시계열 데이터 처리
앞으로 LSTM을 공부하는 기록을 남길 것이며, 오늘은 모든 AI 모델 개발에서 첫 단계인 데이터 준비를 해볼 것이다.
데이터 불러오기 및 확인
- 준비한 데이터는 기온과 습도를 수집하는 IoT센서와, CO2, CO 정보를 수집하는 센서의 데이터를 병합한 데이터이다.
- 이를 통해 기온을 예측하는 LSTM 모델을 만들어보도록 한다.
- 기온과 습도를 수집하는 센서는 2초 간격으로 데이터를 수집한다.
- CO2, CO를 수집하는 센서는 3초 간격으로 데이터를 수집한다.
- 따라서, NaN값이 매우 많고, 각 센서들이 불안정하기 때문에 데이터에 큰 공백도 존재한다.
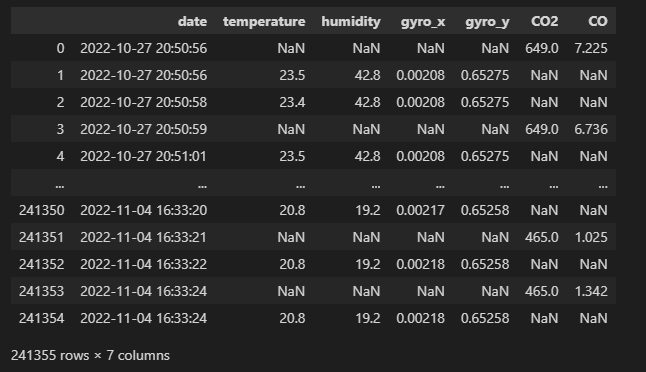
import pandas as pd df = pd.read_csv('D:/개인공부/LSTM/testdata_202211081352.csv', index_col=0) df
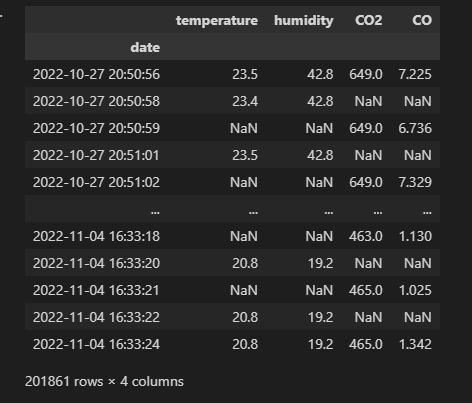
- 두 센서 데이터가 동시에 들어온 경우 합쳐지지 않고 두개의 행으로 되어있다. 이를 groupby로 묶어준다.
- 또, gyro 데이터는 기기의 gyro정보이기 때문에 제거한다.
df = df.groupby(by='date').mean() df = df.drop(['gyro_x', 'gyro_y'], axis=1) # 이상치 탐지 결과를 담을 DataFrame result_df = pd.DataFrame() result_df['original'] = df['temperature'] df
- 그럼에도 불구하고 결측치가 매우 많은 것을 볼 수 있다.
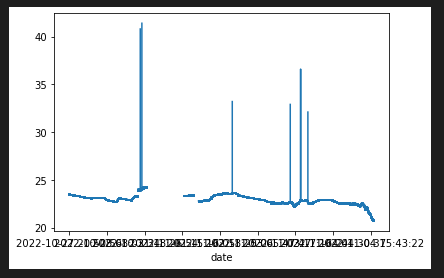
- 그래프로 확인해보자
df['temperature'].plot()
- 데이터에 이상치가 존재하며, 네트워크 문제로 인한 큰 공백이 존재한다.
- 이러한 결측치를 버려야하나 채워야하나...
이상치 제거
- 먼저 이상치 제거를 해보도록 한다. 이상치를 제거하기 위한 알고리즘은 다음과 같다.
- 또, 눈으로 보기 쉽게하기 위해 이상치는 mean값으로 바꾸도록 하겠다.
