
2-1 강 / 0과 1로 숫자를 표현하는 방법
비트(bit) : 컴퓨터가 이해하는 가장 작은 정보단위(0, 1을 표현)

- 즉! n개의 비트는 2^n개의 정보를 표현할 수 있다!
정보단위

🎇 정보단위 중 워드(word)는 CPU가 한번에 처리할 수 있는 데이터의 크기를 의미!
EX) CPU 16비트를 한 번에 처리할 수 있따면 1 WORD = 16 bit! 요즘 대부분 컴퓨터의 워드 크기는 32비트 또는 64비트!
이진법

예로들어 이진수 10의 표기는 1010(2), 코드로는 0B1010
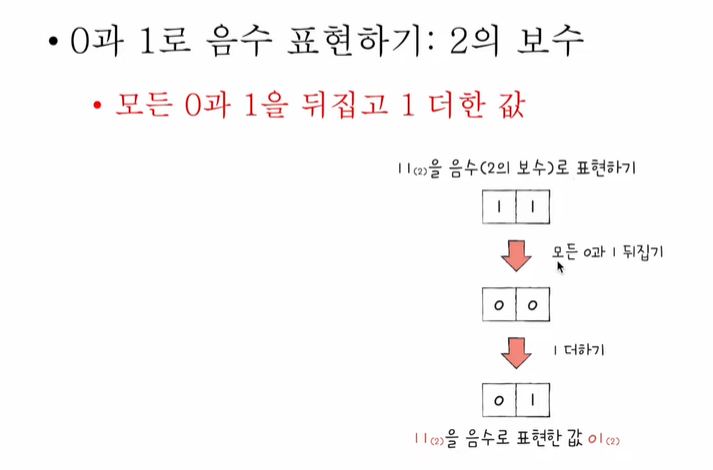
🎇 이진수는 음수를 표현할때 2의 보수 법을 통해 표현한다!
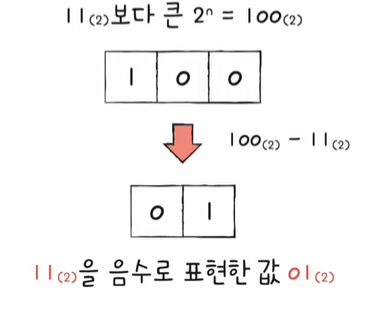
보수법은 어떤 수를 그보다 큰 2^n에서 뺀 값
조금더 쉬운 방법은!
하지만 음수를 표현한 보수법에 이러한 의문이 든다!!

플래그 레지스터 = cpu 내부의 특별한 레지스터가 수가 음수인지 양수인지 알고있음.
즉, 모든 숫자가 플래그를 들고 있음.

🎇 BUT!! 2의 보수 표현의 한계가 있음!
EX1) 0을 음수로 표현하기. 0000 -> 10000 /// 0의 음수표현(?)
EX2) 8을 음수로 표현하기. 1000 -> 1000 /// (?) 동일한데?
즉, 0이나 2^n형태의 이진수에 보수법을 취하면 원하는 형태의 음수값을 얻을 수가 없다!.
16진법

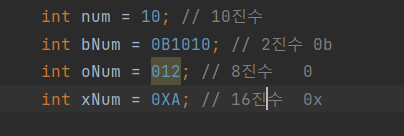
- 적은 자릿수로 많은 정보를 표현 할 수 있다!

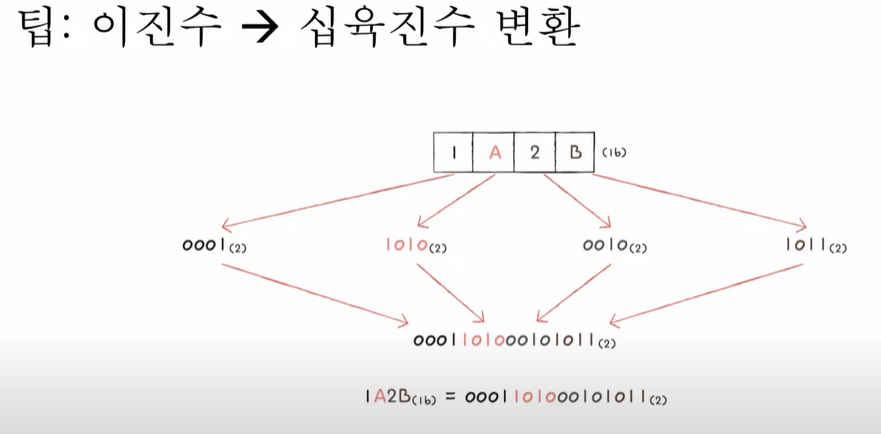
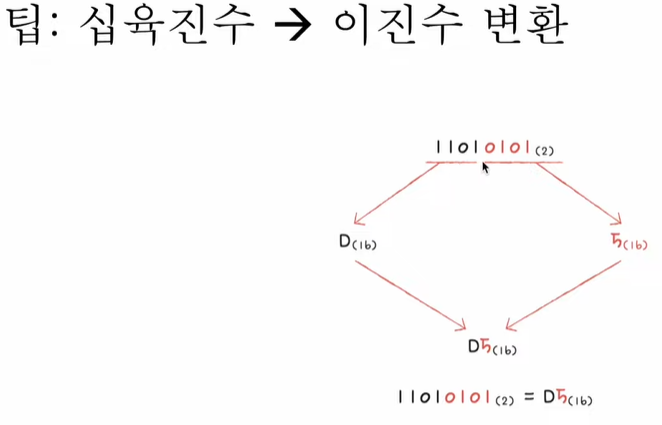
16진수를 이진수로 변환!
- 이진수와 16진수간의 변환이 쉽다!
즉 16진수의 한글자가 4bit!!
2-2 강 / 0과 1로 문자를 표현하는 방법

