Association Rule : 장바구니 분석, 연관성 분석
: 어떤 아이템의 집합이 번번히 발생하는가를 알려주는 일련의 규칙들이 생성하는 알고리즘
전통적으로 Apriori 와 FP - Growth 알고리즘 을 이용한 장바구니 분석은 소비자 유형과 계절 별, 카테고리 별 등의 소비자 패턴을 분석하여 재고 관리와 상점 내 상품 배치, 물류 센터 내 제품 적재 배치 결정 등의 효율성 향상을 위해 개발된 분석 기법
🤔 연관 분석이란?
→ ‘조건 - 결과’ 식으로 표현되는 유용한 패턴을 나타내는 연관 규칙을 발견해내는 것
룰기반의 모델로서 상품과 상품 사이에 어떤 연관이 있는지 찾아내는 알고리즘
대표 예시 : 마트에서 맥주를 구매할 때 기저귀를 같이 구매하는 경향이 크다 ! ⇒ 이를 바탕으로 상품 진열 전략을 세우기도 함
🍎 연관 규칙 측정 지표
🟡 지지도 (support)
- 조건절이 일어날 확률
- 전체 거래 중 상품 A와 상품 B가 동시에 포함되는 거래 비율
- 전체적인 구매 경향 파악
🟡 신뢰도 (confidence)
- 조건절이 주어졌을 때, 결과절이 일어날 조건부 확률
- 상품 A가 포함된 거래 중에서 상품 A,B가 동시에 포함되는 거래 비율
- 연관성의 정도 파악 (예를 들어, A를 구매하면 B도 구매)
🟡 향상도 (lift)
