
AutoEncoder 란 ?
Autoencoder(오토인코더)란 representation learning 작업에 신경망을 활용하도록 하는 비지도 학습 방법
- 입력이 들어왔을 때, 해당 입력 데이터를 최대한 압축시킨 후 , 데이터의 특징을 추출하여 다시 본래의 입력 형태로 복원시키는 신경망
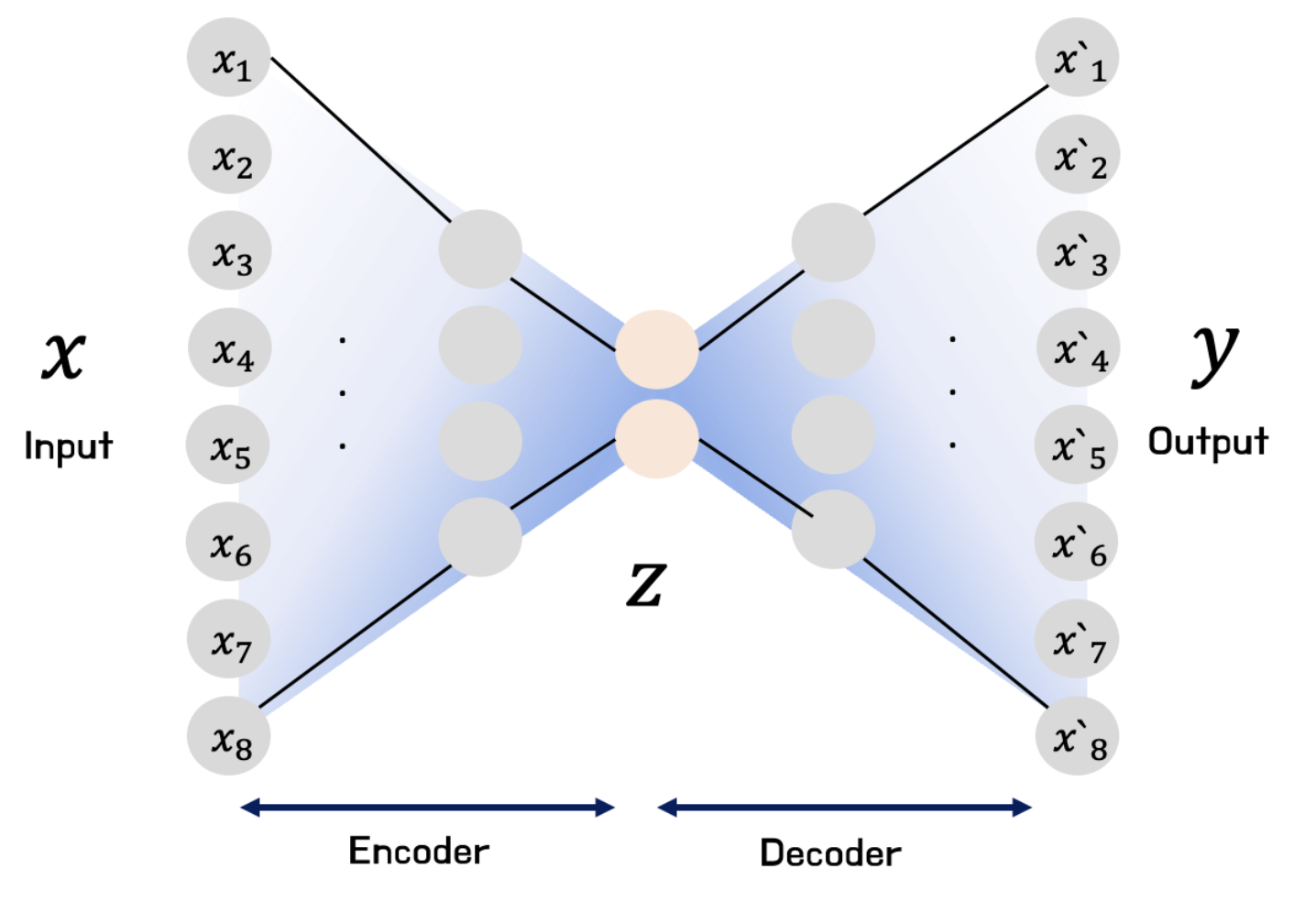
- Encoder : 인지 네트워크(recognition network) 라고도 하며, 입력을 내부 표현으로 변환
- Decoder : 생성 네트워크(generative network) 라고도 하며, 내부 표현을 출력으로 변환
이때, 데이터를 압축하는 부분을 Encoder, 복원하는 부분을 Decoder 라고 하며 압축과정에서 추출한 의미 있는 데이터 Z를 보통 latent vector 라고 부르며 이를 latent variable, feature 과도 같이 부른다
