0. Pre-trained Methods
기존 transformer model은 word embedding layer를 통해 vector로 변환된 token을 embedding matrix를 통해 embedding space에 projection하여 단어들이 특정 vector 값으로 mapping된다. 이러한 방법은 embedding matrix가 일종의 look-up table 역할을 한다.
그러나 이러한 방법은 결국에 각각 단어가 문맥에 따라 서로 다른 의미를 가지는것을 나타낼 수 없다. 각 단어가 문맥에 따라 서로 다른 의미를 반영할 수 있는 여러 방법이 연구되었다.
0.1 ELMo
ELMo는 pre-train 방법으로 feature-based 방법을 사용했다. ELMo의 기본적인 architecture는 bi-lstm layer를 여러층 쌓아올렸다. 이러한 모델 구조의 내부 layer에 hidden vector를 결합하여 representation을 만들기 때문에 deep한 representation을 만들 수 있다.
ELMo에서 사용한 feature-based approach는 feature extraction방법으로 pre-train된 representation의 gradient를 업데이트를 진행하지 않는다. Layer의 context representation을 추출한 뒤 이를 선형결합한 값을 input으로 사용한다. 그리고 input을 넣어 feature extraction을 진행한다.
ELMo와 다른 pre-train LM과 차이점은 pre-train LM은 fine-tuning할 때, representation에 대한 학습을 진행하지만 ELMo는 representation의 선형계수(lambda)만 학습을 진행한다는 점이 다르다.
1.Introduction
오늘 소개할 논문은 OpenAI에서 발표한 GPT 논문 시리즈 중 첫 번째인 Improving Language Understanding by Generative Pre-training 입니다.
기존 NLP를 이용한 task에서는 unlabeled된 데이터는 많지만 label된 데이터는 별로 없어 적절하게 모델에 적용하기 어려웠습니다. 그래서 이러한 unlabeled로 pre-training을 거친 후 특정 task에 맞게 fine-tuning을 하고 모델에 적용을 해서 해결하려고 합니다. 하지만 word-level이상으로 text에 대한 정보를 unlabeled text로 부터 얻기에는 두가지 어려움이 있습니다.
- Unlabeled text의 challenging
-
어떠한 optimization objective가 transfer에 text representation을 학습하는데 효과적인지 불분명합니다. 즉, unsupervised learning을 위해 어떤 task로 model을 학습시켜하는지 어렵다는 점입니다.
-
학습한 representation을 목적에 맞는 task에 효과적으로 transfer하는 동일한 consensus가 없습니다.
그래서 GPT는 Unsupervised pre-training과 supervised fine-tuning을 활용한 semi-supervised 방법으로 접근했습니다. GPT의 목적은 다양한 task에 약간의 조정을 하더라도 transfer 할 수 있는 넓은 representation을 학습하는 것입니다. 이러한 model을 task-agnostic model이라고 합니다.
Unlabeled text를 model의 objective을 통해 학습하여 model의 parameter를 학습한다. -> pre-training
학습된 모델을 task에 맞게 약간의 조정을 하면서 objective에 맞게 설정한다. -> fine-tuning
GPT는 기본적으로 Transfomer의 Decoder 구조를 가지고 있다. 기존 transformer의 decoder 구조는 아래 그림과 같습니다.

GPT는 기존 decoder의 구조에서 Add & Norm을 제외한 block을 더 쌓는 구조로 구성되어있습니다. GPT는 transfer하는 과정에서 input을 task에 맞게 조정하는 방법을 이용합니다.
본 논문은 GPT의 성능을 확인하기 위해 NLI(Natural Language inference) , Q&A, Semantic Similarity, Text Classification에 해당하는 task에 적용했고 성능을 많이 상승시켰다는 것을 확인했다고 합니다. 또한 label의 분포를 예측하는 zero-shot의 특성 또한 확인했다고 합니다.
2. Related Work
2.1 Semi-supervised learning for NLP
Unlabeled data를 pre-train하여 word-level이상의 text에 대한 정보를 얻어 supervised-model에 사용하여 fine-tuning하는 방법이 주목을 받았고 word-level뿐만 아니라 pharse-level, sentence-level를 목표로 연구해왔습니다.
