경계 표현하는 경우
-
영역이나 볼륨같은 개체 내부 표현하는 경우
→ 두 경우 상이한 자료구조 사용
-
- 공간 분해 방법
- 이미지 공간 계층 → 각 레벨마다 공간을 일정 크기의 동일한 소공간으로 분해
- 객체 공간 계층 → 입력 데이터 값에 따라 가변적 크기의 공간으로 분해
- 이미지 공간 계층 → 각 레벨마다 공간을 일정 크기의 동일한 소공간으로 분해
-
영역 사분 트리
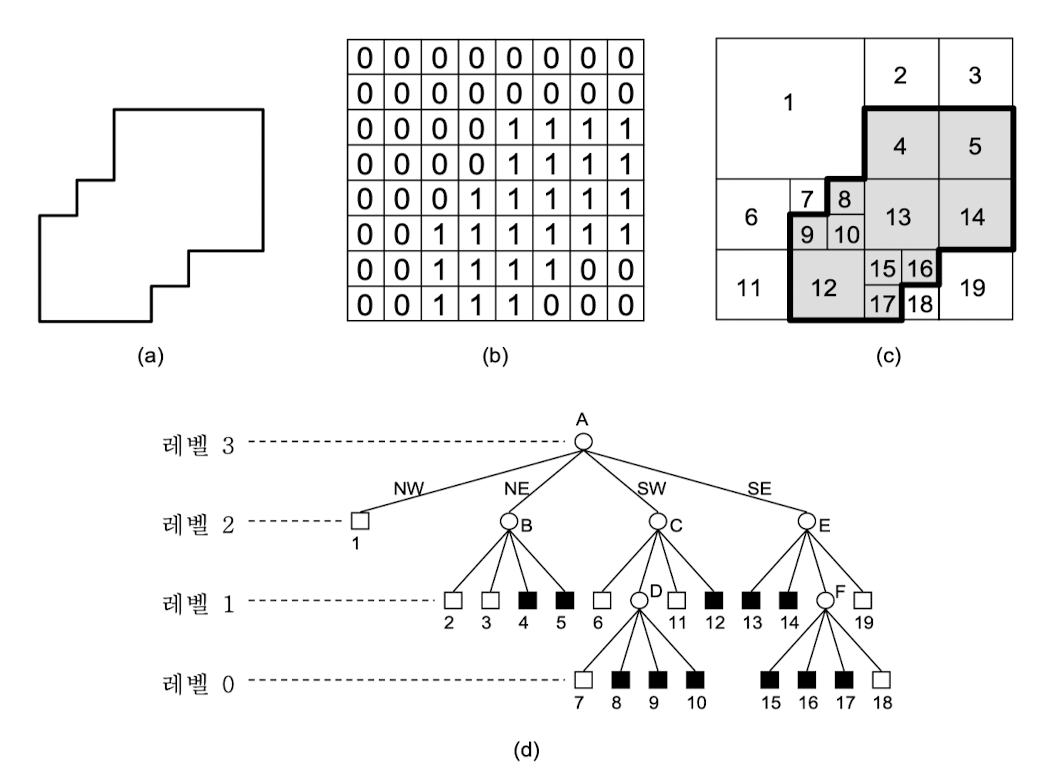
-
2차원 영역 데이터 표현에 많이 사용
-
이미지를 표현하는 2진수의 배열을 동일한 크기의 사분면으로 연속적으로 분할 → 서브사분면으로 분할, 가변 해상도 자료 구조
-
루트 노드는 이진 배열 전체에 대응
- 자식 노드 : 부모 노드가 표현하는 영역의 한 사분면 표현 → 아래 순으로 레이블 붙임
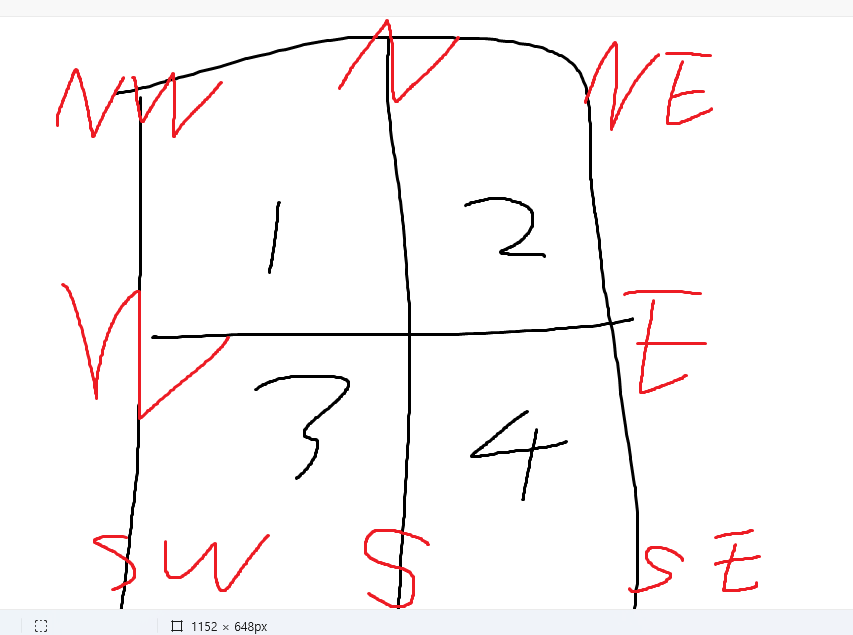
- 리프 노드 : 분할이 필요없는 블록
- 흑색 노드 : 블록이 완전히 영역의 내부에 포함 → 1로 표현된 서브사분면
- 백색 노드 : 블록이 완전히 영역의 외부에 포함 → 0으로 표현된 서브사분면