- 조건절과 결과절이 서로 독립일 때와 비교해 두 사건이 동시에 발생하는 확률
- 상품 B가 포함된 거래 중에서 상품 A를 거래 후 상품 B를 거래한 비율
- 두 상품이 서로 독립일 경우 → 향상도 = 1
- 두 상품이 서로 양의 관계일 경우 → 향상도 > 1
- 두 상품이 서로 음의 관계일 경우 → 향상도 < 1
🟡 최소 지지도 (minimum support)
- 불필요한 탐색 시간을 줄이기 위해 사용자가 설정하는 하이퍼 파라미터
- 처음에는 임의로 설정 후 계산 속도와 의미가 현실적인지 판단
- 높은 값에서 낮은 값으로 실행해야 효율적임
🍐 Apriori 와 FP-Growth 알고리즘
🟡 Apriori 알고리즘
빈발항목집합을 추출하는 것이 원리이다. (빈발항목집합 : 최소 지지도 이상을 갖는 집합)
모든 항목집합에 대한 복잡한 계산량을 줄이기 위해 최소 지지도를 정해서 그 이상의 값만 찾은 후 연관 규칙을 생성한다.
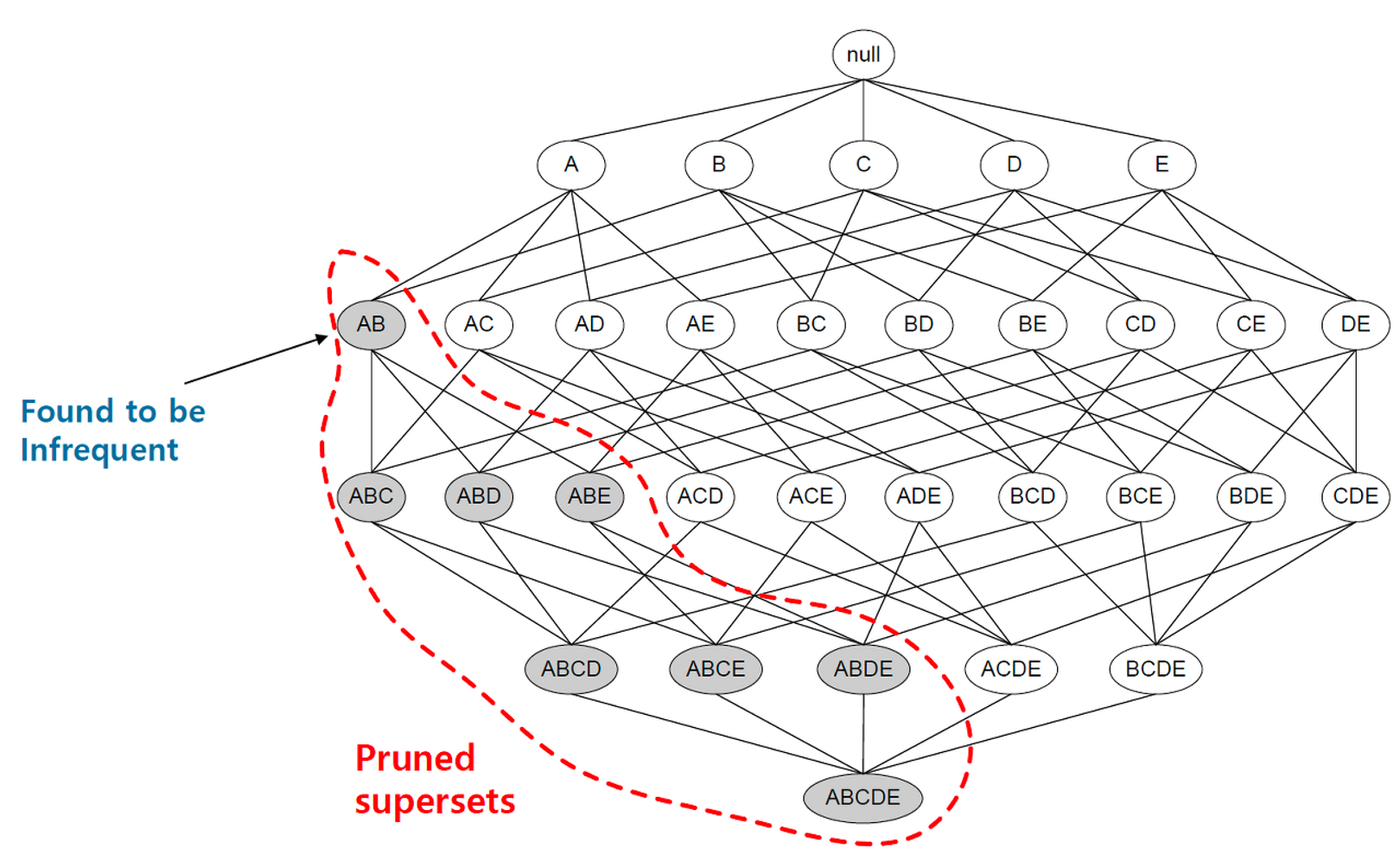
예를 들어 집합 {A,B} 의 지지도가 사용자가 정한 최소 지지도를 넘지 못하면 자동적으로 {A,B}는 물론이고 {A,B} 를 포함한 {A,B,C},{A,B,D} 등의 규칙들도 모두 한번에 제거가 된다!
⇒ 따라서 계산량이 줄어듬
😆 장점
- 상품간의 많은 연관 규칙들을 발견할 수 있음