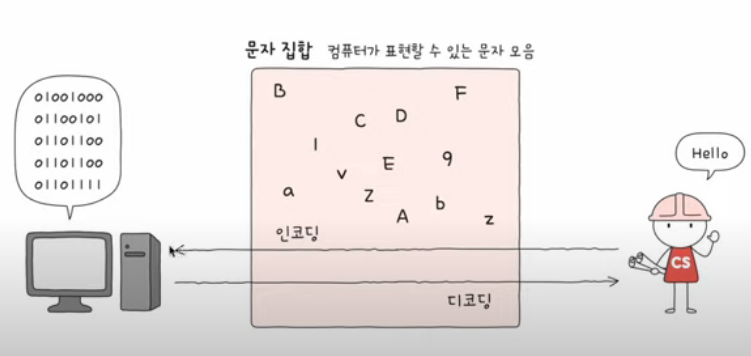
문자 집합과 인코딩
문자집합 : 컴퓨터가 인식하고 표현할 수 있는 문자의 모음!
ex) {a,b,c,d,e}만 인식할때 나머지 문자 z,p,o는 인식 못함!
인코딩 : 코드화하는 과정, 문자 -> 0,1로 이루어진 문자 코드로 변환!
디코딩 : 코드를 해석하는 과정, 0,1의 문자코드를 -> 사람이 읽을 수 있는 문자로 변환!
아스키코드
7비트로 문자 하나를 표현 ( 1비트는 오류검출을 위해 사용되는 패리티비트) // 128개 문자표현 -> 문자 표현 갯수의 제한
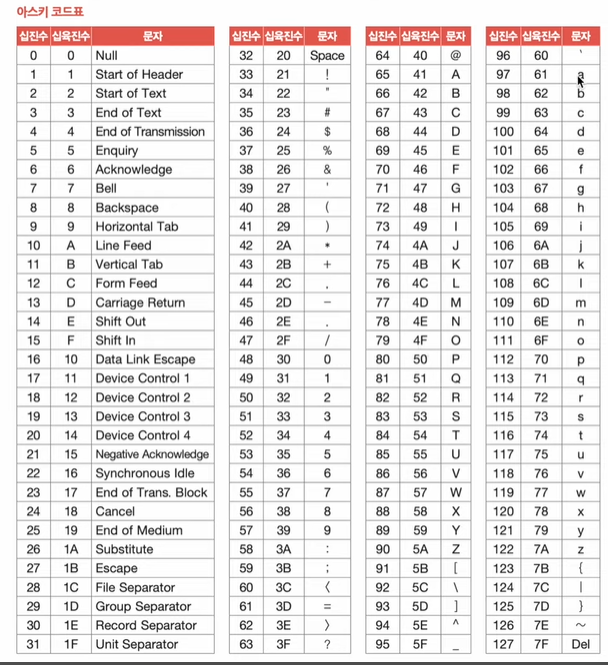
문자 인코딩에서 '글자에 부여된 고유한 값'을 코드포인트(code point)
A = 65
하지만~~~ 한글 및 특수문자 표현 안됨. 왜 WHY? 127개로는 한계!
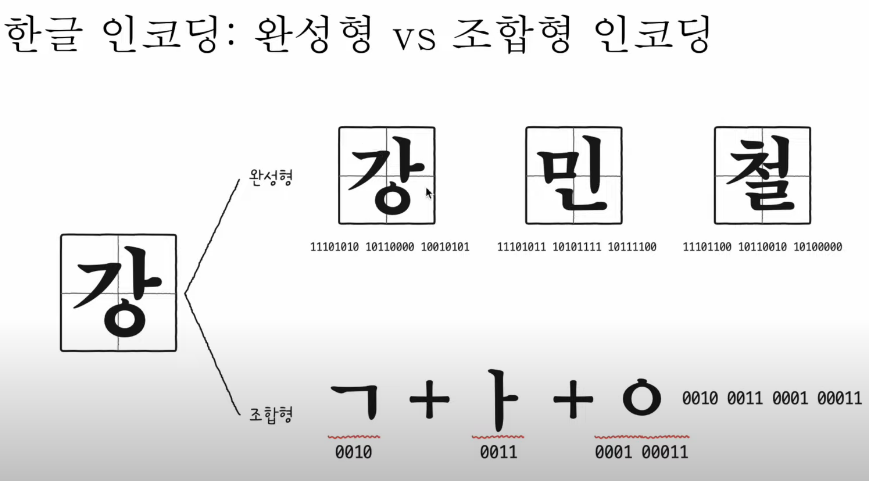
한글 인코딩 방식 : 완성형, 조합형,EUC-KR, 인코딩
-
완성형 : 하나의 글자에 고유한 코드를 부여하는 인코딩 방식!
-
조합형 : 초성을 위한 비트열, 중성, 종성에 비트열을 할당하여 하나의 글자 코드를 완성하는 인코딩 방식.
-
ECU-KR (한글 인코딩 방식, 완성형)
글자 하나에 2바이트 크기의 코드 부여 -> 4자리 16진수로 표현! (16진수 1글자는 4비트!)
2350개 한글표현가능 / 몇개의 글자 표현불가(쀍, 쮉, 뛝 ) -> EUC-KR에 이름이 등록이 안되는 경우도 ㅋㅋ