- 회색 노드 : 단말이 아닌 노드 → 0과 1로 표현된 블록 모두 포함
- 자식 노드 : 부모 노드가 표현하는 영역의 한 사분면 표현 → 아래 순으로 레이블 붙임
-
-
점 사분 트리
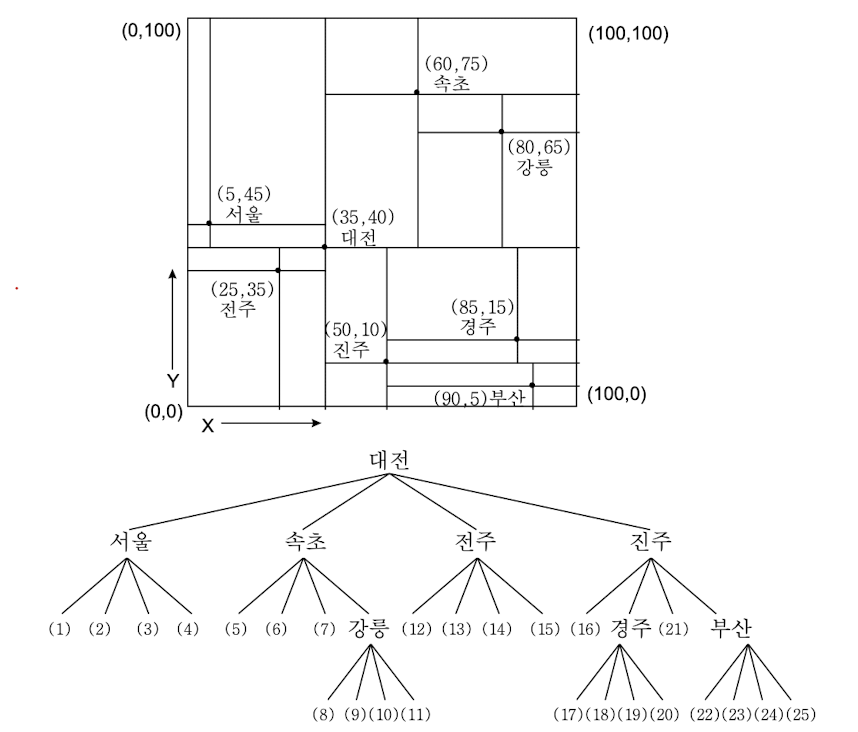
- 점 데이터 표현
- 공간을 동일하지 않은 4개의 소공간으로 분할
- 2차원 점 데이터에 대한 인덱스 활용
- 단말 노드 : 버켓의 포인터 저장 (인덱스 역할)
- 트리에는 비교하는 점 데이터만 저장
- 전체 레코드 : 인덱스에 의해 참조되는 버켓에 저장
- 2차원 점 데이터 레코드
- 데이터 필드, x좌표, y좌표, 4개(NW, NE, SW, SE)의 포인터 필드를 갖는 노드
- 다차원 데이터를 위한 이원 탐색 트리의 일반화
- 삽입
- 삽입할 레코드의 위치 x,y좌표 값 바탕으로 탐색
- 노드의 좌표 값과 삽입할 데이터의 좌표 값 비교
- 반복 후 도착한 리프노드에 레코드를 삽입할 버킷의 주소
- 점 사분트리의 삽입과정
- 최적 점 사분 트리 구성 방법
- 모든 점 데이터를 미리 알 수 있는 경우에 최적화 가능
- 어떤 노드의 서브트리도 전체 노드 수의 반 이상 갖지 않는 트리로 정의