이상치 감지 방법론
- IQR Rule-based Anomaly Detection
- STL 분해
- 분류 및 회귀 트리 (CART)
- 클러스터링 기반 이상 탐지
- 오토 인코더
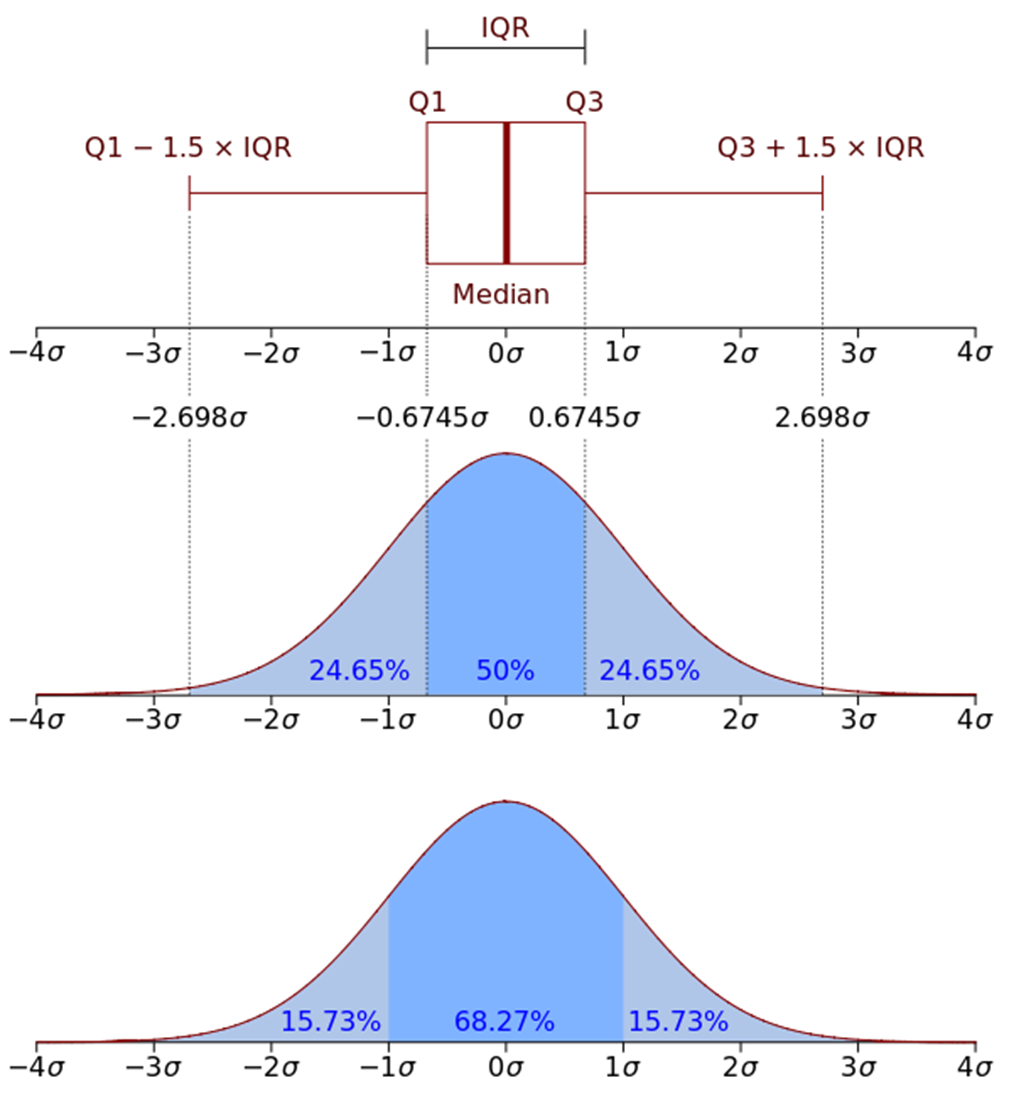
IQR Rule-based Anomaly Detection
데이터 분포의 약 25% 지점을 Q1, 약 75%의 지점을 Q3로 가정하고, 이 사이 거리를 IQR(Inter Quantile Range)이라고 한다.
IQR에 상수(예 1.5)를 곱하여, Q1-IQR상수를 최솟값, Q3+IQR상수를 최대값으로 정한다.
그 범위를 이상치로 판단하는 것이 IQR 이상치 탐지이다.