Input 데이터로 데이터가 들어오면 특징을 추출하여 Output 데이터로 원본 데이터를 재건한다
- 이때, 재건 오류 (reconstruction error) 가 원래의 입력 데이터와 복원 결과물의 차이를 최소화하도록 학습을 진행한다
오토인코더가 특징 추출기처럼 작동하여 심층신경망의 비지도 학습 에 사용될 수 있다
AutoEncoder의 활용
차원 감소 ( Dimensionally Reduction)
- 인코더는 입력을 선형 및 비선형의 데이터로 차원을 줄이기 위하여 히든레이어로 인코딩한다
추천 엔진 (Recommendation Engines)
이상탐지(Anommaly Detection)
- 오토인코더는 훈련의 일부로 재구성 오류 (Reconstruction error) 를 최소화하려 한다. 따라서 재구성 손실의 크기를 통하여 이상치를 탐지할 수 있다
이미지 잡음제거 (Denoising images)
- 변질된 이미지가 원래 버전으로 복원이 가능하다
이미지 인식 (Image Recognnition)
- 겹겹이 쌓인 오토인코더는 이미지의 다른 특성을 학습하여 이미지 인식에 사용된다
이미지 생성 (Image generation)
- 오토인코더의 한 종류인 변형 오토인코더 (VAE, Variational Autoencoder)는 이미지 생성에 사용된다
Stacked Autoencoder
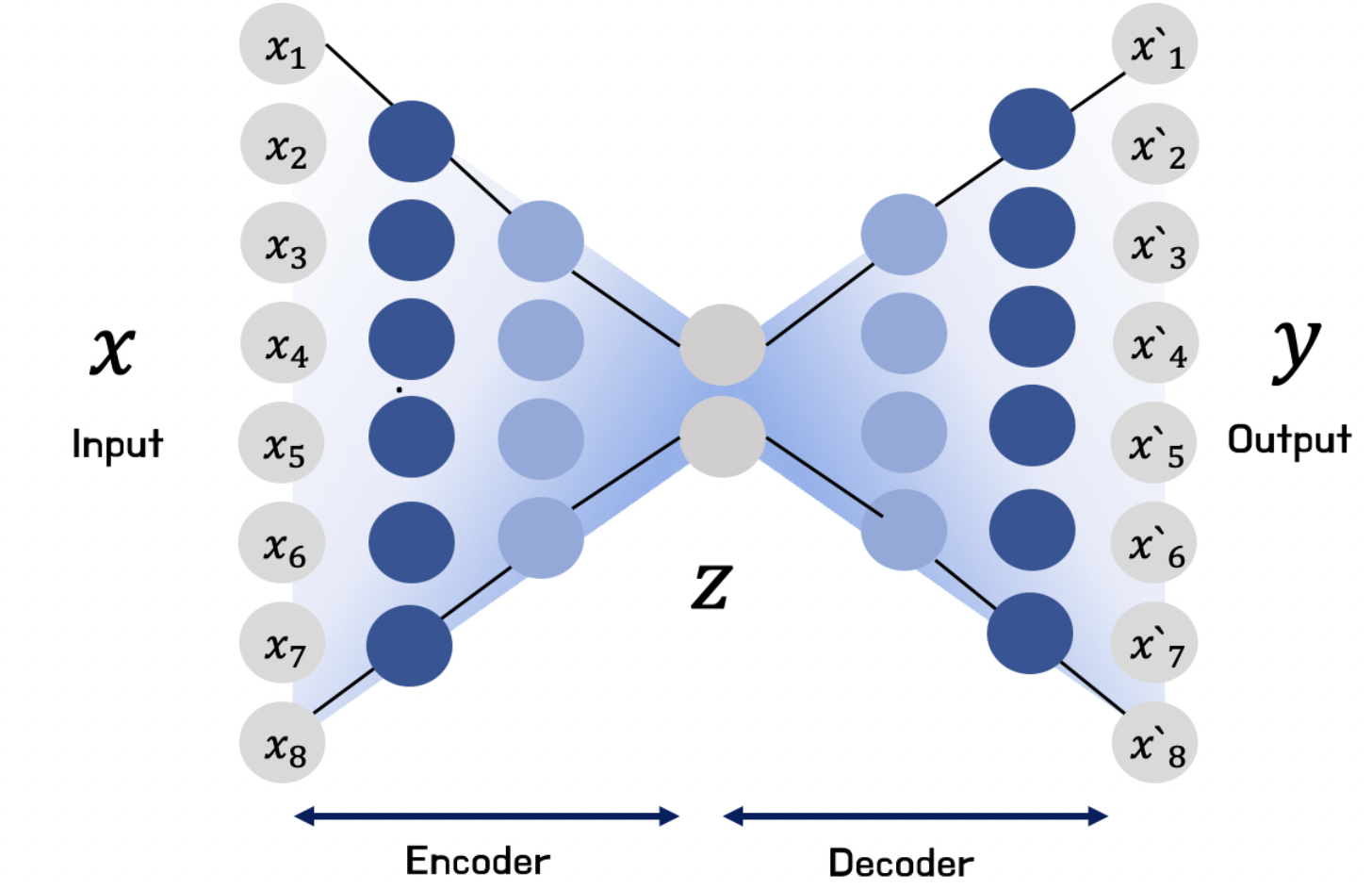
가장 기본적인 Autoencoder 구조의 경우 input layer, hidden layer, output layer 로 이루어진 Autoencoder 구조이고 이 구조에서 hidden layer의 개수를 늘린것을 stacked autoencoder 혹은 Deep autoencoder 라고 부른다
- 레이어를 추가할수록 오토인코더가 더 복잡한 코딩을 학습할 수 있다
Sparse Autoencoder
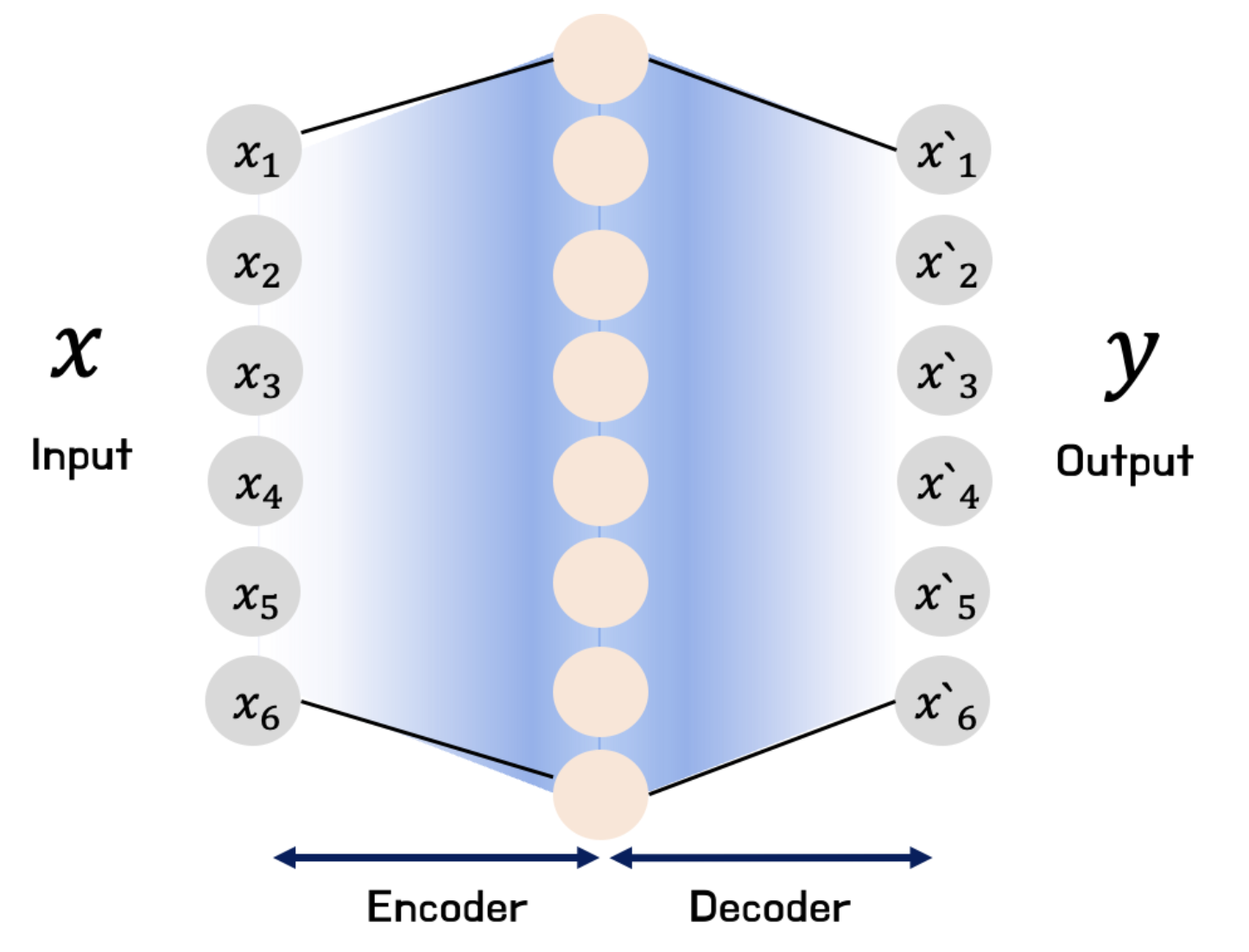
Sparse Autoencoder 은 기본적인 Autoencoder 의 구조와는 다르게 Hidden layer 내의 Node 수가 더 많아진다.
Autoencoder 를 사용하게 되면 원본데이터의 Feature 를 압축하다보면, 다른 데이터가 들어와도 training set 과 비슷하게 만들어버리는 overfitting 의 문제점이 존재하는데 , 이를방지하기 위해 Sparse Autoencoder 를 사용한다. Sparse Autoencoder 를 사용하게 되면 overfitting 을 줄이는 효과가 있다
Sparse AutoEncoder 를 통해 sparse(0이 많은) 한 노드들을 만들고, 그 중에서
0과 가까운 값들은 전부 0으로 보내버리고 0 이 아닌값들만 사용하여 네트워크 학습을 진행한다.
Denoising Autoencoder
Denoising Autoencoder 은 입력층에서 Hidden layer로 갈 때, Noise를 추가한 것이다.