- 모든 점 데이터들을 하나의 좌표축(x)값으로 정렬
- 다른 좌표축 (y)값은 보조키로 사용
- 루트 = 정렬 화일의 중간값
- 나머지 4개 그룹으로 나누어 루트의 네 서브트리가 되도록 함
- 검색
- 탐색 공간을 좁혀 나가는 기법
- 한 레벨 내려 갈수록 탐색 공간은 1/4로 감소
- 리프 노드가 가리키는 버킷에서 원하는 데이터 검사
- ex. (95, 8)에 위치한 도시를 검색하라 → 대전 (35, 40)의 SE → 진주 (85, 15)의 SE → 부산 (90, 5)의 NE → 버킷 23 조사
- 삭제
- 매우 복잡
- 삭제할 노드를 루트로 하는 서브트리에 있는 모든 노드들 재삽입 필요
- 이상적인 삭제 방법
- 삭제할 노드 A를 어떤 노드 B로 대치한 후 삭제
- 노드 B는 노드 A를 루트로 하는 서브트리의 노드들이 속해있는 사분면에 영향 X
- 이런 B가 존재하지 않을 경우 가장 근접한 것으로 대체
- 영역에 존재하는 점 데이터들 재삽입
R-트리
-
R-트리
- B-트리를 다차원으로 확장시킨 완전 균형 트리
- 점,선,면,도형 등 다양한 다차원 공간 데이터 객체를 저장, 검색하기 위한 다차원 인덱스 구조