2.2 Unsupervised pre-training
Unsupervised pre-training은 semi-supervised learning의 특별한 case이고 supervised learning objective를 바꾸는 대신 good initialization point를 찾는것이 목표입니다. pre-training한 model을 다른 많은 task에 적용할 수 있도록 만드는것이 목적이고 실제로 여러 task에 적용 했을 때, 성능 항상에 많은 도움이 되고 있습니다.
논문에서는 transformer의 decoder 구조를 통하여 더 깊은 정보를 얻을 수 있다고 주장했고, 더 많은 task를 target으로 활용할 수 있다고 주장했습니다. Fine-tuning과는 다른 방법으로 feature-based 방법이 있는데, 이 방법은 pre-train한 model에서 얻은 hidden representation을 supervised model에 feature로 이용하는 방법입니다. 이 방법을 사용하는 대표적인 model은 ELMO가 있지만 GPT model보다 더 많은 parameter를 요구합니다.
3. Framework
앞서 얘기했듯이, 학습은 두 단계로 진행됩니다. 먼저 Large Dataset에서 Language model을 pre-training하고 labeled data를 사용하여 discriminative task에 model을 fine-tuning 합니다.
3.1 Unsupervised pre-training
Labeling 되지 않은 corpus의 token 에 대해서 likelihood를 최대화 하는 방향으로 학습이 진행됩니다.
< k는 window size를 의미하고, P는 neural network를 통해서 modeling된 조건부 확률이고 는 parameter입니다. >
GPT는 transfomer의 decoder를 가져와 여러 층으로 쌓여진 구조를 가지고 있습니다.

(출처 : https://blog.floydhub.com/gpt2/)
Multi-headed Self-Attention 연산을 모든 입력 토큰에 수행하고 결과가 Feedfoward layer의 입력으로 들어갑니다.
- 는 token의 context vector
- n은 layer의 개수
- 는 token embedding의 matrix
- 는 Position Embedding의 matrix
- transfomer는 transformer의 decoder(12개로 구성)
첫번째 hidden state인 은 토큰 에 token embedding의 matrix를 곱한 것과 Position Embedding의 matrix를 더해줘서 만듭니다. 그 다음에 번째 hidden state는 번째 hidden state vector를 입력으로 받아서 transfomer의 decoder block을 통과시킨것이 이고 이 과정을 n번 만큼 반복하여 softmax를 통해서 다음 토큰을 예측합니다.

GPT의 decoder block을 좀 더 자세하게 보자면, GPT는 현재 토큰의 이전것들만 사용하는 masked self_attention을 사용합니다. 그리고 기존 transformer의 구조인 encoder - decoder cross-attention이 빠지고 바로 feed foward neural network가 옵니다. 이 block이 하나의 decoder block이고 이것을 쌓는 개수는 hyper-parameter가 됩니다.
3.2 Supervised fine-tuning
Labeled된 dataset의 입력이 이고 label y라고 구성이 된다고 했을 때, 입력들은 transformer의 최종 block의 활성값인 을 얻기 위하여 pretrained modeld에 전달되고 이 output이 label y를 예측하기 위해 parameter인 와 함께 linear layer로 전달됩니다. 또한 objective를 최대화 하도록 따르게 됩니다.
또한 논문에서는 fine-tuning을 하는 과정에서 보조 objective function, 앞서 pretraining의 objective function을 사용했을 때 Supervised Model의 Generalization을 향상시키고 빠르게 수렴할 수 있게 해준다는 장점이 있다고 했습니다.
3.3 Task-specific input transformations
GPT는 조금의 변화를 주면서 다양한 target task에 적용이 가능한 language model입니다. 아래의 그림을 보면 4가지의 task, classification, entailment, similarity, QA가 있는데 입력과 출력의 구조 변화만으로도 좋은 성능을 보여줍니다.

- Classification의 경우는 기존의 방법 그대로 fine-tuning을 진행하면 됩니다.