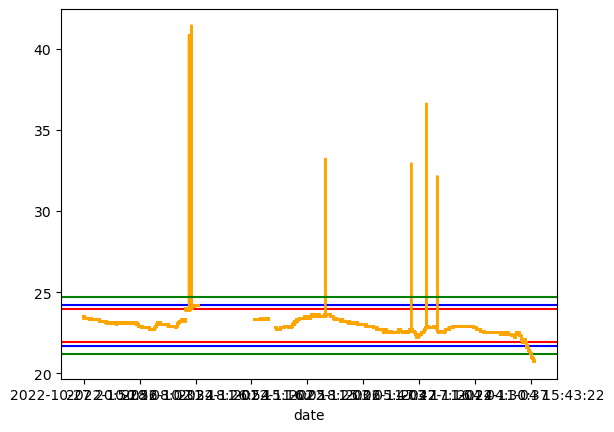
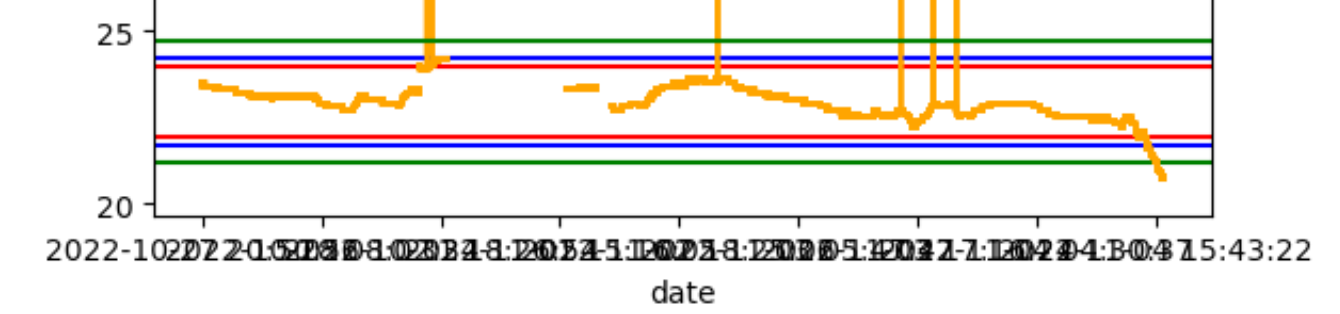
import matplotlib.pyplot as plt def IQR(df, col, constance=1.5): describe = df.describe()['temperature'] Q1 = describe['25%'] Q3 = describe['75%'] IQR = Q3 - Q1 lower = Q1 - IQR*constance higher = Q3 + IQR*constance print(Q1, Q3, IQR, lower, higher) return lower, higher constances = [1.5, 2, 3] colors = ['red', 'blue', 'green'] for idx, opt in enumerate(zip(constances, colors)): con, col = opt lower, higher = IQR(df, 'temperature', con) df['temperature'].plot(color='orange').axhline(y=lower, color=col) df['temperature'].plot(color='orange').axhline(y=higher, color=col)
- 상수를 1.5, 2, 3 으로 다르게 주었을 때의 그래프이다.
- 값이 기준보다 높은 이상치는 잘 걸려졌지만, 값이 기준보다 낮은 이상치에서 정상 값으로 보이는 값들이 걸려졌다.
- 물론 상수를 더욱 크게하면 모두 포함시킬 수 있겠지만, 이 경우가 아닌 다른 경우에서도 좋은 방법일지는 알 수 없다.
STL 분해
- 0STL은 시계열 데이터를 Seasonal(계절성), Trend(추세), Residual(잔차) 이 세 요소로 분할한다.
!pip install statsmodels
- 먼저 statsmodels 모듈을 설치해 준다.
from statsmodels.tsa.seasonal import seasonal_decompose result = seasonal_decompose(df, model='additive') result.plot()
- 에러! 데이터네 NaN값이 있거나 시계열 데이터가 충분히 연속적인 경우만 사용할 수 있다.
- 현재 데이터는 NaN값이 존재하며, 연속적이지 않습니다. 따라서 이 모듈을 사용하지 못할 것이다.
- 따라서 이 STL 분해 방법은 다른 데이터로 사용해보도록 하겠다.
- https://drive.google.com/drive/folders/1vsLzhpgNbVPsYvBIFNI_20S3LRZuNYhz
test_df = pd.read_csv('catfish.csv') test_df
- 1986년부터 매월 1일 Catfish(메기)가 얼마나 잡혔는지에 대한 기록인 것 같다.
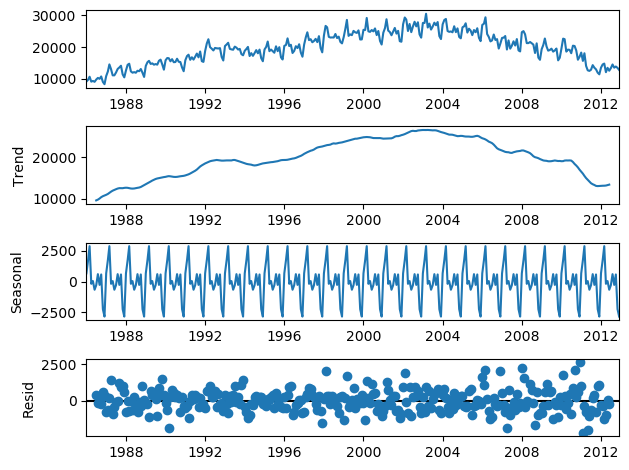
from datetime import datetime from statsmodels.tsa.seasonal import seasonal_decompose time_form = "%Y-%m-%d" test_df = pd.read_csv('catfish.csv') test_df['Date'] = test_df['Date'].apply((lambda x: datetime.strptime(x, time_form))) test_df = test_df.set_index('Date') result = seasonal_decompose(test_df, model='additive') result.plot()
- Date 컬럼을 datetime형식으로 바꿔주고, 인덱스로 넣어준다.