- SAM : Spatial Access Method
- MBR을 인덱스 엔트리로 저장
- 디스크 페이지 단우로 데이터 저장, 검색 → 대용량 데이터에 대한 인덱스 구조에 적당
- 인덱스 구조 : 높이 균형 트리 (:= B-트리)
- 리프 노드의 엔트리 = <객체 MBR, 객체가 저장된 주소>
- 중간 노드의 엔트리 = <자식 노드의 모든 MBR을 포함하는 큰 MBR, 자식노드 포인터>
-
MBR
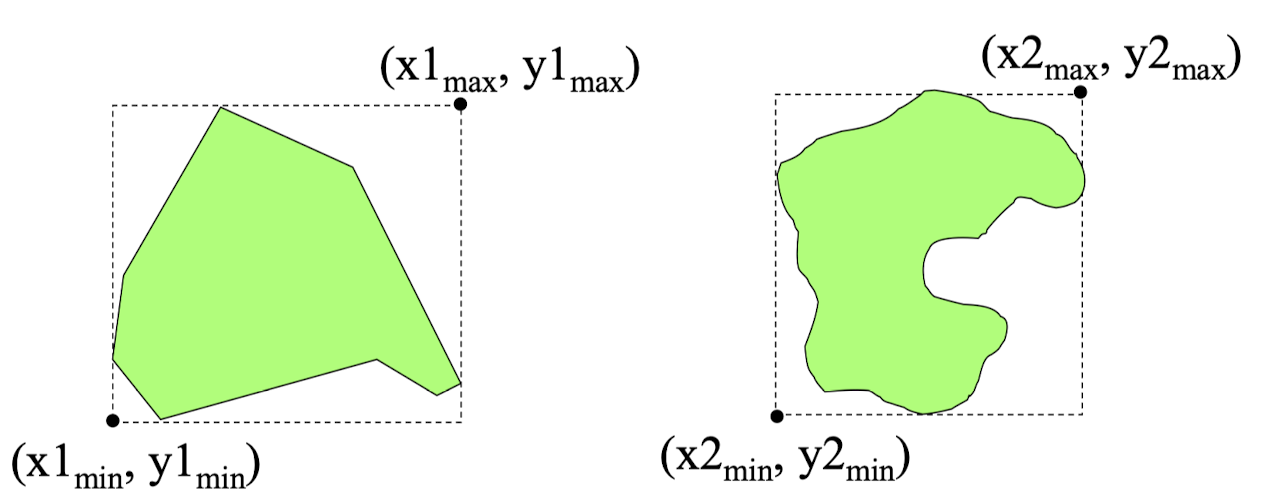
- 종류
- 객체 자체를 나타내는 객체 MBR
- 몇 개의 객체 MBR 그룹을 나타내는 리프노드 MBR
- 몇 개의 MBR 그룹을 나타내는 중간노드 MBR
- (x1min, y1min), (x1max, y1max) 두 개의 2차원 데이터로 표현 → 저장 관리 용이
- 객체 검색 시 검색 대상이 되는 객체 MBR이 해당영역에 속하는지를 먼저 비교 → 탐색 공간 빠르게 축소
- MBR대신 MBB(Minimum Bounding Box)로 표현하기도 함
- 종류
-
특성

- 루트노드가 아닌 노드 : 최소 m개, 최대 M개 인덱스 엔트리와 자식 포인터 포함