- 원리가 간단하여 쉽게 이해 가능
😕 단점
- 상품 수가 많을수록 계산량이 기하급수적으로 늘어남
- 비즈니스 측면에서 중요한 연관 규칙들을 발견하기에 부족함
import mlxtend
import numpy as np
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import time
data = np.array([
['우유','기저귀','쥬스'],
['상추','기저귀','맥주'],
['우유','양상추','기저귀','맥주'],
['양상추','맥주']
])
start = time.time()
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
#print(df)
min_support_per = 0.5
min_trust_per =0.5
result = apriori(df,min_support=min_support_per, use_colnames=True)
result_chart = association_rules(result, metric="confidence", min_threshold=min_trust_per)
print(result_chart)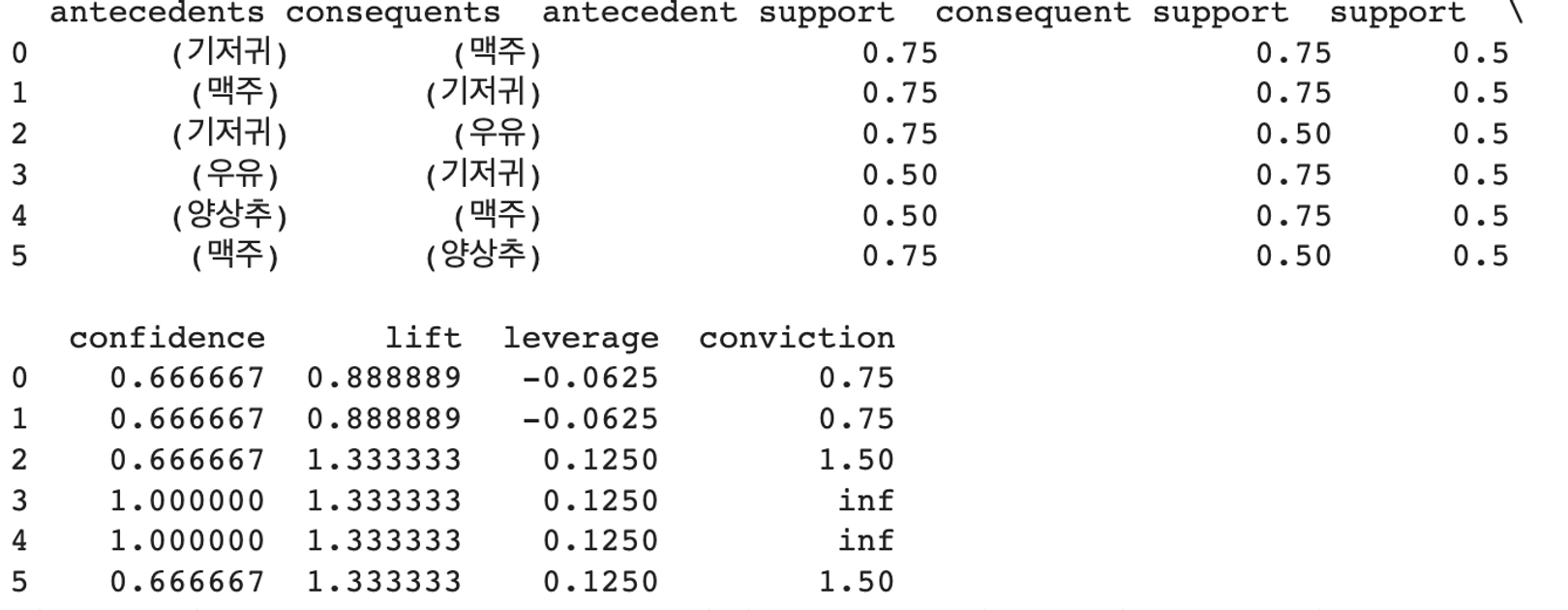
🟡 FP-Growth 알고리즘