- Entailment는 premise를 통해 hypothesis의 참과 거짓을 밝히는 task입니다. 그러므로 Delimeter로 나누어진 premise token과 hypothesis token을 concatenate하고 fine-tuning을 하여 진행합니다.
- Similarity는 문장과 문장 사이에 순서가 존재하지 않기 때문에 두개 순서를 모두 고려해야합니다. 두가지 모두 input을 하여 얻은 output인 을 element-wise한 결과를 바탕으로 fine-tuning을 합니다.
- Multiple choice의 경우 context{}에 대한 question{}이 제시가 되고 그에 대한 답변인 Answer{}가 존재합니다. 로 concatenate되고 답변의 개수는 입력의 개수만큼 생성이 됩니다.
4. Experiments
4.1 Unsupervised pre-training
GPT는 BooksCorpus dataset을 이용해서 학습되었고, 발행되지 않은 책들도 포함되어 있습니다. Data는 상대적으로 긴 문장들이 포함되어 있어서 long-range information을 학습하는데 적합했습니다. 1B Word Benchmark를 사용했습니다.
4.2 Pre-training Model Setup
GPT model은 기본적으로 transfomer의 구조를 가지고 있고, 12개의 decoder layer를 masked self-attention head를 이용해서 구현했습니다. Optimization으로는 learning rate가 2.5e-4로 조정된 Adam을 사용했고 learning rate는 처음 2,000에서 증가시키다가 cosine schedule에 따라서 천천히 0으로 수렴되었습니다. Random하게 sampling된 64개의 mini-batch를 사용했고 100 epoch동안 학습해습니다. L2 regualrization을 사용했고 BPE를 사용했습니다. BPE란 토큰화기법으로 OOV를 해결하고 단어 수를 줄일 수 있는 방법입니다. Activation function으로는 GELU(Gaussian Error Linear Unit)을 사용했습니다.
4.3 Fine-Tuning Model Setup
모두 동일한 parameter를 사용하고 0.1의 dropout을 적용하고, 6.25e-5의 learning-rate와 32크기의 batch-size를 사용했다. 특정 Target task에 대해 3번의 epoch를 진행했습니다.
4.4 Supervised fine-tuning

Natural Language Inference (NLI)
먼저 NLI는 두 쌍의 문장에 대해서, 두 문장의 관계가 entailment, contradiction, neutral인지 판단하는 task이다. NLI task는 lexical entailment, coreference, lexial/semantic ambiguity 등의 복잡한 요소들이 존재하여 어려운 task입니다. 본 논문에서는 총 5개의 dataset, SNLI, MNLI, QNLI, SciTail, RTE에 대해서 성능을 측정했습니다.
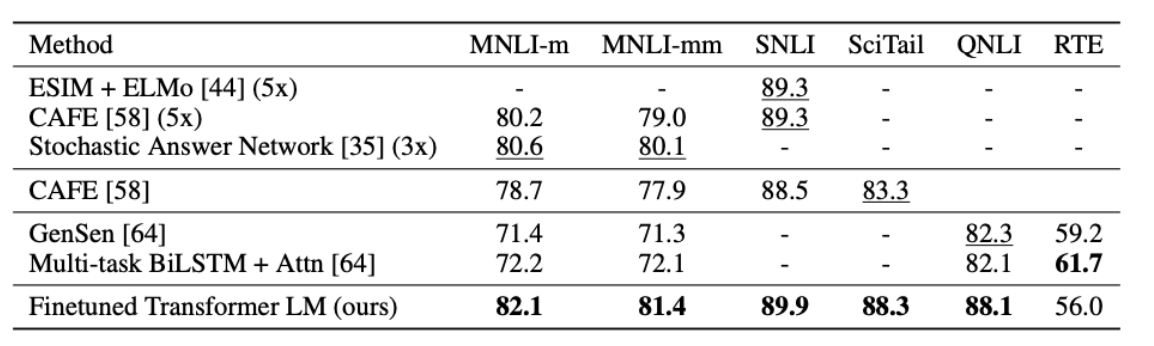
위의 표를 보면 GPT는 모든 dataset에 대해서 성능이 baseline을 넘어선 것을 확인할 수 있습니다.