- 리프가 아닌 루트노드 : 최소 2개의 자식 노드
- 모든 리프 노드 : 최소 m개, 최대 M개 인덱스 엔트리 포함
- 리프노드에 있는 각 인덱스 엔트리 : MBR, 공간객체가 저장된 페이지 주소
- 완전 균형 트리 → 모든 리프 노드 같은 레벨에
- 점 데이터를 주로 처리하는 k-d-B트리 : 데이터 자체 분할X, 영역 분할O → 중간 노드들 중첩 X cf. 데이터 객체 분할 후 포함하는 영역 MBR로 표현 → R-트리는 MBR이 서로 중첩 가능 O → 전체 영역 중 어떤 MBR에도 포함되지 않는 영역이 있을 수 있음
- 중간 노드들이 표현하는 MBR이 중첩 가능 → 임의의 크기의 객체 분할 저장 용이
-
R-트리 표현
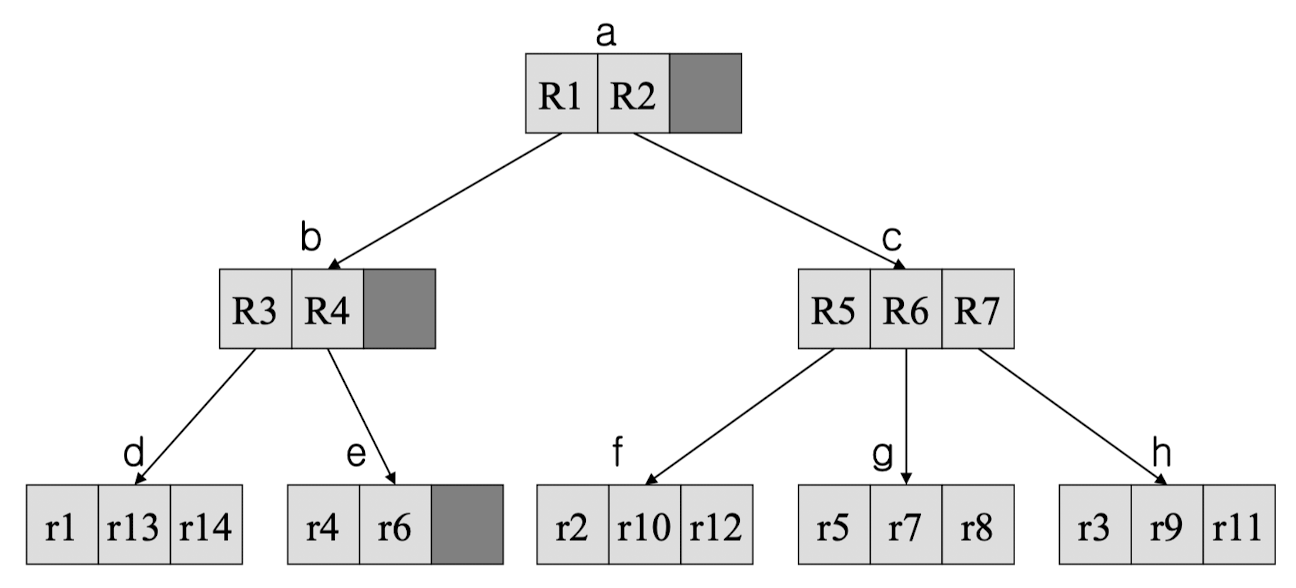
- R-트리 노드 : 디스크 페이지로 저장 → 포인터 = 디스크 페이지 번호
- 트리 노드 구조
- 리프 노드 구조 (oid, mbr)
- oid : DB에서 객체 참조를 위한 객체 식별자
- mbr : 데이터 객체의 MBR
- 중간 노드 구조 (p, mbr)
- p : 트리의 하위 노드에 대한 포인터
