Author
David Baua,1 , Jun-Yan Zhua,b, Hendrik Strobeltc, Agata Lapedrizad,e, Bolei Zhouf, and Antonio Torralbaa
aComputer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA 02139; bAdobe Research, Adobe Inc.,
San Jose, CA 95110; cMassachusetts Institute of Technology–International Business Machines (IBM) Watson Artificial Intelligence Laboratory, Cambridge,
MA 02142; dMedia Lab, Massachusetts Institute of Technology, Cambridge, MA 02139; eEstudis d’Informatica, Multimedia i Telecomunicacio, Universitat ´
Oberta de Catalunya, 08018 Barcelona, Spain; and fDepartment of Information Engineering, The Chinese University of Hong Kong, Shatin, Hong Kong
SAR, China
Summary
Abstract
- 본 논문에서는, Classification 및 GAN 네트워크 내의 히든 유닛의 의미를 체계적으로 분석하기 위해 "네트워크 분해(Network Dissection)"를 제안한다.
- This paper represents the Network Dissection for identifying the role of individual units in a network by comparing the activity of each unit with a range of human-interpretable pattern-matching tasks such as the detection of object classes.
Intro
- 이미지 분류를 위해 훈련된 CNN(Convolution Neural Network)모델과 이미지 생성을 위한 GAN(Generative Adversarial Network) 모델을 네트워크 분해 프레임워크로 분석해본다. 네트워크 분해는 다양한 의미있는 객체 개념을 체계적으로 매핑하는 것이다.
- 마지막으로, classifier에 대한 적대적 공격(Adversarial attacks)을 이해하고, generator에 사람 유저에 의한 유닛 조작을 적용하여 나무, 문과 같은 개념을 조정할 수 있도록 한다.
Result
CNN
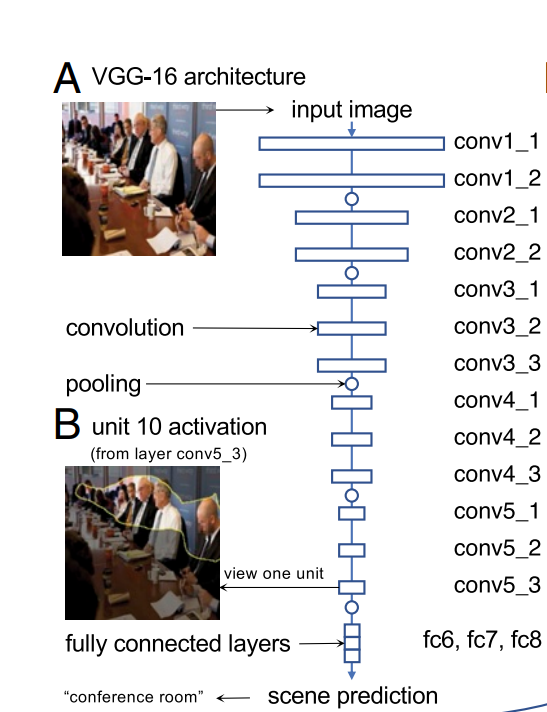
- VGG16 네트워크의 13개의 Conv 레이어를 분석하였다.
- 각 유닛 u는 테스트 이미지 x가 주어지면 모든 이미지 포지션 p에서 신호를 출력하는 활성화함수 au(xi,p)를 계산한다.
- 또한, au에 대한 상위 1%를 tu로 표시한다.
- 그림1-(a)는 입력으로 주어진 이미지 샘플이며, 1-(b)는 vgg16모델을 거친 후, 추출된 tu영역을 입력이미지에 표시한 것이다. 이때, tu영역은 사람의 머리부분 이라는 개념의 영역으로 볼 수 있다.
- IoU (Intersection Over Union) 비율은 유닛 u와 개념c의 일치도 비율을 표시한다.
- 여기서 Sc(x,p)는 컴퓨터비전 Segmentation 모델 Sc가 이미지 입력이 x일때, 포지션 p에서의 개념 c를 뜻한다.
- 또, Px,p는 p위치에서 x입력이 들어올 때의 이벤트가 참일 확을을 뜻한다.
