Introduction
인간은 지식을 언어를 통해 전달한다. 이것이 인간이 다른 동물에 비해 발전할 수 있었던 이유이다. 그렇다면 그 언어의 의미는 어떻게 나타내어 지는가? 언어의 의미는 symbol이 있고 symbol은 idea(thing)을 가지고 있다. 이것을 denotational semantics라고 부른다.
NLP에서는 단어를 Discrete symbol로 간주했고 동의어와 상위어 리스트가 포함된 WordNet을 common solution으로 사용했다. 그러나 WordNet에는 몇가지 한계점이 존재했다.
- 단어의 뉘앙스를 파악하지 못함
- 단어의 새로운 뜻을 반영하지 못함
- 주관적
- 많은 노동력을 필요로함
- 단어의 유사도를 계산할 수 없음
One-hot Vector
NLP에서는 2012년 이전에 one-hot vector라는 word representation 방식을 사용했다.
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
One-hot vector는 해당 단어를 표현하기 위해 해당 단어의 자리만 1로 표현하고 나머지는 전부 0으로 나타낸다. localist representation 방식으로 단어들은 one-hot vector로 표현되지만 많은 문제점을 가지고 있다. 단어의 차원과 벡터의 차원의 수는 같은데 단어가 많으면 많아질수록 표현해야되는 벡터의 차원수도 같이 늘어나게되서 계산 복잡도가 높아져 차원의 저주에 빠질 수 있다. 단어 하나만 1의 값을 가지고 나머지는 0을 가지는 희소행렬 문제를 가지게되고 메모리도 낭비하게된다. 그리고 one-hot vector는 각각 독립적인 축을 가지고 있고 직교를 이루고 있어 단어 간 유사성을 알기 힘들다.
이러한 문제점을 해결하기 위해 등장한 개념이 Distributed Representation이다. Distributed Representation은 distributional hypothesis이라는 가정 하에 나온 방법이다.
distributional hypothesis의 개념은 비슷한 위치에서 자주 등장하는 단어들은 비슷한 의미를 가진다.
Distributional hypothesis는 단어의 의미를 벡터에 여러 차원에 분산하여 표현한다. 이는 앞서 말한 one-hot vector와는 다르게 하나의 차원에 하나의 속성을 표현하는 것이 아닌 여러 차원들을 조합하여 나타내고자 하는 속성들을 표현한다. 이를 통해 sparse vector가 아닌 dense real valued vector를 만들고자 하며 단어를 분산 표상을 이용하여 나타낼 수 있다.
Word2Vec
Mikolov가 발표한 Word2Vec의 기본적인 아이디어는 다음과 같다.
- 많은 text 말뭉치(corpus)를 가지고 있음
- voacb에 존재하는 모든 단어는 벡터로 표현됨
- t에 위치한 중심단어 c(center word)와 주변단어 o(context word)를 가짐
- c와 o의 유사도를 vector를 통해 구할 수 있고 c가 주어졌을 때, o가 나타날 확률을 계산
- 이 확률을 최대화 하기 위해 벡터를 조정
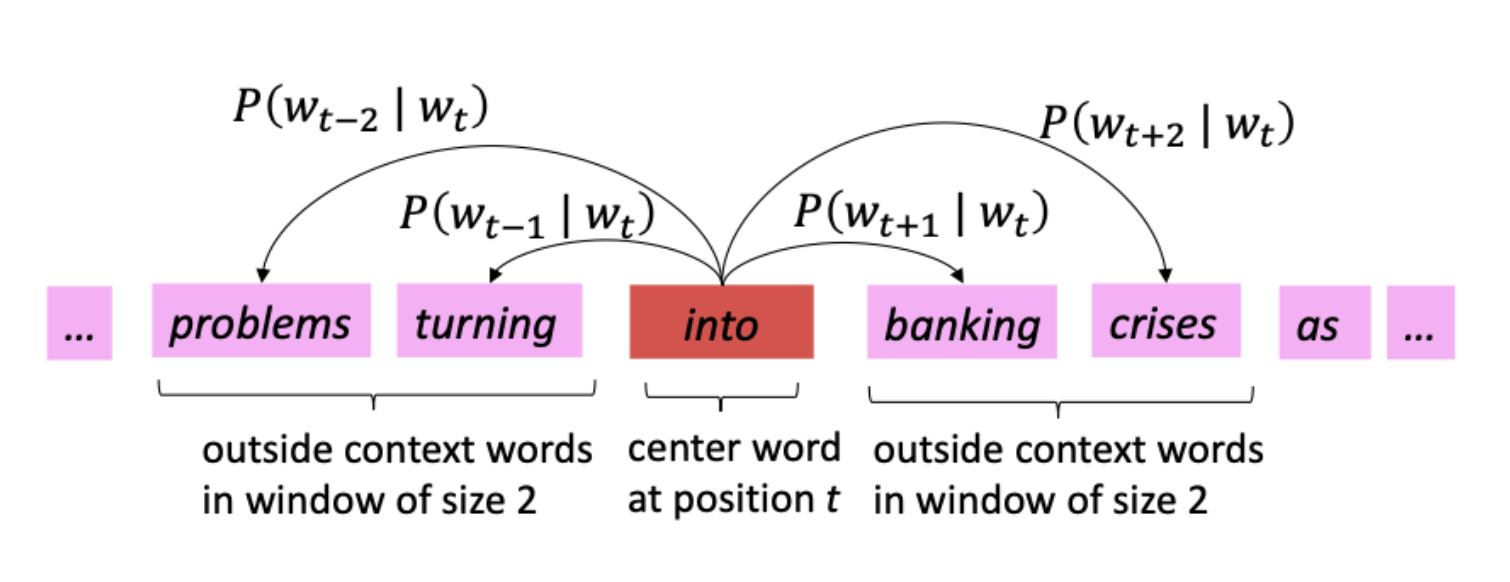
중심단어인 'into'에 대한 likelihood는 다음과 같다.
각 위치의 중심단어인 에 대해 주변단어 가 나오는 확률인, 구하는 식이다. 두 단어 c,o가 비슷한 의미를 가지고 있다면 내적 값은 커지게되고 p또한 커지게된다. 이를 optimization하는 하기 위해 gradient descent를 사용하고 Negative Log Likelihood로 변경했다. Maximizing Likelihood를 Minimizing obejective function으로 변경했다. 식은 아래와 같이 변경되었다.
이때 확률 p를 구하기 위해서 softmax 함수를 이용했고 식은 확률 p에 대한 식은 아래와 같다.
함수 exponential을 사용한 이유는 u와 v의 내적을 양수로 만들어 확률로 만들어 줄 수 있어서 이다.exp의 지수 두 벡터의 내적 값을 나타내고 이 값이 커지면 벡터 간 유사도가 커진다(cosine 유사도가 높아진다). 즉, 중심단어와 주변단어의 유사도는 높이고 중심단어와 전체 vocab의 내적 값인 분모가 작아져야한다(cosine 유사도가 낮아진다).
Object Function 최소화를 위해 로 미분하면 다음과 같다.