- mbr : 하위 노드에 있는 엔트리들이 나타내는 MBR을 모두 포함하는 MBR
- 리프 노드 구조 (oid, mbr)
- R-트리 노드 : 디스크 페이지로 저장 → 포인터 = 디스크 페이지 번호
-
검색
-
영역 검색 질의
- 주어진 영역에 포함된 객체의 검색
- 질의 영역을 트리의 루트 노드에서부터 하위 노드들의 MBR과 비교하여 중첩되는 MBR을 비교 → 리프노드까지 탐색
- 리프 노드에서는 모든 객체 MBR을 비교 → 최종 목표 객체 출력
- 주어진 영역에 포함된 객체의 검색
-
k-NN 질의
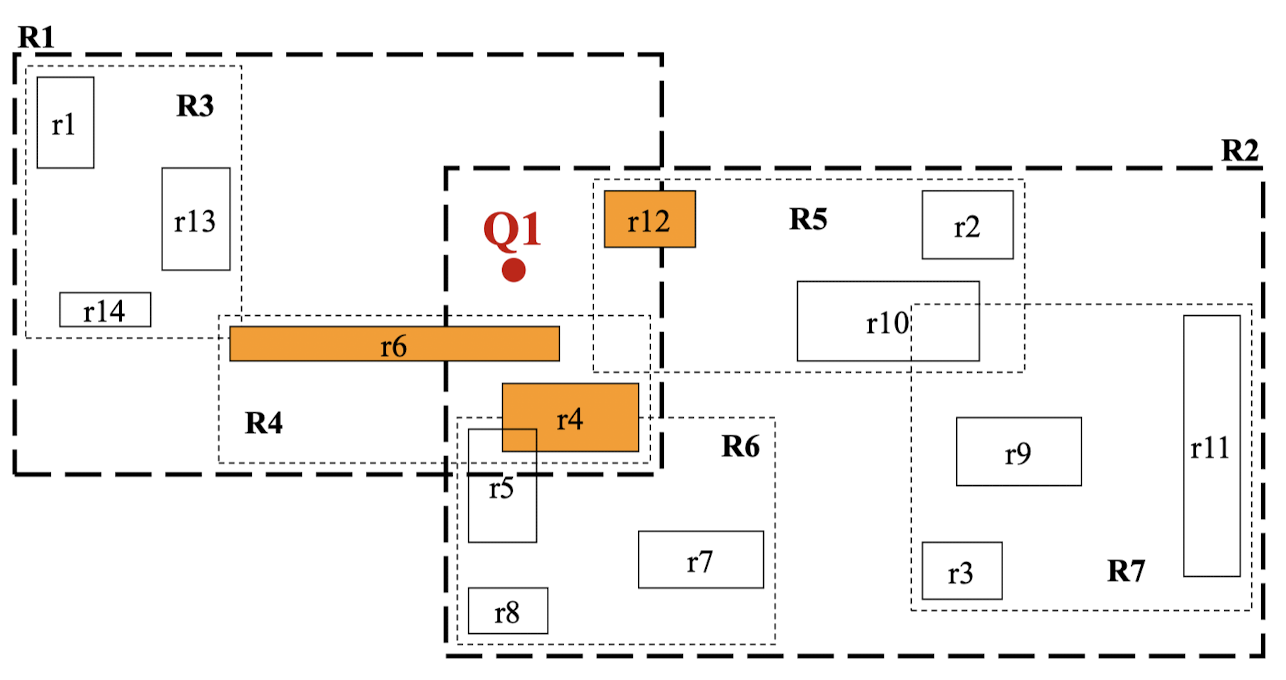

- 질의점으로부터 가장 가까운 k개의 객체를 검색하는 질의
- 우선순위 큐 이용
- 큐 엔트리 <p,d> = <트리 노드의 포인터, 질의점과노드의 거리>
- d가 가까운 것이 우선순위가 높음
- 초기에 루트 노드 삽입
- 우선순위큐로부터 원소를 삭제하여 객체가 아닌 MBR인 경우 이 MBR에 포함된 엔트리를 모두 삽입
- 삭제한 원소가 객체인 경우 결과로 포함
- 결과에 k개의 객체가 포함될때까지 반복
-
-
삽입
-
리프노드 선택