- 즉, IoU는 p위치에서 x입력이 들어왔을 때, 모든 이벤트가 참일 때, 그 중 유닛u와 개념 c의 일치도가 상위 1%이상일 비율을 뜻한다.
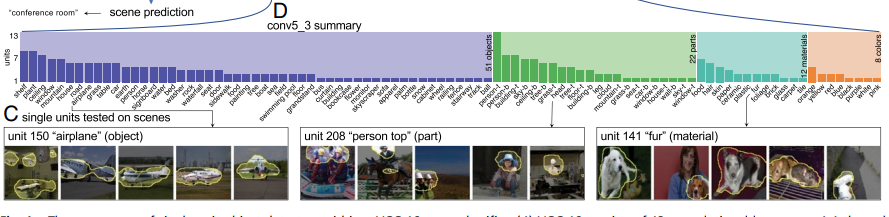
- 그림1-(c)는 입력된 이미지 샘플에서 가장 높은 IoU를 보인 개념과, 가장 높은 유닛활성도를 보인 5개의 이미지이다.
- 5개의 이미지를 살펴보면, 유닛들은 사람이 해석하는 시각적 개념과 잘 일치하는 영역에 높은 활성화를 보인 것 을 볼 수 있다.
- 그림1-(d)는 입력이미지에서 가장 마지막 레이어 conv5_3을 통과했을 때 검출된 개념 중에서, IoU가 4% 이상인 개념들을 시각화 한 것이다.
- 51개의 Objects, 22개의 Part, 12개의 materials, 8개의 colors로 다양한 개념들을 추출해 낸 것을 볼 수 있다.
- 참고로, 이미지가 Vgg16 아키텍처의 깊은 레이어로 들어갈 수록, 더 많은 개념들이 추출되고 있다.
- 재밌는 점은 훈련작업에서 명시적인 비행기 라벨이 없었음에도, 유닛은 비행기를 검출해냈으며, IoU=9% 가량 일치했다.
- 이번엔 반대로, 이미지 classifier에서 IoU가 가장 높았던 유닛이 0을 출력하도록 고정시키고 이미지를 분류해본다.
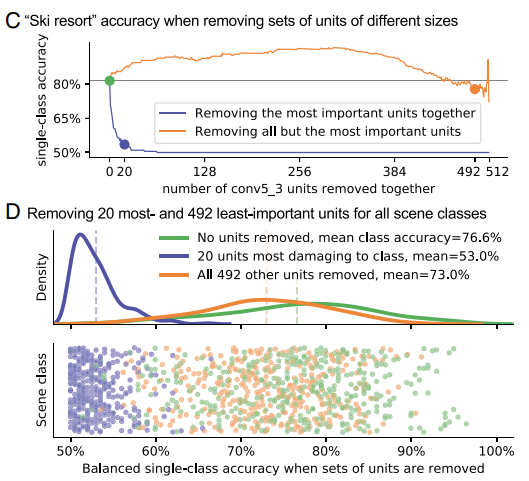
- 그림 2-(a)는 "ski resort"라벨이 있는 이미지셋들의 핵심 개념과 그 유닛이다.
- 그림2-(b)에서 보듯이 눈, 산꼭대기, 집, 나무꼭대기 개념에 높게 반응하는 유닛을 고정시키고 이미지 분류를 진행했을 때의 결과를 보여준다.
- 가장 중요한 유닛 4개를 제거했을 때, 정확도는 약 17.4% 감소했다. 또, 핵심 유닛 20개를 제거했을 때, 53.5%로 28.9% 정확도가 감소했다. 그러나 동시에 전체 정확도는 0.7%밖에는 감소하지 않았다. 이는, 다른 개념추출 능력에는 영향을 많이 끼치지 않았다는 뜻이다. 반대로, 중요하지 않는 유닛 492개를 고정하면, 정확도는 77.7%로 4개의 중요 유닛을 고정했을 때보다 정확도가 높게 나왔다. 동시에 전체 정확도는 2.1%로 크게 차이났다.