: FP - Tree 라는 구조를 이용하여 Apriori를 효과적으로 구현한 것
Tree, Array, Linked-List를 합쳐놓은 구조이다!
👍🏻 Apriori의 연산 속도 문제를 해결할 수 있게 자료구조를 잘 이용한 형태 !!
연관 규칙을 트리로 만들어 단점을 개선
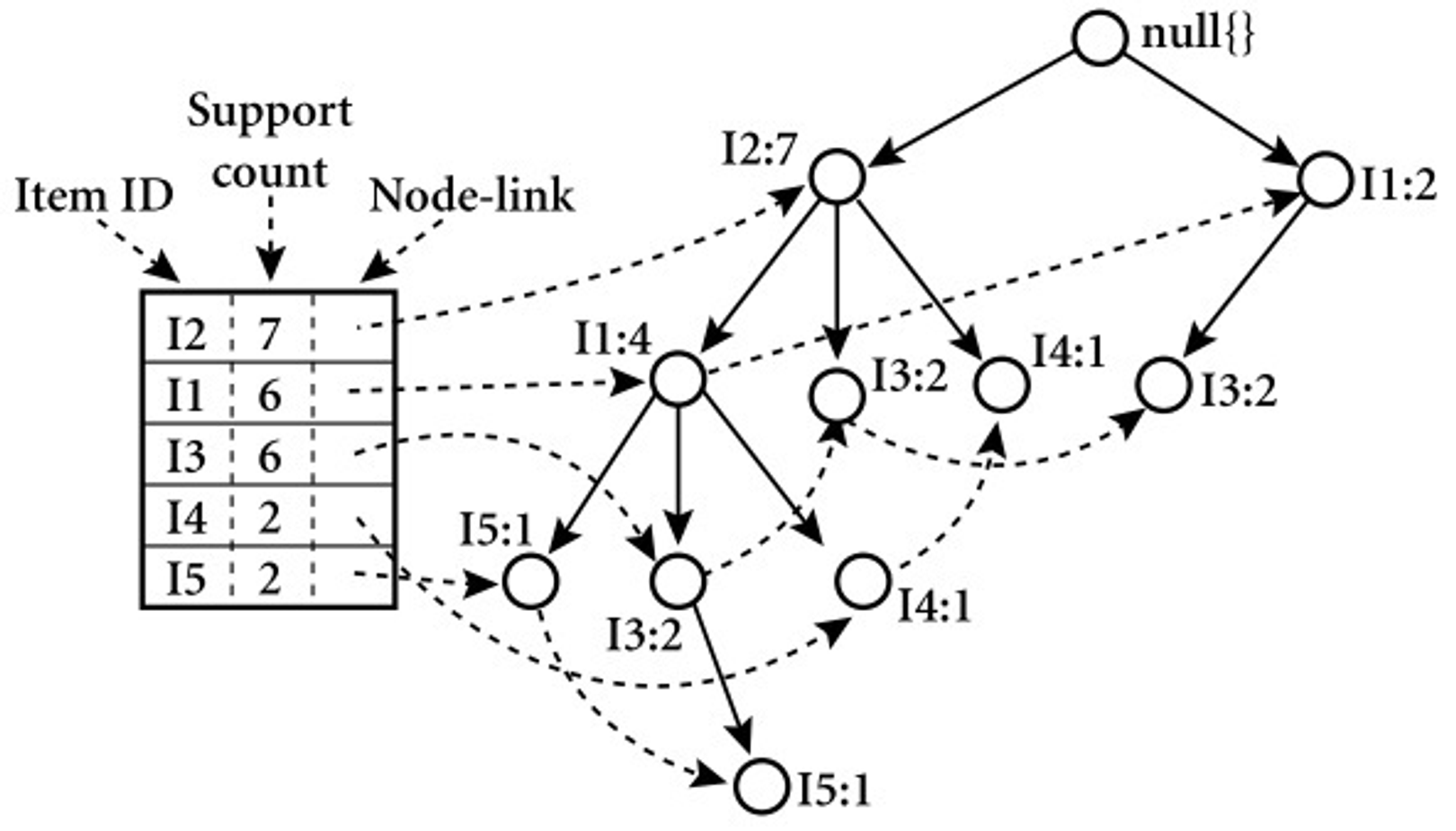
모든 거래를 확인해 각 아이템마다 서포트를 계산하고 , 최소 지지도 이상의 아이템만 선택
- 모든 거래에서 빈도가 높은 아이템 순서대로 순서를 정렬
- 부모 노드를 중심으로 거래를 자식 노드로 추가해주며 tree 를 생성
- 새로운 아이템이 나올 경우 부모노드부터 시작하고, 그렇지 않으면 기존의 노드에서 확장
- 위의 과정을 모든 거래에 대해 반복하여 FP Tree 를 만들고 최소 지지도 이상의 패턴만 추출
예시)
- FP - Tree 만들기
- 모든 거래에서 빈도가 높은 아이템 순서대로 정렬

각각 빈도를 계산하면 초장은 10번, 과메기는 91번, 김은 51번 나타났다. 이를 빈도가 높은 순으로 표현하면 과메기 : 91, 김: 51, 초장 : 10
- itemset에 하나씩 tree를 더하며 tree를 만들어준다 맨 처음 시작 노드를 만들어준다.
각 instance를 추가해주며 tree 를 만든다. 빈도가 높은 item이 0에 더 가깝게 만들어준다.