-
리프노드에 데이터 저장
- 빈공간 있으면 → 새로운 엔트리 E저장
- 빈공간 없으면 → 노드 분할하여 E 저장 후 트리 조정
-
트리 재조정
- 새로운 데이터 삽입으로 변경된 MBR들 조정
- 노드가 분할된 경우 새로운 MBR결정
- 부모 노드들 따라가며 분할된 노드에 대한 엔트리 삽입
- 중간노드에 자유공간이 없으면 다시 분할이 계속될 수도
-
트리 높이 증가
- 루트 노드가 분할되어야 한다면 → 새로운 루트 노드 만들어 저장
- 이때 높이가 1증가한다.⇒ 리프 노드 선택, 노드 분할 방법에 따라 성능에 영향
-
-
MBR이 크면
- 질의 영역과 중첩되는 MBR개수 증가
- 검사 시간 증가
-
MBR이 작으면
- 질의 영역과 중첩되는 MBR개수 감소
- 검사 시간 감소
-
삽입으로 인한 노드 분할 방법
-
분할된 두 노드 MBR의 합이 최소가 되도록 분할
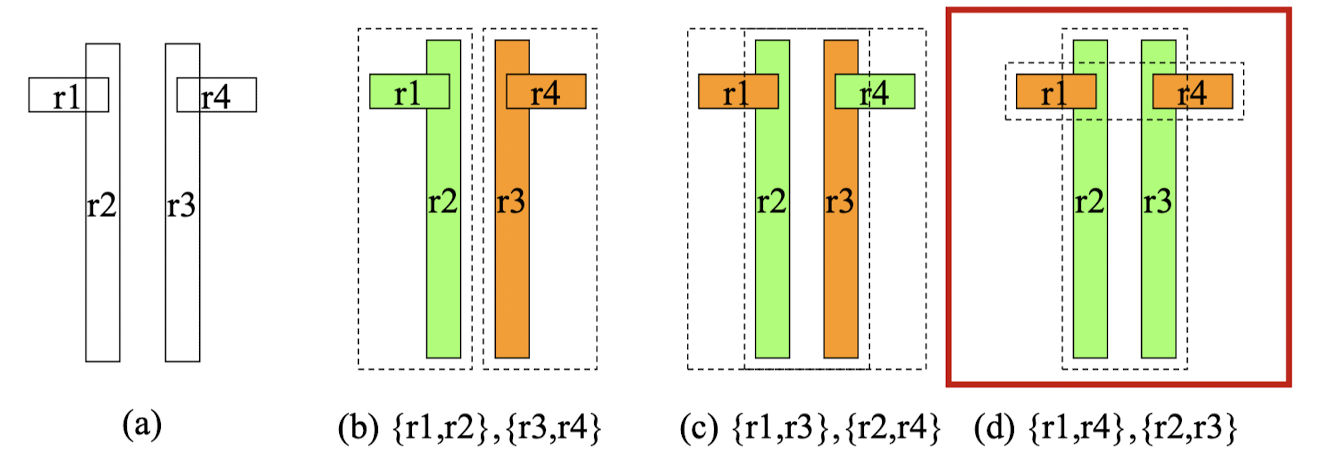
→ 검색시 불필요한 노드 탐색 감소 (질의 성능 증가)
-
삽입 결과
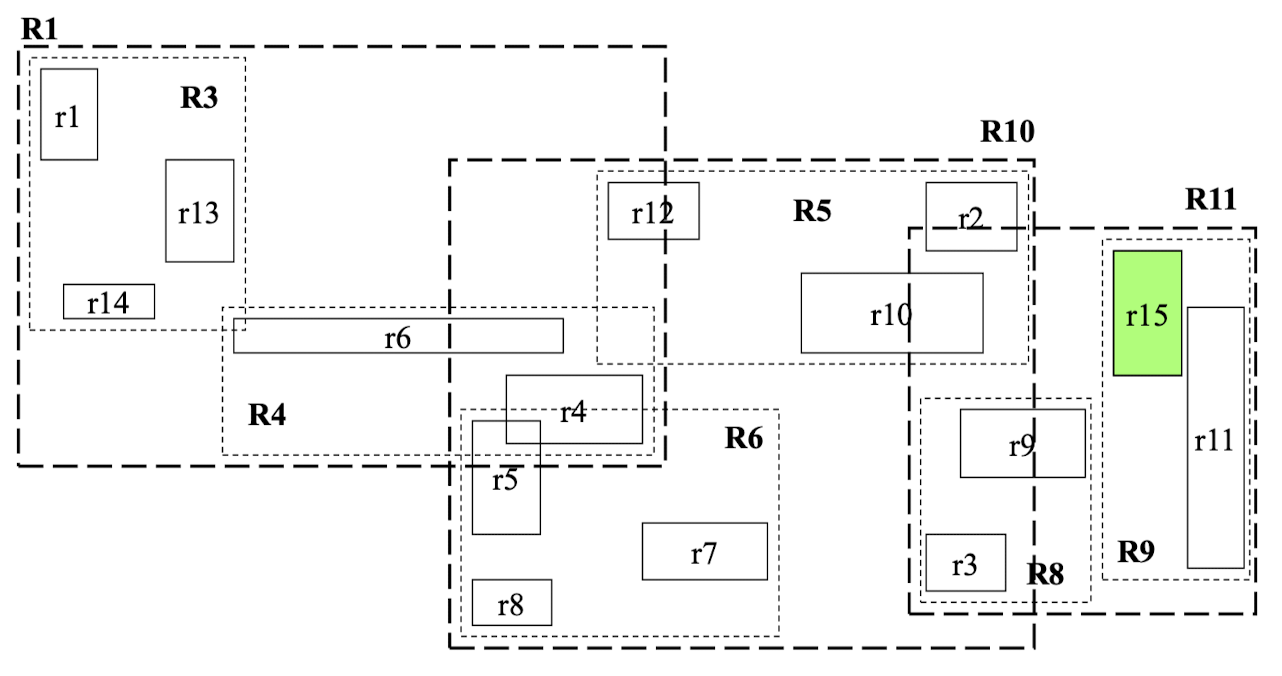
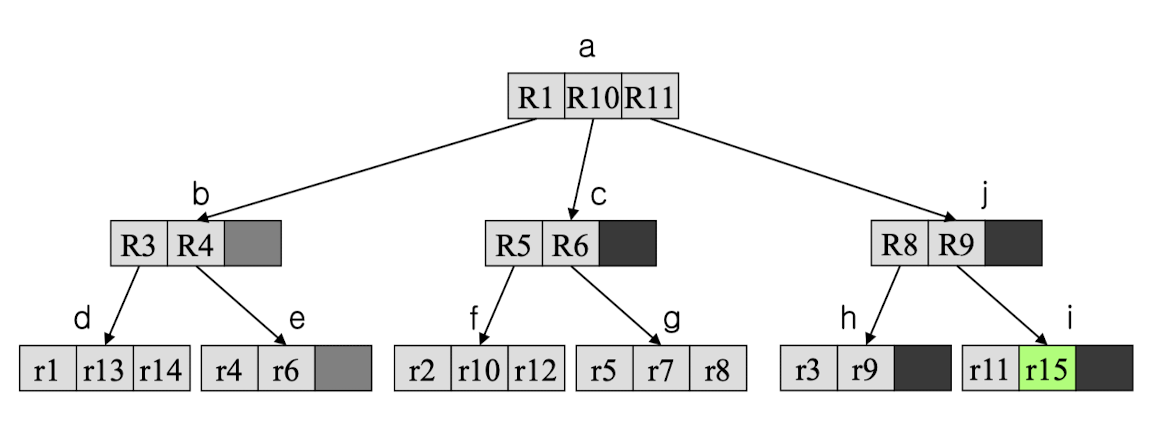