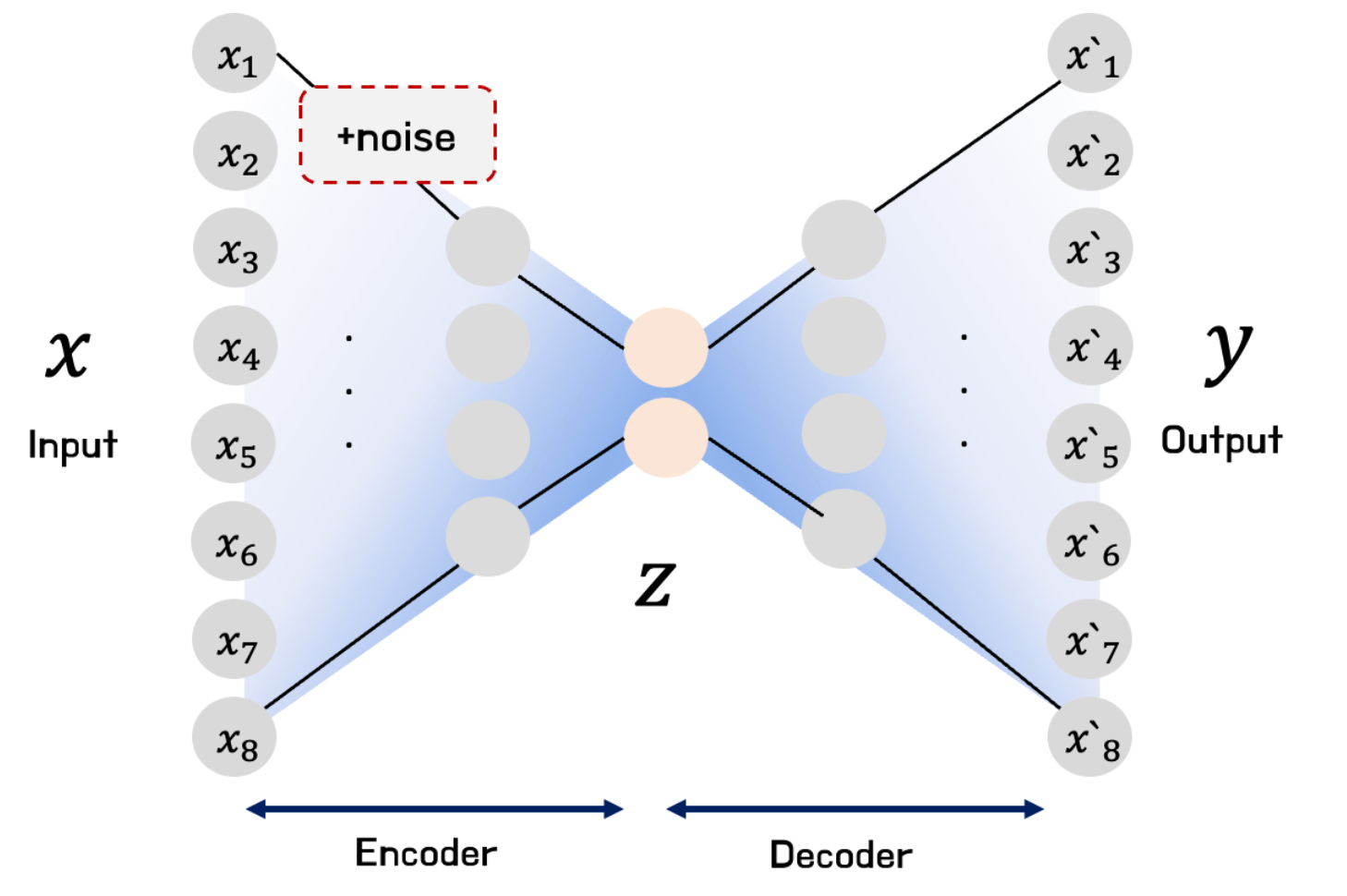
이러한 Noise 를 추가하였을 때 사람의 인식으로는 같은 데이터라고 느끼지만 실제로는 성능향상의 효과를 얻을 수 있다.
Variational Autoencoder
VAE 는 Input image X 를 잘 설명하는 feature 를 추출하여 Latent vector z 에 담고, Latent vector z 를 통해 X와 유사하지만 새로운 데이터를 생성하는 것을 목표로 한다. 이떄, 각 feature는 가우시안 분포를 따른다고 가정하고 평균과 분산값을 나타내어 준다.
