0. Abstract
기존 ViT(Vision Transformer)는 input resolution에 따라 complexity가 기하급수적으로 늘어났다. 기존 여러 방법을 통해 complexity를 낮추었지만, 이에따라 global한 feature extraction 기능 또한 하락하여 기존 ViT의 이점이 사라졌다.
따라서 저자는 linear attention의 부족한 global information을 위해 light weight ReLU linear attention을 도입했고, 이에 따른 local information이 부족한 것을 채우기 위해 depthwise convolution을 FFN(Feed Forward Network)에 삽입했다. (Global, Local information을 균형 맞추었다.)
1. Method
1.1 Multi-scale Linear Attention
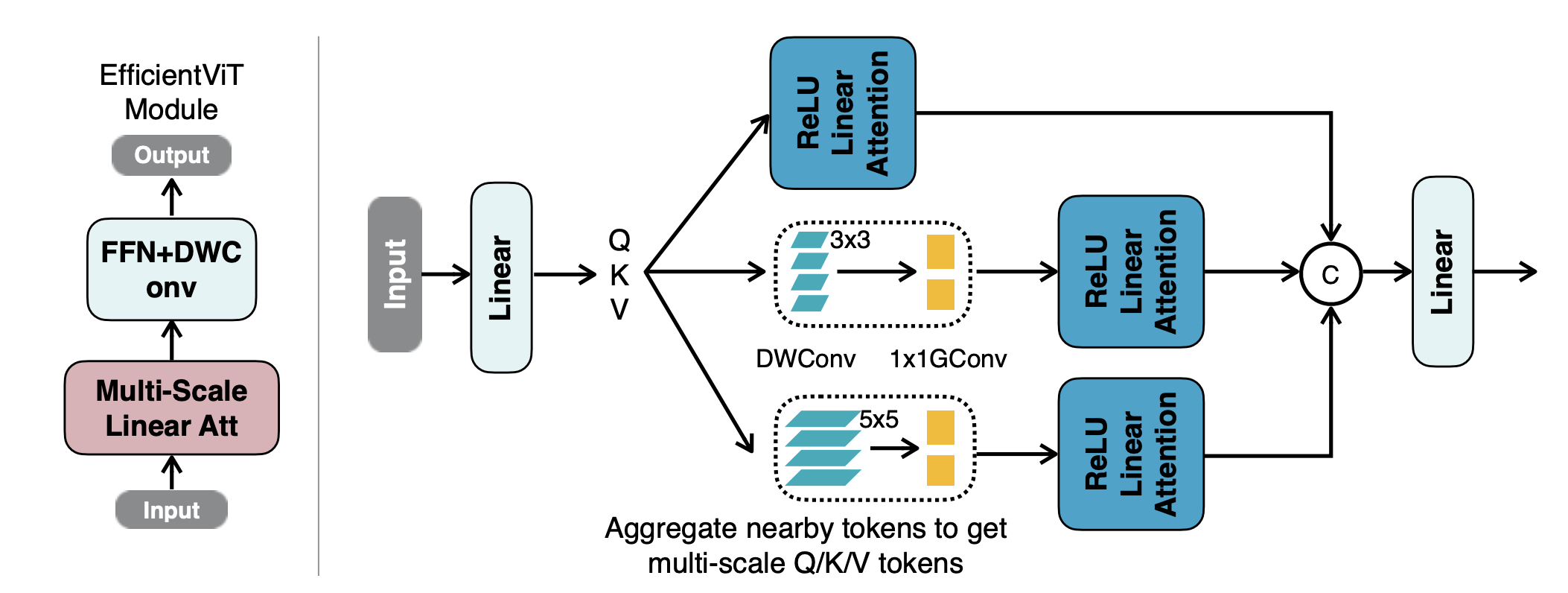
먼저 기존 heavy softmax attention을 ReLU linear attention으로 대체했다. Linear Transformer의 linear attention과 거의 똑같다.
https://velog.io/@jody1188/Linear-Complexity-Attention
이러한 linear attention은 계산적으로 아주 큰 이점을 가져다 주지만, non-linear attention score normalization scheme이 부족하다는 한계점을 가지고 있다. 이는 다른말로 linear attention이 local pattern에서 만들어진 높은 attention score 집중하지 못하며 local feature extraction을 떨어뜨린다는 말이다.
따라서 저자는 해결 방법으로 두 가지 방법론을 사용했다. 먼저 각 FFN layer에 depthwise convolution layer를 삽입했다.(depthwise convolution을 사용한 이유는 아무래도 연산량 때문인 것 같다.)
다음으로 서로 다른 크기의 kernel을 가진 depthwise convolution layer와 group convolution layer를 각 head에 독립적으로 두어 attention 연산의 query, key, value를 통과시켜 multi-scale 연산이 이루어지도록 했다. 각 head마다 다른 크기의 kernel을 지나 서로 다른 정보로 합해진 feature map을 추출하여 attention한 것으로 보인다.