- 이는 결국, 개념을 추출하는 소수의 유닛이 네트워크의 단일 출력 클래스의 정확도에 대부분의 영향을 끼친다는 것을 말한다.
GAN
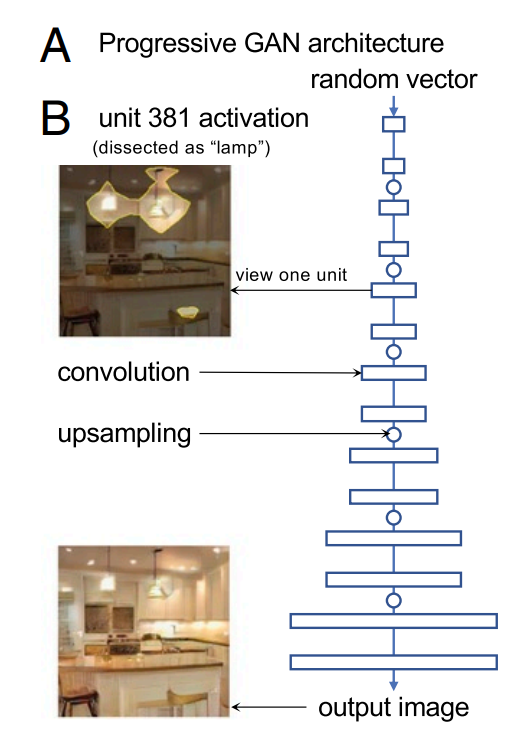
- GAN은 분류기의 반대로, 임의의 입력 벡터에서 현실적인 이미지를 생성한다. 분류기와 달리, 어떠한 인간의 지도 없이 네트워크는 이미지의 구조를 스스로 학습한다.
- 본 논문에서는 LSUN 주방 이미지로 학습된 Progressive GAN 아키텍터를 사용하였다. 총 15개의 Convolution layer로 이루어져 있으며, 최종적으로 256 x 256의 이미지를 생성한다.
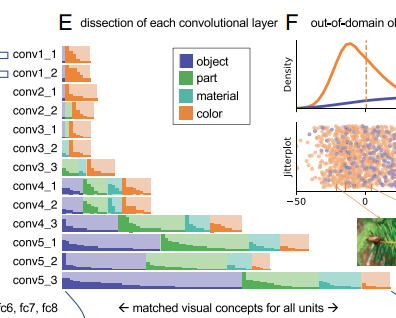
- 그림3-(b)는 그림1-(a)와 마찬가지로, 상위 1%수준(tu) 이상으로 활성화되는 영역을 표시한다. 그러나 분류기때와는 반대로, 필터의 활성화가 이미지 생성 전에 일어났기 때문에, 이미지의 개념을 검출한 것이 아니라, 최종적으로 객체를 랜더링하는 계산의 일부이다.
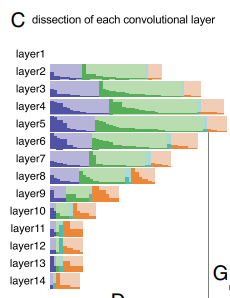
- GAN에서는 입력 데이터에서 나타나는 객체와의 일치여부를 분석하는 대신, 생성된 출력 이미지에서 분한된 객체와의 일치 여부를 분석한다. 따라서, 그림 3-(c)에서 볼 수 있듯이, 아키텍처 끝이 아닌 중간에서 높게 활성화된 유닛들이 많이 존재함을 볼 수 있다.
- 그림3-(d)는 IoU가 4%이상인 각 유닛과 일치하는 개념을 보여준다. CNN과 다른점은, 객체보다 객체의 부분을 더 많이 추출했다는 것이다.