만약 다국어 서비스를 제공할 시 다국어마다 인코딩 방식을 지원해야함...
->>>> 통일된 문자 집합은 없을까????????
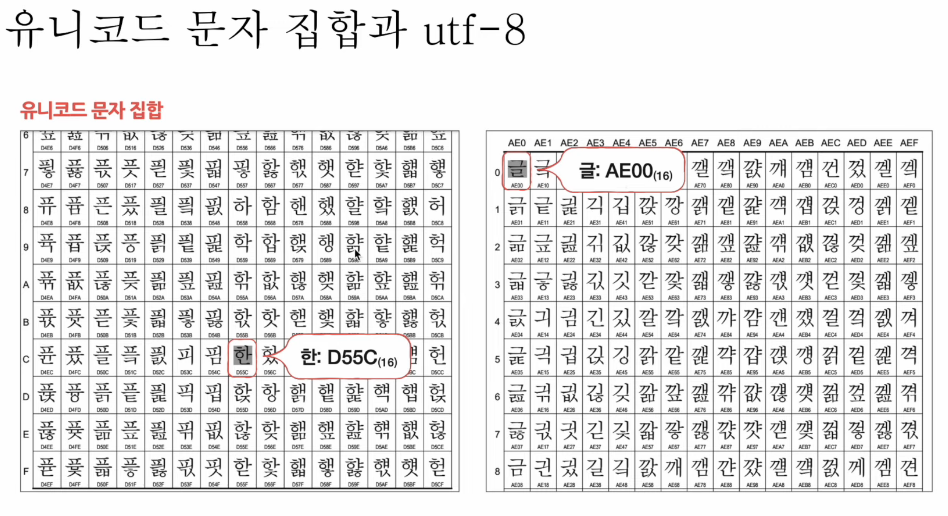
유니코드 문자 집합과 UTF-8
- 통일된 문자 집합
- 한글,영어, 화살표와 같은 특수문자, 이모티콘까지!!!
- 고유한 16진수값을 가지고 있음(문자,이모티콘등등)
U+219A, U+21A3, 등등 (https://unicode-table.com/)
아스키 코드나 EUC-KR은 글자에 부여된 값을 그대로 인코딩 값을 삼았다면!!!
유니코드는 인코딩 방법에 따라 다름,(UTF-8, UTF-16, UTF-32)
가장 대중적인 인코딩 방식 UTF-8 : 가변길이 인코딩
가변길이 인코딩 : 인코딩 결과가 몇 바이트가 될지는 유니코드에 부여된 값에 따라 다름!!
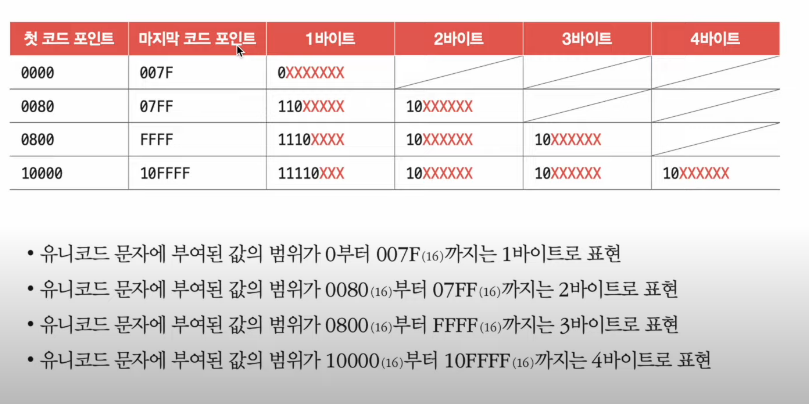
'한글'은 몇바이트로 구성되나??
D55C, AE00 -> 3바이트 3바이트
간혹가다 글자가 깨진다면?? 인코딩에 대한 부분을 의심해라!
문자 집합 : 컴퓨터가 인식할 수 있는 문자의 모음, 문자집합에 속한 문자를 인코딩하여 0과 1로 표현한다.
아스키 코드는 0~127수가 할당되는 문자집합
EUC-KR은 한글을 2바이트 크기로 인코딩하는 방식
유니코드는 가변길이 인코딩방식으로 여러 인코딩방법이 있다(UTF-8,UTF-16등)