- statsmodels 모듈은 인덱스가 datetime형식의 날짜가 빠짐없이 연속으로 존재해야 시계열 분리를 해준다. 또, NaN값이 존재하지 않아야 한다.
- Seasonal, Trend, Residual 이 세가지 요소로 잘 분리된 것을 볼 수 있다.
- 여기서 Residual(잔차)의 편차를 분석하고 이에대한 Threshold를 도입하면 이상 탐지 알고리즘을 얻을 수 있습니다.
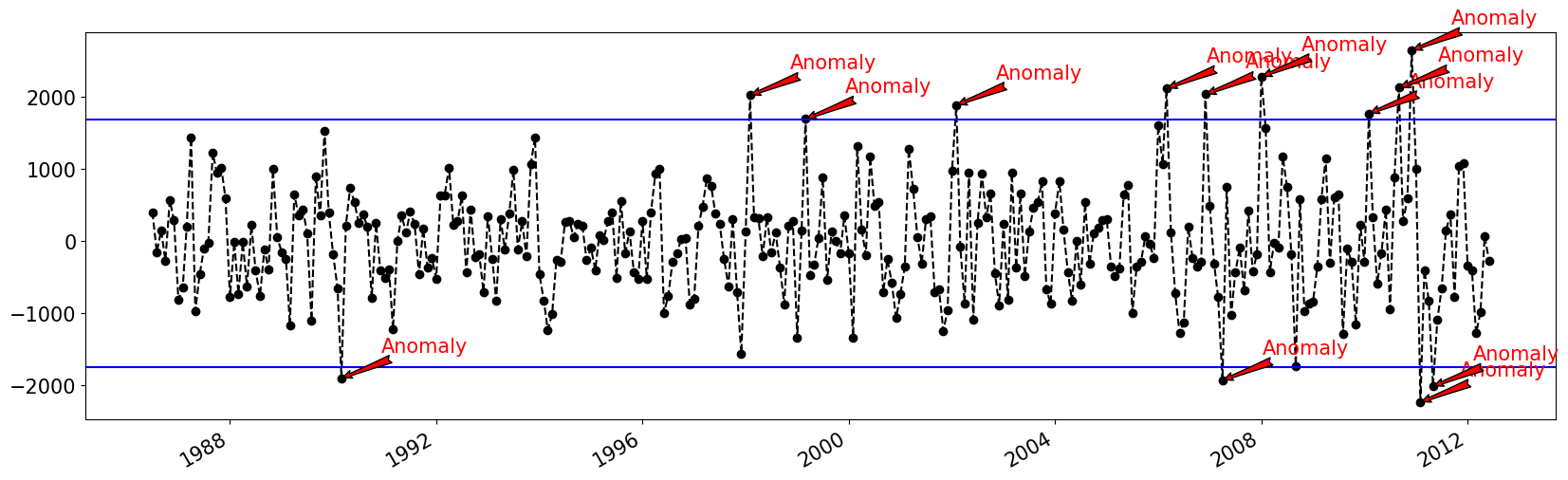
import matplotlib.dates as mdates import numpy as np plt.rc('figure',figsize=(20,6)) plt.rc('font',size=15) fig, ax = plt.subplots() # 앞 뒤 6개 수에 NaN값이 들어가 있다. x = result.resid.index[6:-6] y = result.resid.values[6:-6] ax.plot_date(x, y, color='black',linestyle='--')\ Q1 = np.percentile(y, 25) Q3 = np.percentile(y, 75) IQR = Q3 - Q1 IQR = IQR if IQR > 0 else -1*IQR lower = Q1 - 1.5*IQR higher = Q3 + 1.5*IQR ax.axhline(y=lower, color='blue') ax.axhline(y=higher, color='blue') for i in range(len(y)): if y[i] < lower or y[i] > higher: ax.annotate('Anomaly', (mdates.date2num(x[i]), y[i]), xytext=(30, 20), textcoords='offset points', color='red',arrowprops=dict(facecolor='red',arrowstyle='fancy')) fig.autofmt_xdate() plt.show()
- Residual의 값을 그래프로 표현하고, 값을 IQR방식을 이용해 이상치를 탐지했다.
