1. Background
CLIP : Contrastive Language-Image Pretrained model 은 ImageNet 데이터셋보다 30배 이상 많은 웹 상의 (Image-Text) pair를 대조학습을 통하여 general 한 image representation prediction을 수행할 수 있도록 설계된 딥러닝 모델이다.
예를 들어, Google에 'a white dog with black spots' 라고 검색하면 아래와 같이 흰 피부에 검정색 점을 가진 강아지 사진들이 서로 비슷한 모양으로 검색결과에 나오는 것을 볼 수 있다.
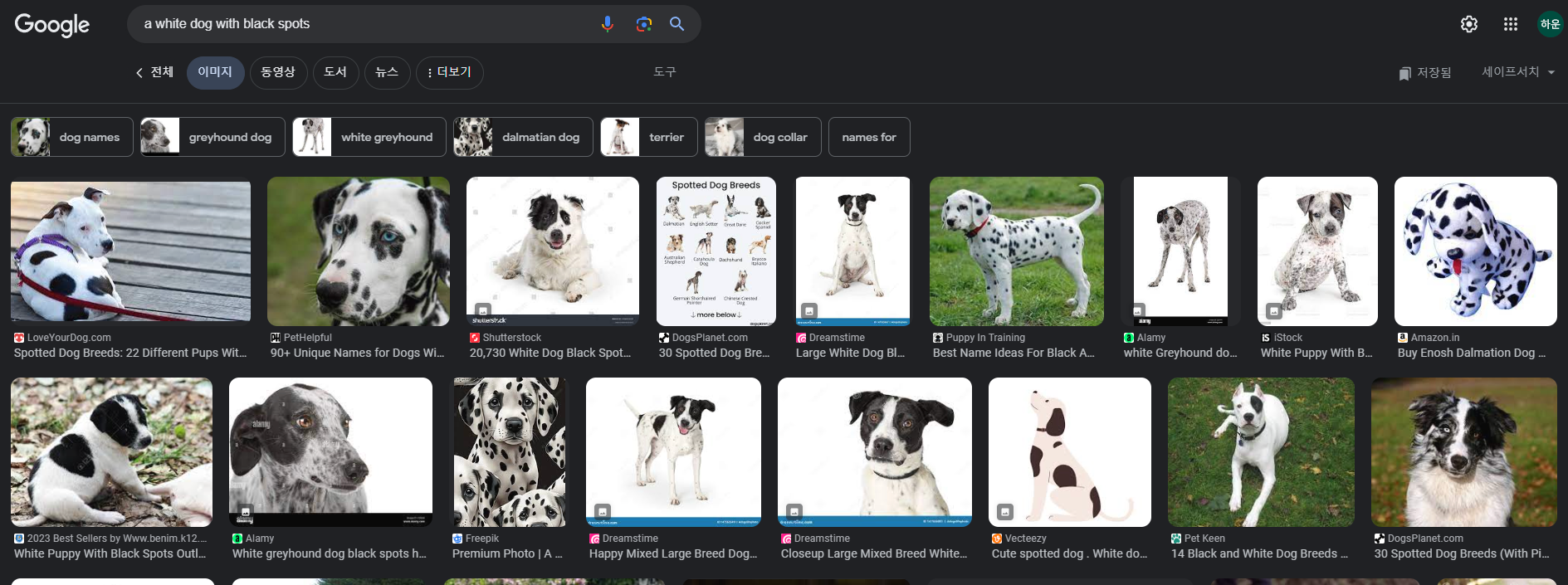
우리는 이 이미지들을 '달마시안' 이라는 한 단어로 표현을 할 수 있기도 하지만 '검은 점을 가진 흰색 개', '풀밭에 누워있는 점박이 개', '얼룩무늬를 가진 강아지' 라는 문장, 즉 Caption을 가지고 이미지를 표현할 수도 있다.
CLIP의 Idea
사실 인스타그램, 메타, Pinterest 등 수많은 이미지들이 존재하는 소셜 네트워크 상에서는 이미지를 한 단어로 표현하기보다는 위의 예시와 같이 특정 문장 형태로 respresent하는 경우가 대부분이다. 사람들은 이미지와 게시글을 올릴 때 한 단어만 띡 올린다기보다는 그 이미지에 대한 설명을 꼭 달기 마련이다. OpenAI의 CLIP 모델은 바로 이 부분을 주목한다.
웹 상에 떠도는 대량의 이미지들을 학습하는 거대 예측 모델을 학습하기 위해서는 수많은 이미지 데이터와 그에 해당하는 label(Supervision의 경우)을 붙여주는 작업이 필요한데, label을 따로 하지 않고 그 이미지에 딸려 있는 Caption을 함께 학습하도록 하면 작업의 효율성이 극대화된다.
결국 CLIP은 (Image-text) 를 함께 학습시키는 Multimodal traning을 수행하기 위해서 ViT와 Transformer 모델을 함께 사용한다.