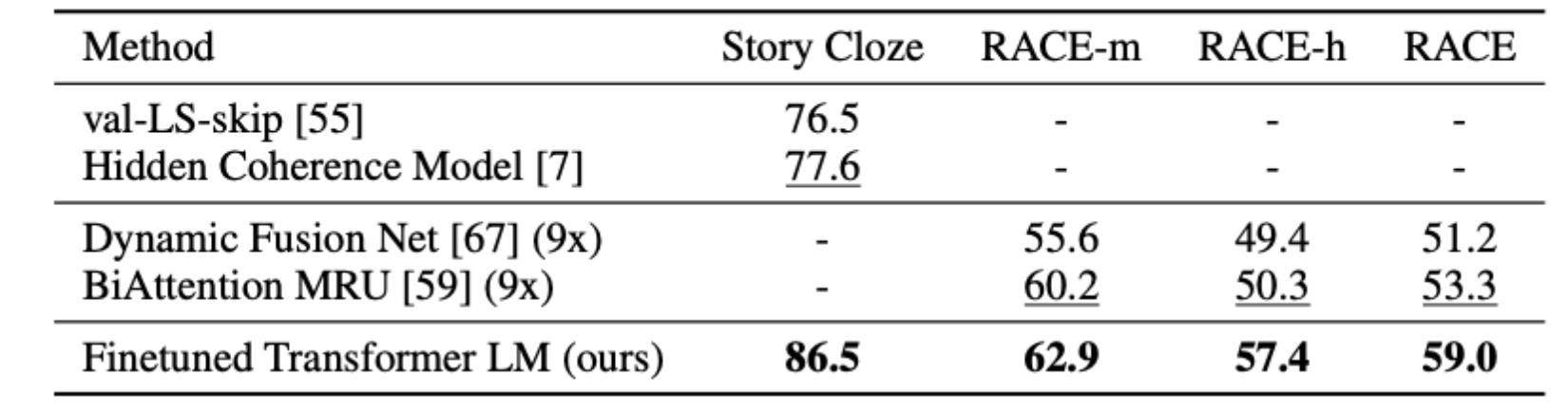
Question answering and commonsense reasoning
Question answering task의 dataset은 Race dataset와 Story Cloze라는 dataset을 사용했고 모두 긴 context가 포함된 dataset을 사용함으로써 long-range context에도 좋은 성능을 보여주는지 확인했습니다.
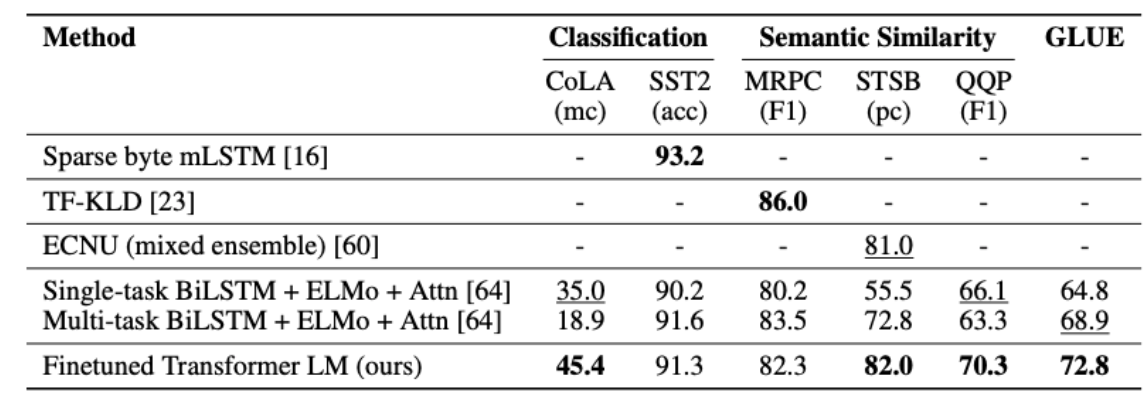
Semantic Similarity
Semantic Similarity는 두 문장이 의미적으로 유사한지 판단하는 task입니다. 해당 task에서는 총 3가지의 dataset을 사용했는데, MRPC, QQP, STS-B 모두 SOTA를 달성했습니다.