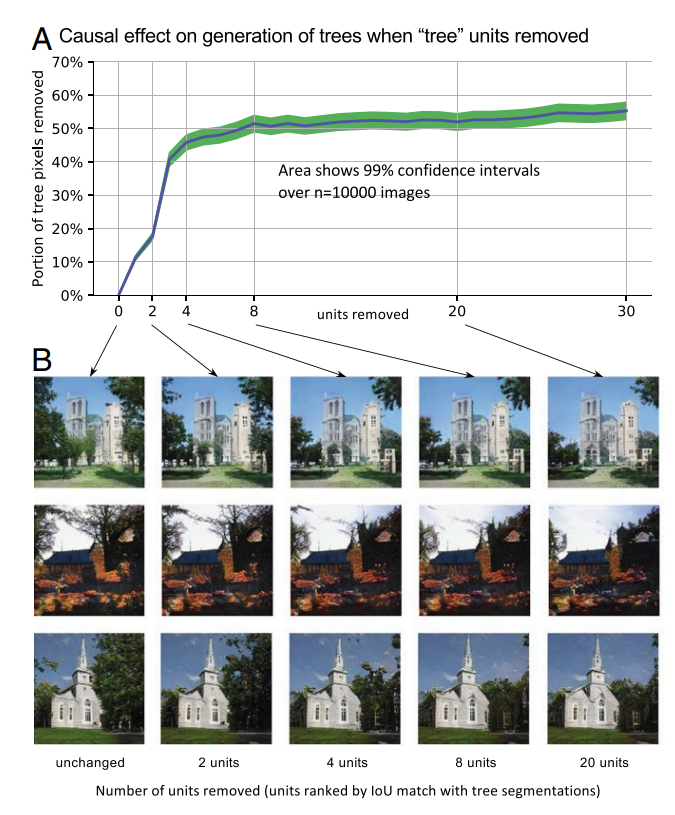
- 또, Progressive GAN에서 나무를 추출하는 유닛을 제거해보았다. 4개를 제어했을 때, 나무는 적거나, 작은 이미지를 생성했고, 20개를 제거했을 때는 모든 이미지에서 나무 픽셀 수가 53.3%감소했다.
- 그러나, 전체 이미지는 여전히 잘 생성되엇다. 오히려, 나무에 가려진 부분이 보이는 것 처럼 창문과 벽 특징이 생성되었다.
- 이를 통해 GAN은 한쪽에서 보는 카메라의 구도(시각적 픽셀 패턴)외에도 구조적 통계 모델을 배우고 있다는 것을 의미한다.
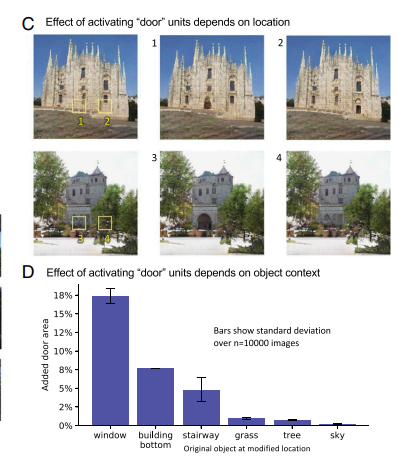
- 반대로, 이미지에 새로운 객체를 추가하는데도 사용할 수 있다.
- 문을 분류할 때 가장 높은 활성화를 보인 20개의 높게 활성된 유닛을 높은 tu값으로 강제하면 그림3-(c)와 같이 문이 없는 자리에 문을 생성할 수 있다. 또한, 이미지에 맞는 크기 및 스타일을 가지고 있다.
- 그림3-(d)를 보면, 문은 창문위치에서 가장 많이 생성되었고, 하늘에서는 잘 생성되지 않았다. 사람의 지도가 없었지만, GAN이 문을 생성할 수 있는 위치를 학습한 것이다. GAN이 이미지의 문맥을 고려하여 새로운 객체를 생성하는 것을 학습했다는 의미이다.
The adversarial attack
- 적대적 공격 알고리즘은 원본 이미지에 작은 왜곡을 더하여 오분류가 일어나게 하는 공격이다.
Semantic Painting Using a GAN
- 네트워크 내의 유닛들이 개념단위로 활성화를 보인다는 것을 이용하여, 유닛을 직접 조작해 이미지 객체를 조정하는 대화형 인터페이스를 생성하였다. 객체를 추가하면, 그에따른 유닛이 활성화되고, 객체를 삭제하면, 유닛이 낮은값으로 고정된다. 그림6에서 보다시피 뾰족한 첨탑을 돔 형태로 자연스럽게 바꾼 결과를 볼 수 있다.
