다음과 같은 테이블을 생성하고, 데이터를 입력하도록 합니다.
#스크립트에서 schema단위는 빠져 있습니다.
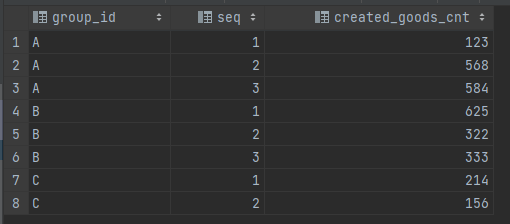
rows_sql_test
create table rows_sql_test
(
group_id varchar(10),
seq int,
created_goods_cnt int
);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('A', 1, 123);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('A', 2, 568);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('A', 3, 584);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('B', 1, 625);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('B', 2, 322);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('B', 3, 333);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('C', 1, 214);
INSERT INTO rows_sql_test (group_id, seq, created_goods_cnt) VALUES ('C', 2, 156);이렇게 만들고 실습을 시작 하도록 하겠습니다.
over() 함수 사용해 보기
over() 함수를 이용해서 group by 하지 않고 어떤 값을 기준으로한 합이나, 카운트, min, max, avg 등의 집계 함수값을 구해서 일반 데이터와 함께 출력 할 수 있습니다. 다음과 같이 말이죠!
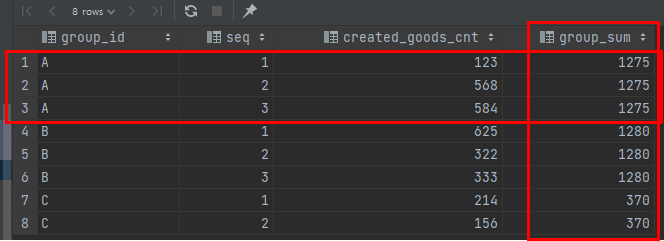
rows_sql_test
자, 위 그림을 보면 group_sum이라는것은 원래 있던 데이터가 아닙니다.이건, group_id 값이 같은것 끼리 created_goods_cnt의 값을 합친값이죠.그럼 이걸로 seq에 따라 전체값에서 어떤 값이 가지는 비율도 구할 수 있습니다.다음과 같이 말이죠.
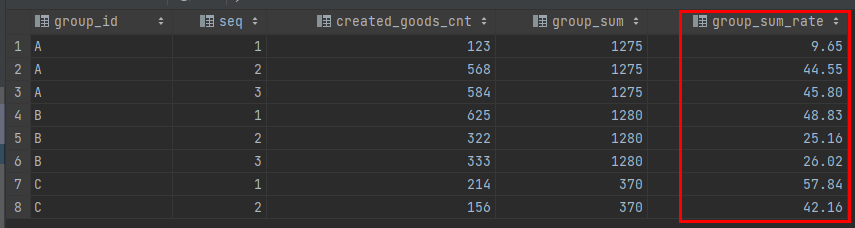
rows_sql_test
이렇게 출력 하기 위해서 over() 함수가 들어간 sql이 필요합니다.
위와 같이 출력하는 SQL은 다음과 같이 구현 할 수 있습니다.
select a.*
, sum(created_goods_cnt) over (partition by group_id) group_sum
, round(created_goods_cnt / sum(created_goods_cnt)
over (partition by group_id) * 100, 2) group_sum_rate
from rows_sql_test a보이시나요? sum(created_goods_cnt) over (partition by group_id) 바로 이부분이 핵심 입니다.이 구문을 통해서 부분합이 group_id 별로 파티셔닝되어 합쳐지고, 거기에 따른 created_goods_cnt 컬럼의 값을 더하는 것이 되죠. 이해가 되시나요?
이걸 seq 수 별로 한다면 partition by 뒤에 seq 컬럼을 넣으면 되겠죠!
이런 방법으로 다음과 같이 다양한 값을 구할 수 있습니다.

sql은 다음과 같이 구현을 했습니다.업무에 참고 하시기 바랍니다.
select a.*
, sum(created_goods_cnt) over (partition by group_id) group_sum
, min(created_goods_cnt) over (partition by group_id) group_min
, count(created_goods_cnt) over (partition by group_id) group_count
, max(created_goods_cnt) over (partition by group_id) group_max
, avg(created_goods_cnt) over (partition by group_id) group_avg
, round(created_goods_cnt / sum(created_goods_cnt) over (partition by group_id) * 100, 2) group_sum_rate
from rows_sql_test a.jpg)
어제 보다는 내일을, 내일 보다는 오늘을 🚀