그런데,
그러면 Prediction의 과정은 어떻게 수행되는가? 라는 질문이 자연스럽게 떠올려진다.
우리는 사전학습된 text label을 모른다.
Prompts
CLIP의 Prediction은 독특하게도 예측 단계에서 input으로 예측할 이미지와 후보 prompts를 넣는다. 여기서 예측할 이미지는 prediction할 이미지이고, prompts는 해당 이미지의 정답 후보가 들어있는 text 리스트를 말한다. 가령 예를 들면 input image가 강아지 사진일 때, prompts를 ['강아지', '고양이', '쥐'] 라고 주면 모델은 저 셋 후보군 중에서 강아지 사진과 가장 높은 유사도를 갖는 텍스트를 답으로 내놓게 되는 것이다.
2. CLIP - Prompt engineering?
CLIP 논문의 저자도 마찬가지로, CLIP에 대한 많은 리뷰어들은 CLIP의 Zero-shot Prediction 과정에서 Prompt engineering의 중요성을 강조한다. 왜일까?
아까 Background에서 설명했던 것과 같이, CLIP 모델은 수 억개의 Image-Text pair를 학습하기 때문에, prediction을 할 때도 학습했을 때와 같이 input에 주어지는 prompt가 학습했을 때의 text와 유사한 형식을 갖고 있어야 성능이 잘 나올 수 있다. 이는 사용자의 engineering에 따라서 모델의 정확도가 달라질 수 있다는 신기한 특징을 갖고 있음을 나타낸다.
Problem
문제는 Prompts를 어떻게 작성해야 성능이 올라간다는 100% 정확한 공식같은 것이 존재하지 않는다는 것이다. 왜냐하면 학습에 사용된 수많은 Text가 어떻게 구성되어 있는지 하나하나 알 방법이 없고, 만약 있는다 하더라도 파악하는 데 막대한 시간과 비용이 필요할 것이기 때문이다.
CLIP의 ImageNet zero-shot을 위한 Prompt engineering
CLIP github에서는 ImageNet 데이터셋에 대한 zero-shot 성능을 측정하기 위해 다음과 같은 Prompt engineering 방식을 적용했다.
imagenet_classes = ["tench", "goldfish", "great white shark", "tiger shark", "hammerhead shark", "electric ray", "stingray", "rooster", "hen"]
#ImageNet에 있는 class로, 10000개로 나머지 class는 생략imagenet_templates = [
'a bad photo of a {}.',
'a photo of many {}.',
'a sculpture of a {}.',
'a photo of the hard to see {}.',
'a low resolution photo of the {}.',
'a rendering of a {}.',
'graffiti of a {}.',
'a bad photo of the {}.',
'a cropped photo of the {}.',
'a tattoo of a {}.',
'the embroidered {}.',
'a photo of a hard to see {}.',
'a bright photo of a {}.',
'a photo of a clean {}.',
'a photo of a dirty {}.',
'a dark photo of the {}.',
'a drawing of a {}.',
'a photo of my {}.',
'the plastic {}.',
'a photo of the cool {}.',
'a close-up photo of a {}.',
'a black and white photo of the {}.',
'a painting of the {}.',
'a painting of a {}.',
'a pixelated photo of the {}.',
'a sculpture of the {}.',
'a bright photo of the {}.',
'a cropped photo of a {}.',
'a plastic {}.',
'a photo of the dirty {}.',
'a jpeg corrupted photo of a {}.',
'a blurry photo of the {}.',
'a photo of the {}.',
'a good photo of the {}.',
'a rendering of the {}.',
'a {} in a video game.',
'a photo of one {}.',
'a doodle of a {}.',
'a close-up photo of the {}.',
'a photo of a {}.',
'the origami {}.',
'the {} in a video game.',
'a sketch of a {}.',
'a doodle of the {}.',
'a origami {}.',
'a low resolution photo of a {}.',
'the toy {}.',
'a rendition of the {}.',
'a photo of the clean {}.',
'a photo of a large {}.',
'a rendition of a {}.',
'a photo of a nice {}.',
'a photo of a weird {}.',
'a blurry photo of a {}.',
'a cartoon {}.',
'art of a {}.',
'a sketch of the {}.',
'a embroidered {}.',
'a pixelated photo of a {}.',
'itap of the {}.',
'a jpeg corrupted photo of the {}.',
'a good photo of a {}.',
'a plushie {}.',
'a photo of the nice {}.',
'a photo of the small {}.',
'a photo of the weird {}.',
'the cartoon {}.',
'art of the {}.',
'a drawing of the {}.',
'a photo of the large {}.',
'a black and white photo of a {}.',
'the plushie {}.',
'a dark photo of a {}.',
'itap of a {}.',
'graffiti of the {}.',
'a toy {}.',
'itap of my {}.',
'a photo of a cool {}.',
'a photo of a small {}.',
'a tattoo of the {}.',
]이와 같이 단어로 구성된 imageNet_class 와, 이 classes를 문장 형식으로 mapping해줄 수 있는 imagenet_templates 를 작성해준 뒤에, Prediction 가능한 형태로 tokenize를 해준다.