Discussion
- 일반적인 Accuracy와 같은 간단한 성능 측정은 네트워크가 어떻게 작업을 수행하는지를 나타내지는 못한다. 따라서, 네트워크의 개별 유닛들의 역할을 분석하여 네트워크가 어떻게 작업을 수행하는지 분석해보았다.
- 네트워크 해부는 기본적으로 인간이 이해할 수 있는 개념을 추출하는 유닛을 기반으로 한다.
- 결론적으로, 개별 유닛의 체계적인 분석은 딥러닝 네트워크의 블랙박스구조에 대한 통찰력을 제공한다.
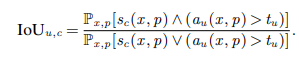



Strengths
- 네트워크 분해 프레임워크를 통해, CNN과 GAN의 아키텍처 속 유닛들의 역할이 무엇인지, 또, 그 역할이 사람이 이해할 수 있는 개념 단위인것을 확인했다.
- 또한, 각 유닛을 낮게 또는 높게 고정시킴으로써 결과에 직접적으로 어떤 영향을 미치는지 실험을 통해 확인하였다.
- 이 논문을 통해, 이후 특정 개체를 분류해야 하는 Classification의 중요 유닛을 분석하여 성능을 더욱 높힐 수 있게될 것이다.
- 또, GAN모델의 경우, 예시를 보였던 것 처럼 인간과 상호작용하여, 더 효과적으로 원하는 이미지를 생성하는 GAN모델을 구현할 수 있게될 것이다.
Weaknesses
- Discussion에서 언급했듯이, 이 네트워크 분해는 인간이 이해할 수 있는 개념을 추출하는 유닛들을 기반으로 분석이 진행되었다. 그러나, 딥러닝모델의 동작은 블랙박스이며, 인간이 이해하지 못하는 개념을 추출하는 유닛들도 분명히 존재할 것이다. 그러한 사람이 이해하지 못하는 개념을 추출하는 유닛에게도 조명을 비춰주었으면 더 풍부한 논문이 될것이라 생각한다.
My thoghts to improve
- 본 논문은 활성화가 tu수준 이상인, 높은 활성도의 유닛의 영향력을 계산했고, 기대하는대로 결과도 눈에 띄게 달라지는 것을 확인할 수 있었다. 결국 특정 클래스의 정확도가 모든 클래스의 정확도까지 떨어졌음을 확인했다. 그렇다면, tu수준 이상인 유닛만 남기고 활성도가 낮은 유닛들을 0 또는 낮은 값으로 고정시킨 후, Classification, GAN을 작동한다면, 낮은 활성도의 유닛들의 역할도 확인할 수 있었지 않았나 궁금해진다.
만약, 낮은 값의 활성도를 가진 유닛들이 전에 모델의 성능에 중요하지 않은 역할을 한다면, 0으로 고정시키고 높은 유닛만 사용하는 모델 경량화도 가능하게 될 것이다. 예를 들어, Akhter, Sharmen, et al. "NeuRes: Highly Activated Neurons Responses Transfer via Distilling Sparse Activation Maps." IEEE Access 10 (2022): 131555-131566. 에서는 특징맵을 Scale하고 shift한 후, ReLU 활성화 함수를 거쳐 높게 활성화된 유닛만 추출하여 지식증류를 진행하여 좋은 성능을 보였다고 한다. 이와 같이 feature 추출의 핵심적인 유닛을 추출해내어 효과적인 모델의 훈련 및 성능증강을 이뤄낼 수 있지 않을 까 생각한다.Takeaways
- 블랙박스 라고만 생각했던 딥러닝 아키텍처 내부에 대해 최소 작동 단위인 유닛의 관점으로 분석한 것이 흥미로웠고, 단순 4~20개의 유닛의 조작만으로도 직접적인 결과의 변화로 이어지는 것이 놀라웠다.
- 또한, GAN 모델이 이미지를 단순 평면이 아닌 구조적으로 이해하고 있다는 것에 대한 간단한 증명을 본 것 같았다.
Other comments

Talking Potato