Classification
Classification task에서는 CoLA(The Corpus of Linguistic Acceptability)와 SST-2(The Stanford Sentiment Treebank)를 사용했습니다. CoLA는 문장이 문법적으로 맞는지를 판단하는 dataset이고 SST-2는 영화 comment로 긍정인지 부정인지를 판단하는 dataset입니다. 또한 GLUE(General Language Understanding Evaluation)라는 metrics도 사용되었는데 GPT model은 12개의 dataset중 9개에서 SOTA를 달성했고 5.7k의 작은 dataset부터 550k의 큰 dataset까지 좋은 성능을 내는것을 확인할 수 있었습니다.
5. Analysis
5.1 Impact of number of layers transfered
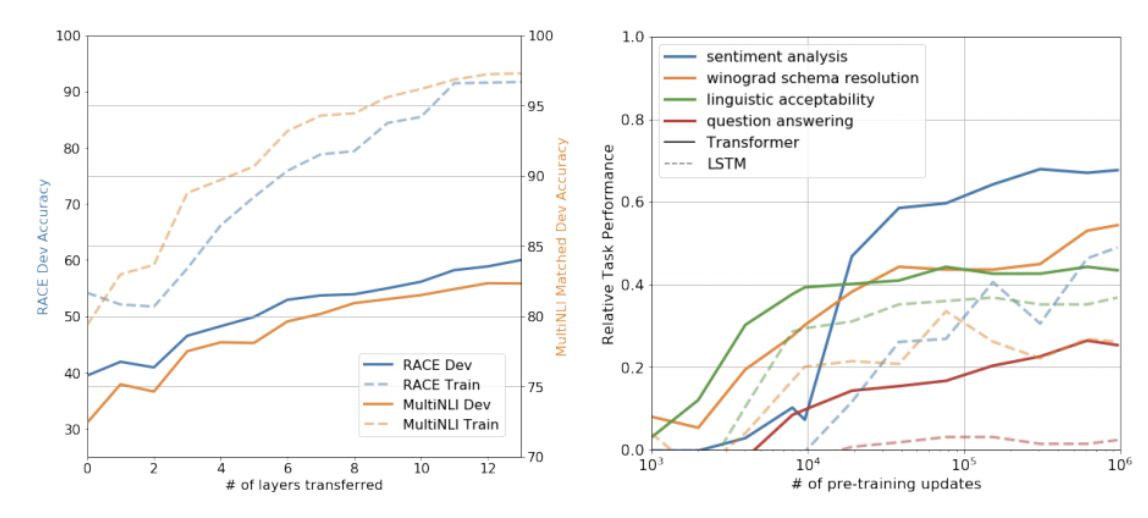
본 논문은 다양한 layer 개수를 unsupervised pre-training 에서 supervised target task로 전환할 때 성능을 분석했습니다. 위 그래프의 왼쪽은 MultiNLI와 RACE에서 전환하는 layer의 개수가 많을수록 성능이 좋아진다는 결과를 시사했고 이것은 pre-trained된 model의 layer가 target task를 수행하기위해 다양한 학습을 한다는것을 알 수 있었습니다.
5.2 Zero-shot Behaviours
본 논문은 GPT가 model의 성능을 향상시키기 위해 많은 task를 수행하는법을 배우고 attentional memory가 LSTM에 비해 더 효과적이라고 가설을 세웠습니다. 오른쪽 그래프를 보면 pre-training만 했을때 성능을 확인할 수 있는데 pre-training을 많이 할수록 다양한 task에서 성능이 증가하는것을 확인할 수 있습니다.
5.3 Ablation Studies

동일한 model에 대해서 여러 실험을 해봤습니다. fine-tuning 과정에서 보조적인 LM을 제외하고 성능을 확인한 결과 dataset이 크면 보조적인 LM의 영향을 많이 받지만 dataset이 작을경우 영향을 적게 받는것을 확인할 수 있습니다. 또한 transfomer의 성능을 확인하기 위해 LSTM층을 추가했는데 성능이 하락한것을 확인할 수 있었습니다.