- 이번엔 np.percentile모듈을 사용해 Q1과 Q3를 찾았으며, 상수는 1.5를 사용했다.
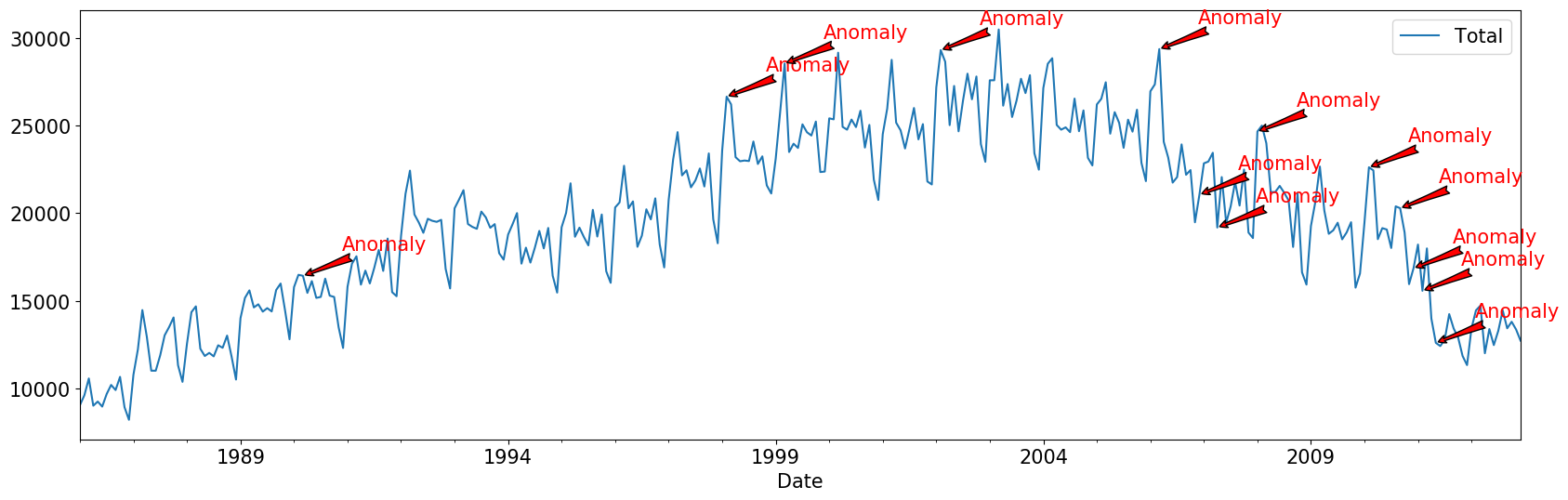
ax = test_df.plot() plt.rc('figure',figsize=(20,6)) plt.rc('font',size=15) for i in range(len(y)): if y[i] < lower or y[i] > higher: ax.annotate('Anomaly', (test_df.iloc[i].name, test_df.iloc[i]['Total']), xytext=(30, 20), textcoords='offset points', color='red',arrowprops=dict(facecolor='red',arrowstyle='fancy')) fig.autofmt_xdate() plt.show()
- 이상치의 인덱스를 실제 데이터에서 표현한 것이다.
- 눈으로 확인 했을 때, 이값들이 왜 이상치인지 알기 힘들다.
장점
- 매우 간단하고, 다양한 상황을 처리할 수 있으며, 모든 이상 현상을 눈으로 확인하고 직관적으로 해석 할 수 있다.
단점
- 가장 큰 단점은 엄격한 조정 옵션dl다. Threchold, 신뢰 구간을 빼면, 다른 일을 할 수 없다.
- 예를 들어, 비공개상태에서 갑자기 공개상태로 열린 웹사이트의 사용자를 추적한다면, 이 경우 출시 기간 전후에 발생하는 이상 현상을 별도로 추적해야 한다.

분류 및 회귀 트리 (CART)
- 의사결정나무의 강력함과 견고함을 활용하여 시계열 데이터에서 이상치/이상을 식별한다.
- 먼저, 지도학습을 사용하여, 트리에서 비정상 데이터 포인트와 비이상 데이터 포인트를 분류하도록 학습시킬 수 있다. 그러나, 이를위해서는 따로 데이터 셋이 존재해야 한다.
- 우리는 레이블이 지정되지 않은 데이터 세트의 도움 없이 Isolation Forest 알고리즘을 사용하여 특정 값이 이상값인지 확인할 수 있다.
- 즉, Isolation Forest는 이상치가 소수의 특이한 데이터임을 고려하여, 거리 또는 밀도 측정을 사용하지 않고, 이상치를 격리한다.
