Backpropagation Through Time
BPTT는 RNN에서 계산되는 back propagation이다. RNN의 구조는 sequential하기 때문에 이에 따라 발생하는 hidden state를 따라 역행하면서 전파되는 gradient의 계산 방법이다. 다음은 RNN의 기본 구조이다.
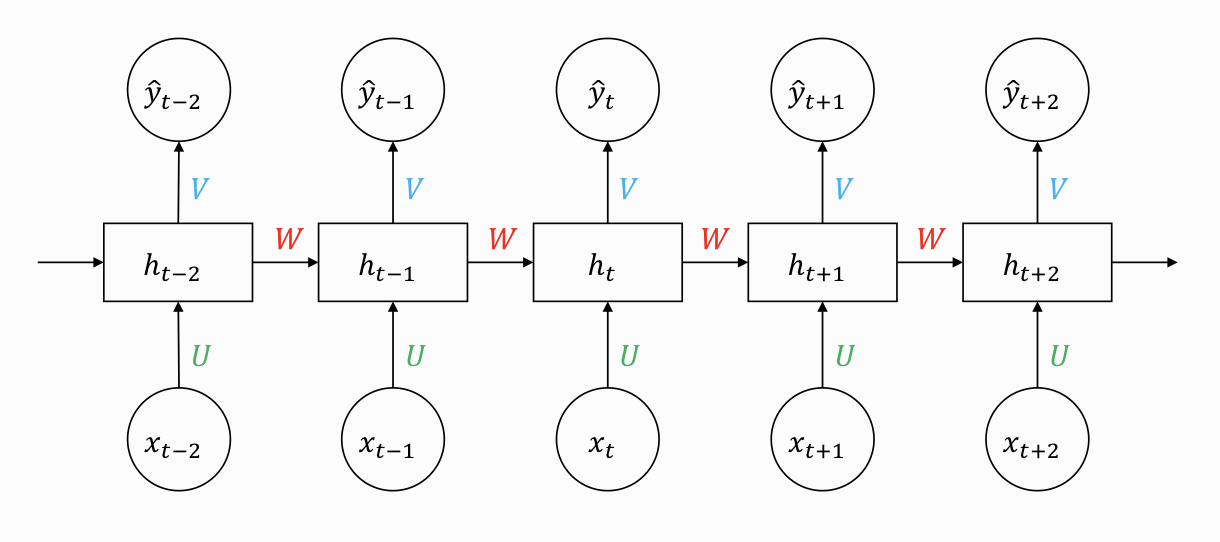
st=tahn(Uxt+Wst−1)
ytˉ=sotfmax(Vst)
U: input을 연결하는 가중치 행렬
W: 현재 hidden state와 다음 hidden state를 연결하는 가중치 행렬
V: output을 연결하는 가중치 행렬
이때 첫번째 셀의 loss값을 다음과 같이 정리할 수 있다.
E1=(d1ˉ−y1ˉ)2
만약 Timestep = 3이라면 현재 model에서 update해야되는 weight matrix는 U, W, V 3개가 존재합니다.
그렇다면 U의 gradient를 구하기 위하여 E3에 대하여 U로 편미분한 결과를 chain rule을 통해 구할 수 있다.
∂U∂E3=∂y3ˉ∂E3⋅∂U∂y3
다음 W의 gradient를 구하면 다음과 같다.
∂W∂E3=∂y3ˉ∂E3⋅∂W∂y3
∂W∂E3=∂y3ˉ∂E3⋅∂s3∂y3⋅∂W∂s3
하지만 기존 backpropagation과는 다른 점이 각 timestep이 gradient에 영향을 주었기 때문에 ∂W∂s3를 상수 취급할 수 없다. 현재 timestep이 3인 출력 부분까지의 이전 timestep이 적용되기 때문에 t=2, t=1 까지 gradient를 전부 더해야한다. 그렇다면 다음과 같이 정리할 수 있다.
∂W∂E3=∂y3ˉ∂E3⋅∂s3∂y3⋅∂W∂s3+∂y3ˉ∂E3⋅∂s3∂y3⋅∂s2∂s3⋅∂W∂s2+∂y3ˉ∂E3⋅∂s3∂y3⋅∂s2∂s3⋅∂s1∂s2⋅∂W∂s1
간단하게 정리하면 다음과 같은 식으로 정리할 수 있다.
∂W∂E3=i=0∑3∂y3ˉ∂E3⋅∂s3∂y3⋅∂si∂s3⋅∂W∂si
그리고 ∂si∂s3도 chain rule을 내포하고 있기 때문에 ∂si∂s3=∂s2∂s3⋅∂s1∂s2로 나타낼 수 있다. 위의 gradient를 다시 써보면 다음과 같이 나타낼 수 있다.
∂W∂E3=i=0∑3∂y3ˉ∂E3⋅∂s3∂y3(j=i+1∏3∂sj−1∂sj)⋅∂W∂si
하지만 BPTT를 진행하다보면 처음부터 끝까지 모든 loss를 backpropagation해야하기 때문에 계샨량이 너무 많아지는데, 이것을 줄이고자 Truncated-Backpropagation Through Time(생략된-BPTT)를 많이 사용한다.