3. Results
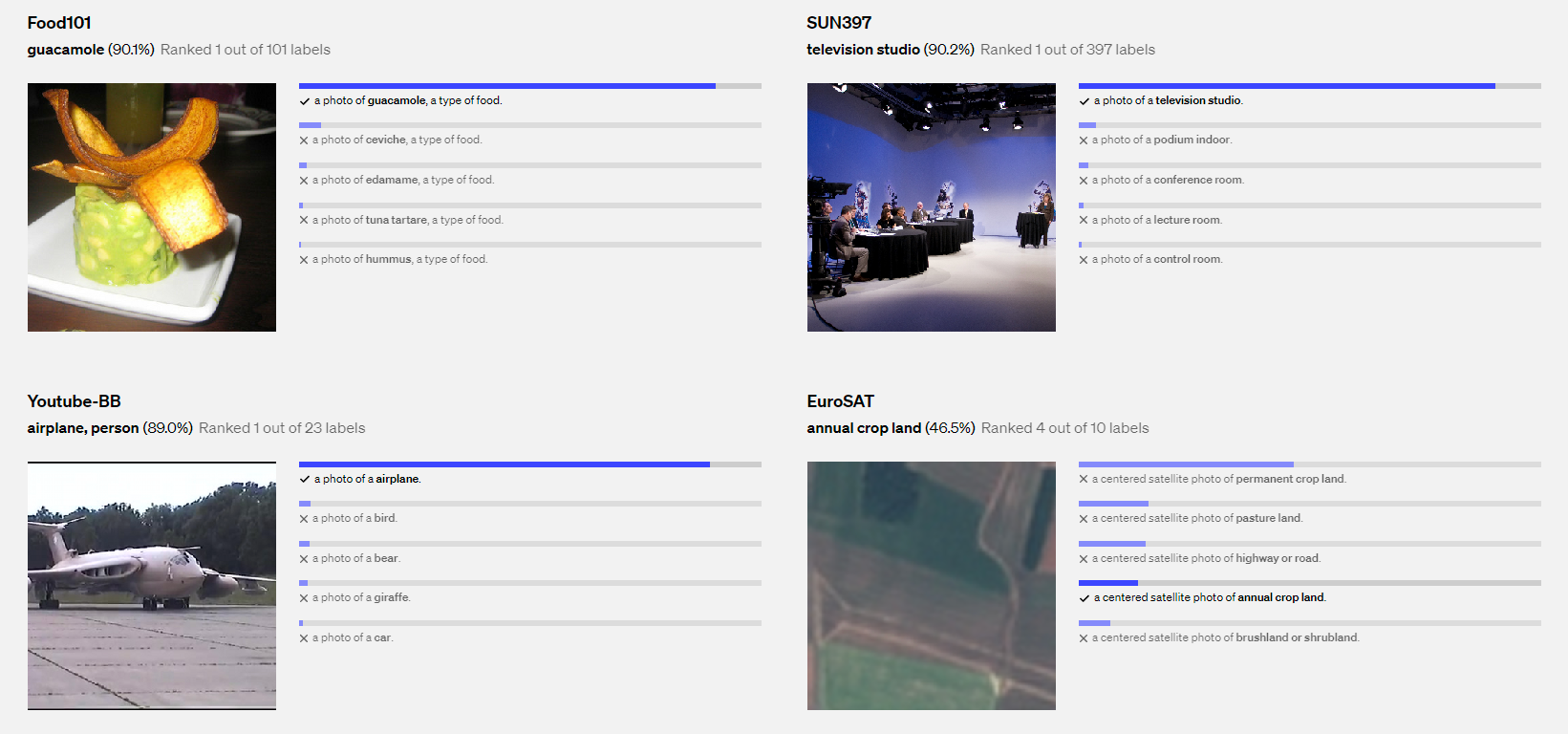
이렇게 했을 때, CLIP 모델은 사전 학습 모델에서 학습했던 Image-text 쌍과 거의 유사한 형태로 inference를 진행할 수 있도록 하는 것 같다. 물론 이로 인한 zero-shot 정확도도 높게 나왔다.
하지만 CLIP 논문은 결과적으로 general하고 simple한 task에만 높은 zero-shot 정확도를 갖는 것으로 결론이 지어졌다. 이는 구체적인 downstream task에 대하여 prediction에는 기대한 성능을 나타내지 못함을 보여주고 있는데, 아마 이 성능을 높이기 위해서는 해당 task에 효과적으로 적용될 수 있는 prompt engineering이 필요하지 않을까 싶다는 의견을 갖는다. 이와 같이 prompt engineering은 수많은 실험과 증명이 요구되는 새로운 토픽이라고 생각한다.