-
-
삭제
- 리프 노드 탐색
- 해당 데이터 삭제
- 언더플로 처리 (m보다 작으면)
- 언더플로 발생한 노드 삭제
- 그 노드의 모든 엔트리들을 다시 삽입
- 삭제로 인한 언더플로 → 트리의 루트 방향으로 파급
- 재조정 후 루트가 하나의 자식만을 갖게 될 경우 → 루트의 자식노드를 새로운 루트 노드로 → 트리의 높이 1 낮아짐
-
분석
-
k차원 데이터를 처리하기 위한 B-트리의 확장으로서 중간노드와 리프노드로 구성된 높이 균형 트리
- 리프 노드 : 인덱스 엔트리 저장
- 중간 노드 : 하위 MBR들을 완전히 포함하는 상위 MBR 엔트리 저장
-
탐색 연산 : 포함과 중첩 관계 중요
- 포함과 중첩 관계가 최소일 때 가장 효율적
- 최소 포함 : 죽은 공간, 빈 공간의 양 감소시킴
- 중첩 : 높이 h, 레벨 h-i에서 k개의 노드 중첩→ 최악은 리프노드에 대해 k개의 경로 접근 필요 → i에서 ik페이지 접근 필요
→ 각 노드의 분기율이 적어도 m이 되기 때문
-
루트를 제외한 모든 노드에서 최악의 공간 활용도 : m/M
→ 트리의 높이를 감소시키면 공간 활용도는 증가
-