- 값이 정상일 경우
1, 이상치일 경우-1를 반환할 것이다.import pandas as pd cast_df = pd.read_csv('catfish.csv', index_col=0) cast_df.plot()
- 다시 catfish_sales 데이터를 사용한다.
from sklearn.preprocessing import StandardScaler from sklearn.ensemble import IsolationForest outliers_fraction = float(.01) scaler = StandardScaler() np_scaled = scaler.fit_transform(cast_df.values.reshape(-1, 1)) cast_scaled_df = pd.DataFrame(np_scaled) model = IsolationForest(contamination=outliers_fraction) model.fit(cast_scaled_df) cast_df['anomaly'] = model.predict(cast_scaled_df)
- scikit-learn 모듈의 StrandardScaler로 표준편차 모양으로 그래프를 scaling해주고, Isolation Forest로 학습시켜준다.
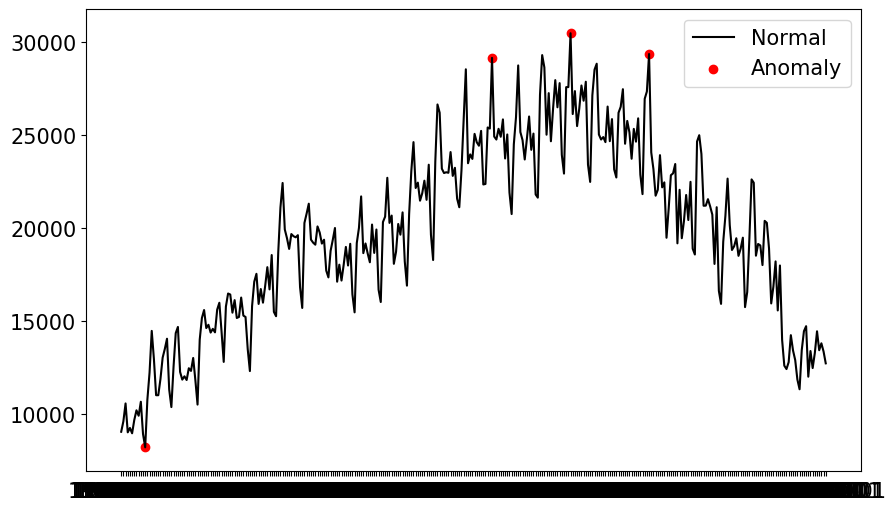
#시각화 fig, ax = plt.subplots(figsize=(10,6)) a = cast_df.loc[cast_df['anomaly'] == -1, ['Total']] #anomaly ax.plot(cast_df.index, cast_df['Total'], color='black', label = 'Normal') ax.scatter(a.index,a['Total'], color='red', label = 'Anomaly') plt.legend() plt.show()
- 빨간 점으로 이상치가 출력되었다.
- IQR 방법과 달리 전체의 평균값을 쓰지 않기 때문에 시각적으로 확인했을 떄, 정상적인 값들은 유지하면서, 이상치만 잘 걸러내었다.
장점
- 이 기술의 큰 장점은 더 정교한 모델을 만들기 위해 여러 조정을 할 수 있다는 것이다.
단점
- 그러나 이 여러 조정, 더 많은 기능이 계산성능에 영향을 미칠 수 있다는 것이다.
클러스터링 기반 이상 탐지
- 이상치는 다른 기존 값들과는 다르게 특징이 있으며 소수인 특징을 이용해 클러스터링 기반 이상탐지를 하는 방법이다.
- K-means 클러스터링 알고리즘을 사용한다.
- 시각화를 위해 하나 이상의 시간 기반 변수가 있는 다변수 시계열에 해당하는 다른 데이터 세트를 사용한다.
- https://www.kaggle.com/datasets/aslanahmedov/walmart-sales-forecast?select=test.csv
- 캐글, 월마트 판매 예측 데이터
데이터 전처리
- 데이터는 매장번호, 부서번호, 주간매출, 공휴일 여부의 컬럼이 존재한다. 여기서 한 매장의 전체 주간매출 데이터로 변환하여 사용한다.
import pandas as pd clust_df = pd.read_csv('/Walmart/train.csv') clust_df = clust_df[clust_df['Store']==1].drop(['Store', 'Dept'], axis=1) clust_df = clust_df.groupby(by='Date').sum() clust_df['IsHoliday'] = clust_df['IsHoliday'].apply(lambda x: 1 if x else 0) clust_df
- 위 데이터로 클러스터링을 진행해 본다.