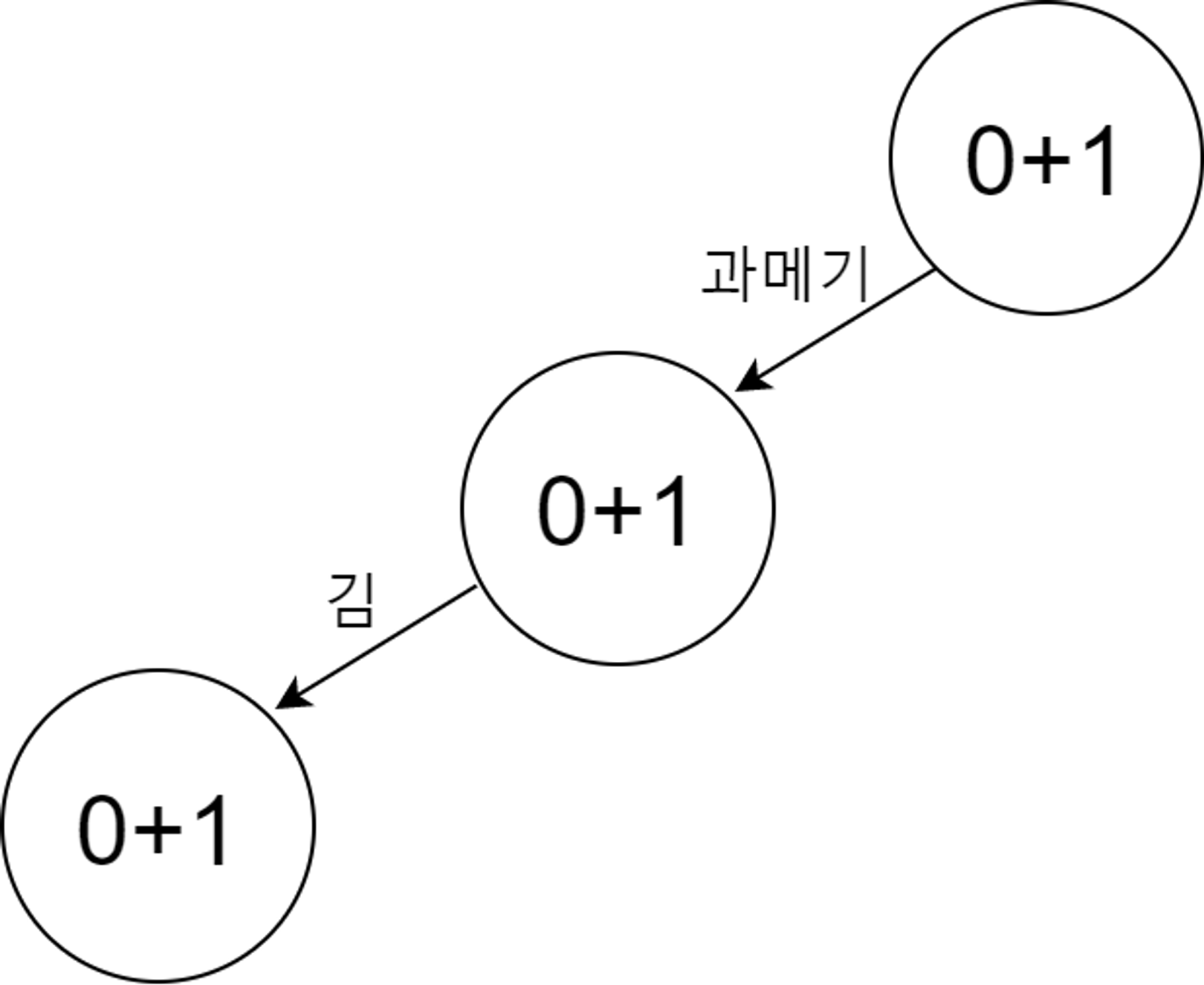

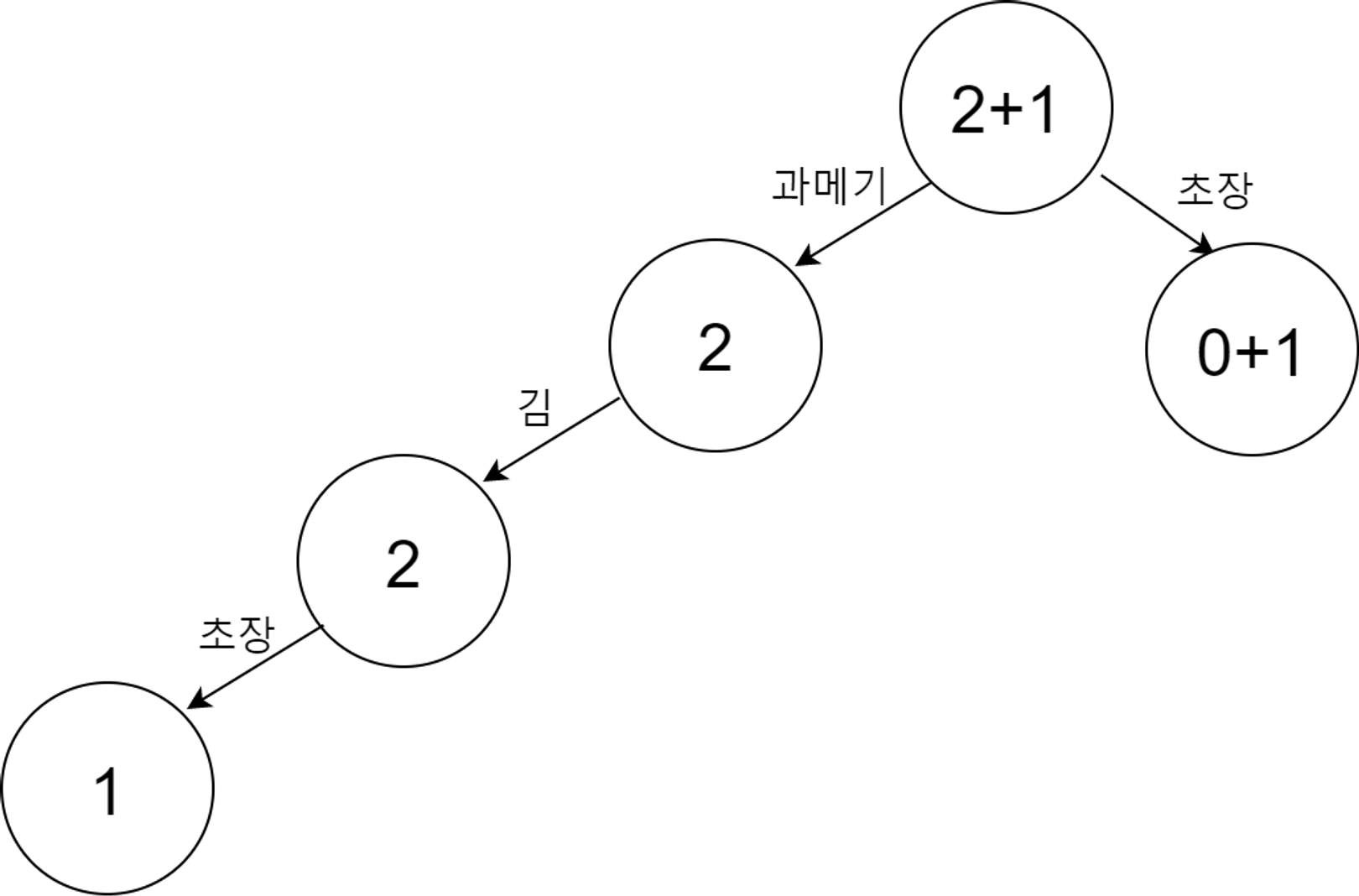
순서대로 {과메기,김} 추가, {과메기, 김, 초장} 추가, {초장} 추가
이런식으로 모든 데이터셋에 대한 트리를 만들어주면 최종적인 트리가 만들어진다.