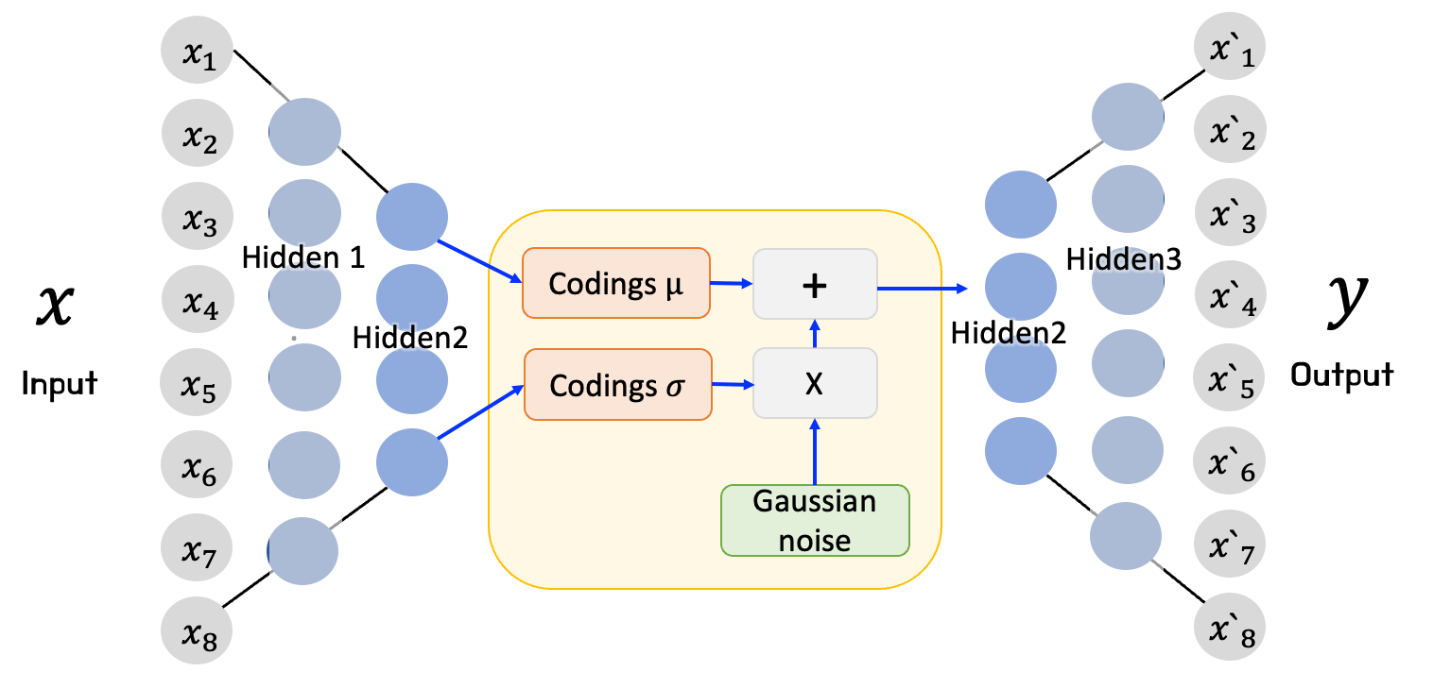
VAE는 확률적 오토인코더이다. 따라서 학습이 끝난 이후에도 출력이 부분적으로 우연에 의해 결정된다.
VAE는 생성 오토인코더이며, 학습 데이터셋에서 샘플링된 것과 같은 새로운 샘플을 생성할 수 있다.
VAE는 생성 모델이기 때문에, 디코더를 학습시키는 것을 주 목적으로 한다
VAE 의 인코더는 주어진 입력에 대하여 평균 코딩과, 표준편차 코딩을 만든다
실제 코딩은 가우시안 분포에서 랜덤하게 샘플링되며, 이렇게 샘플링된 코딩을 디코더의 입력으로 사용해 원본 입력으로 재구성하게 된다
VAE의 손실함수
- VAE의 손실함수는 두 부분으로 구성되어 있으며 첫번째로, 오토인코더가 입력을 재구성하도록 만드는 일반적인
재구성 손실 (Reconstruction loss)이고, 두번째로, 가우시안 분포에서 샘플링 된 것같은 코딩을 가지도록인코더를 제어하는 latent loss이다.
참고/레퍼런스
excelsior-cjh.tistory
pebpung.github.io
hyen4110.tistory
inspaceai.github.io
wooono.tistory
analysisbugs.tistory