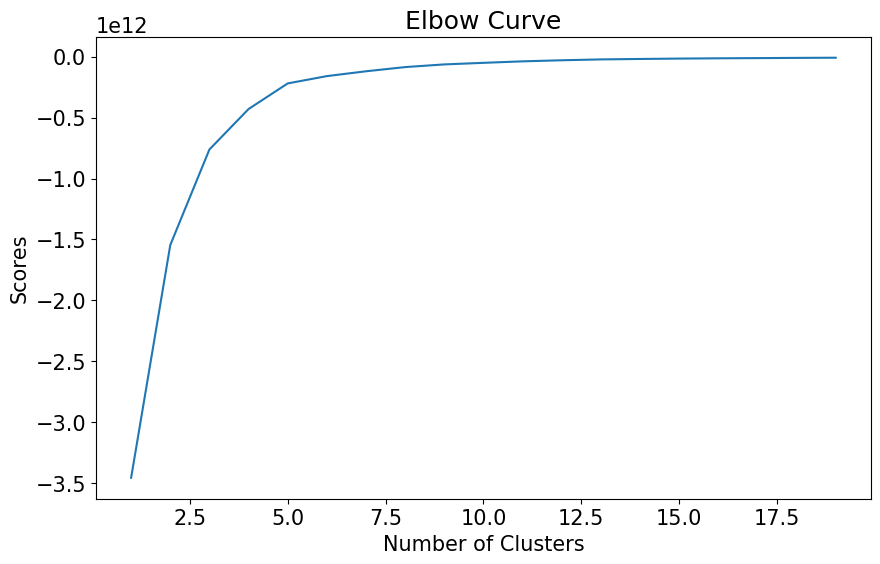
from sklearn.cluster import KMeans n_cluster = list(range(1, 20)) kmeans = [KMeans(n_clusters=i).fit(clust_df) for i in n_cluster] scores = [kmeans[i].score(clust_df) for i in range(len(kmeans))] fig, ax = plt.subplots(figsize=(10, 6)) ax.plot(n_cluster, scores) plt.xlabel('Number of Clusters') plt.ylabel('Scores') plt.title('Elbow Curve') plt.show()
- 클러스터가 5개 이후에 score가 거의 평행이 된다. 이는 더 많은 클러스터를 생성한다고 해도, 관련 변수의 분산을 더 잘 설명하지 못한다는 뜻이다.
- 따라서, n_cluster를 5으로 정한다.
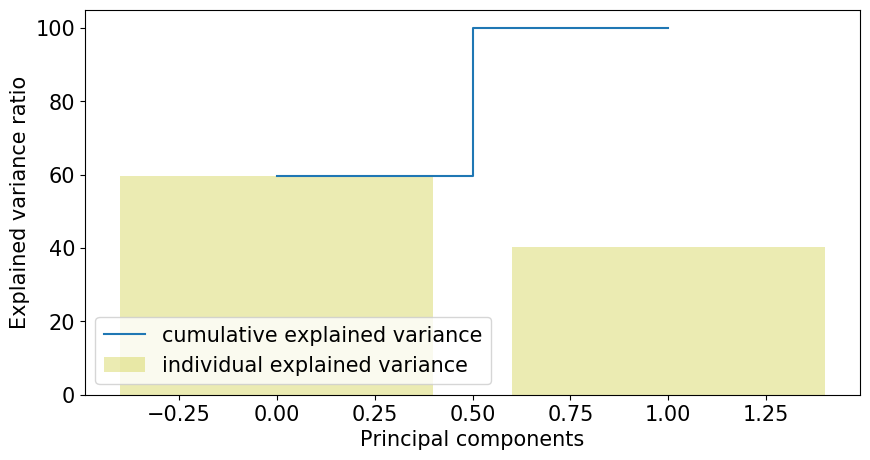
X = clust_df.values X_std = StandardScaler().fit_transform(X) # 공분산 행렬에 대한 아이겐벡터, 아이겐밸류 계산 # 공분산(2개의 확률 변수의 선형 관계) mean_vec = np.mean(X_std, axis=0) cov_mat = np.cov(X_std.T) eig_vals, eig_vecs = np.linalg.eig(cov_mat) # (아이겐벡터, 아이겐밸류)들의 리스트 생성 eig_pairs = [ (np.abs(eig_vals[i]),eig_vecs[:,i]) for i in range(len(eig_vals))] eig_pairs.sort(key = lambda x: x[0], reverse= True) # 아이겐밸류로부터 설명 가능한 공분산 계산 tot = sum(eig_vals) var_exp = [(i/tot)*100 for i in sorted(eig_vals, reverse=True)] # 각각의 공분산 cum_var_exp = np.cumsum(var_exp) # 누적된 공분산 plt.figure(figsize=(10, 5)) plt.bar(range(len(var_exp)), var_exp, alpha=0.3, align='center', label='individual explained variance', color = 'y') plt.step(range(len(cum_var_exp)), cum_var_exp, where='mid',label='cumulative explained variance') plt.ylabel('Explained variance ratio') plt.xlabel('Principal components') plt.legend(loc='best') plt.show();
- 그래프를 보면, 첫번째 성분이 60%의 공분산을 설명하는 것을 볼 수 있다. 또, 두번 쨰 성분은 40%의 공분산을 설명한다.