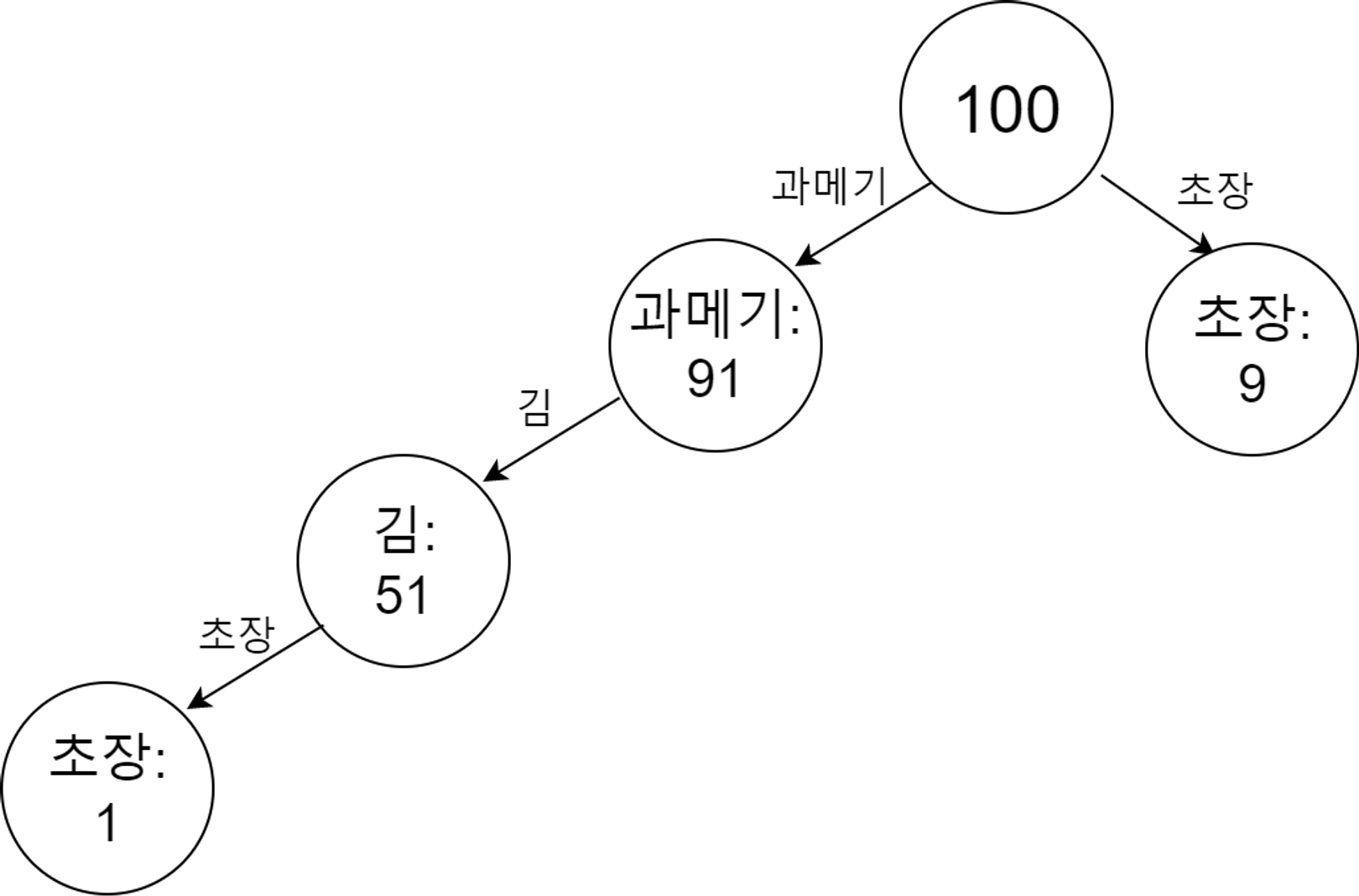
이렇게 트리를 그린 후 각각 support 를 구해 최소 지지자 이상의 패턴만 추출한다.
😆 장점
- Tree 구조이기 때문에 Apriori보다 훨씬 빠르다
- 후보 Itemset을 생성할 필요 없이, Tree 만 구성하면 끝이다.
😕 단점
- 대용량 데이터 셋에서 메모리를 효율적으로 사용하지 않는다.
- Apriori에 비해 설계하기 어렵고, 서포트의 계산은 무조건 FP-Tree가 만들어져야 가능하다.
코드
import mlxtend
import numpy as np
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import association_rules
from mlxtend.frequent_patterns import fpgrowth
import time
start = time.time() # 시작 시간 저장
data = np.array([
['우유','기저귀','쥬스'],
['상추','기저귀','맥주'],
['우유','양상추','기저귀','맥주'],
['양상추','맥주']
])
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
min_support_per = 0.5
min_trust_per =0.5
result = fpgrowth(df,min_support=min_support_per, use_colnames=True)
result_chart = association_rules(result, metric="confidence", min_threshold=min_trust_per)
print(result_chart)
참조
https://terryvery.tistory.com/93
https://process-mining.tistory.com/92
https://tkdguq05.github.io/2021/03/07/apriori-FP/
https://jaaamj.tistory.com/114
