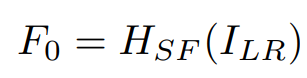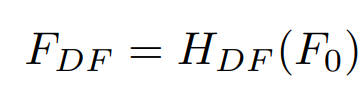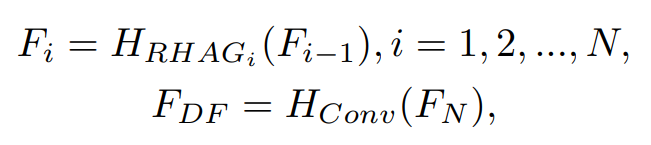Authors
Xiangyu Chen, Xintao Wang, Jiantao Zhou, and Chao Dong University of Macau 2Shenzhen Institute of Advanced Technology,
Chinese Academy of Sciences 3ARC Lab, Tencent PCG 4Shanghai AI Laboratory {chxy95, xintao.alpha}@gmail.com, jtzhou@um.edu.mo, chao.dong@siat.ac.cn
Abstract
기존의 SuperResolution과 같은 낮은 수준의 컴퓨터비전 작업에 많이 사용되었던 트랜스포머 기반 기술들의 네트워크는 제한된 공간 범위의 입력 정보만 활용했음을 발견하였다. 이는 트랜스포머 기반 기술들이 그들의 잠재력을 제대로 발휘하지 못했음을 의미한다. 본 논문에서는, 이를 재구성하여 더 많은 픽셀을 활성화 하기 위해 새로운 HAT(Hybrid Attention Transformer)기법을 제안한다. 이 기법은 채널 어텐션과 셀프 어텐션 방식을 결합하여 상호 보완적인 장점으로 사용한다.
Introduction
최근 자연어 처리의 성공으로 Transformer가 컴퓨터 비전 커뮤니티의 주목을 받고 있습니다. 특히 새로 설계된 네트워크인 SwinIR은 이 작업에서 획기적인 개선을 얻었습니다.
Transformer가CNN보다 나은 이유는 아직 미스터리 이다. 직관적으로 설명하자면, Transformer의 네트워크가 self-attention 메커니증의 이점을 얻고 long-range 정보를 활용한다는 것 이다.그러나 속성 분석 방법인 LAM을 사용하여 SwinIR을 분석해 봤을 때, SwinIR이 그림2에서와 같이 CNN기반 방법보다 더 많은 입력 픽셀을 사용하지는 않는다는 것을 확인하였다. Transformer는 로컬 정보를 모델링하는 능력은 더 좋지만, 활용되는 입력의 범위를 확장해야 함을 보여준다.
따라서, 위 문제를 해결하고, Transformer의 잠재력을 발휘하기 위해, HAT (Hybrid Attention Transformer)를 제한한다.
HAT은
- 더 많은 입력의 범위를 활용하기 위해 Transformer방법의 Channel attention을 도입합니다.
- Cross window 정보를 더 잘 수집하기 위해 Overlapping cross-attenrion 모듈을 제안한다.
- 네트워크의 잠재력을 더욱 활성화 하기 위해, 동일 작업 사전 훈련 전략(Same-task pre-training starategy)을 제공한다.
Method
Motivation
(그림 2)
Swin Transformer는 이미 Image Super Resolution에서 뛰어난 성능을 입증했다. 이 매커니즘을 밝히기 위해, 본 연구에서는 진단 도구로 LAM을 사용하였다. LAM을 사용하면, 선택한 영역에 가장 많이 기여하는 입력 픽셀을 알 수 있다. 그림2(a)에서 볼 수 있듯이 빨간색으로 표시된 점이 가장 많이 기여하는 입력 픽셀이다. CNN방법인 RCAN과 EDSR과 비교했을 때, 입력 픽셀을 더 넓게 사용하지 않았다. 그러나 성능이 더 좋은 것을 보았을 때, 만약 SwinIR이 더 많은 입력 픽셀을 받아들인다면 더 성능이 좋아질 수 있음을 의미한다. 즉, Channel attention scheme을 사용하여 SwinIR을 더 발전 시킬 수 있다.또, 그림2(b)에서 feature맵에서의 명백한 blocking artifacts를 확인할 수 있다. 이는 기존의 Window partition 메커니즘에 의한 것으로, 이동된 window메커니즘이 Cross-window를 구성하는데에 비효과적임을 나타낸다. 따라서, Transformer 기반 모델에서 Channel attention을 조사하고, Cross-window 정보를 더 잘 수집하기 위해, Overlapping cross-attention모듈을 제안한다.
Network Archtecture
Overall Structure
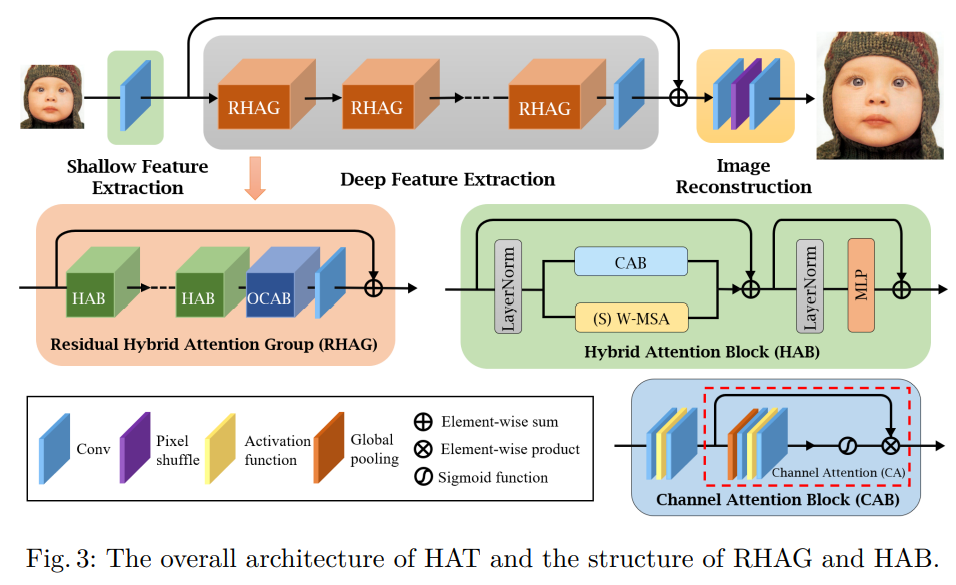
그림3에서 볼 수 있듯이, 전체 네트워크는 3가지 파트로 구성되어있다.
- 얕은 특징 추출 (Shallow feature extraction)
- 깊은 특징 추출 (Deep feature extraction)
- 이미지 재구성 (Image reconstruction)
구체적으로 먼저, 주어진 저해성도 입력 ILR에 대해 하나의 컨볼루션 레이어 HSF를 사용하여 얕은 피쳐 F0를 다음과 같이 추출한다.
얕은 특징 추출은 입력을 저차원 공간에서 고차원 공간으로 매핑하는 동시에, 각 픽셀 토큰에 대한 고차원 임베딩을 달성할 수 있다. 또, early convolution 레이어는 더 나은 시각적 표현을 학습하는데 도움이 되며, 안정적인 최적화로 이어질 수 있다. 이후, 깊은 특징추출 HDF를 수행하여 깊은 특징 FDF를 얻는다.
이때, HDF는 n개의 Residual Hybrid Attention Group (RHAG)와 하나의 3x3 컨볼루션 레이어 HConv로 구성되어있으며, 중간 feature를 다음과 같이 점진적으로 처리할 수 있다.