- 클러스터링 기반 이상치 감지의 기본 가정은, 정상 데이터는 클러스터에 속하지만, 이상치는 클러스터에 속하지 않거나 작은 클러스터에 속한다는 것 입니다.
이상치 찾기
- 각 점과 가장 가까운 중심 사이 거리 계산, 가장 큰 거리는 이상으로 간주
- Isolation Forest와 유사하게 outliers_fraction을 사용하여 이상값의 비율에 대한 정보 제공. 시작수치로 0.1부터 사용해본다.
- outliers_fraction을 사용하여 number_of_outlier 계산
- Threshold값을 이상값의 최소거리로 설정
- 0: normal, 1: anomaly
- 시각화
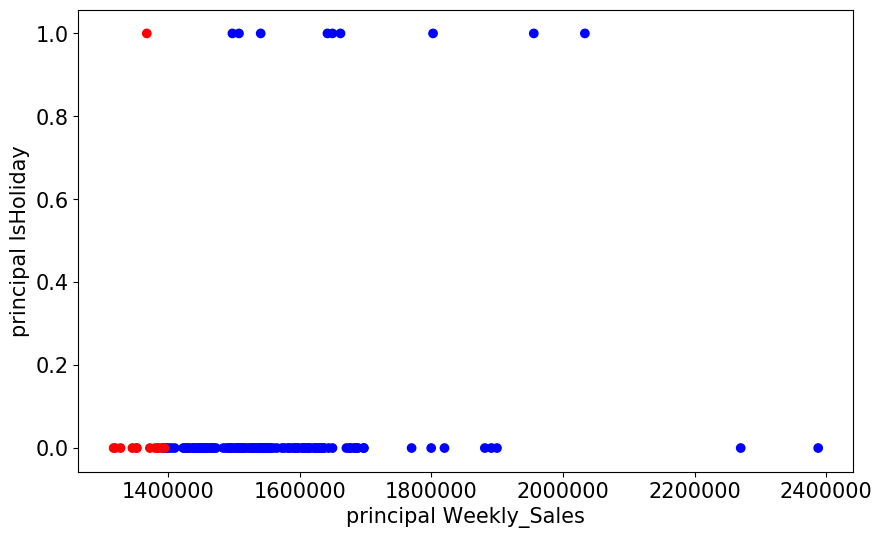
# 각 포인트 사이의 점과 가장 가까운 센트로이드로 이루어진 Series를 반환한다. def getDistanceByPoint(data, model): distance = pd.Series() for i in range(0,len(data)): Xa = np.array(data.iloc[i]) Xb = model.cluster_centers_[model.labels_[i]-1] distance.at[i]=np.linalg.norm(Xa-Xb) return distance outliers_fraction = 0.1 # 각 점사이의 거리와 가장 가까운 센트로이드 얻기. # 가장 먼 거리에 있는 값은 이상치라고 생각할 수 있다. distance = getDistanceByPoint(clust_df, kmeans[5]) number_of_outliers = int(outliers_fraction*len(distance)) threshold = distance.nlargest(number_of_outliers).min() # anomaly1 은 Cluster에서 벗어난 이상치결과들을 포함한다. (0:normal, 1:anomaly) clust_df['anomaly1'] = (distance >= threshold).astype(int).values fig, ax = plt.subplots(figsize=(10,6)) colors = {0:'blue', 1:'red'} ax.scatter(clust_df['Weekly_Sales'], clust_df['IsHoliday'], c=clust_df["anomaly1"].apply(lambda x: colors[x])) plt.xlabel('principal Weekly_Sales') plt.ylabel('principal IsHoliday') plt.show()
- 현재 주간 매출 값 외의 다른 변수가
IsHoliday이며, 0과 1만 존재하기 때문에 그래프가 0과 1에만 그려진 것을 볼 수 있다.- 또, 이상치는 빨간색으로 칠해져 있다.

Talking Potato
안녕하세요 혹시 LSTM/testdata_202211081352.csv은 어디서 구할 수 있나요?