1. 깊이 우선 탐색(DFS)
자료의 검색, 트리나 그래프를 탐색하는 방법. 한 노드를 시작으로 인접한 다른 노드를 재귀적으로 탐색해가고 끝까지 탐색하면 다시 위로 와서 다음을 탐색하여 검색한다.
- 출처: [컴퓨터인터넷IT용어대사전]
자료 1) 깊이 우선 탐색의 예시
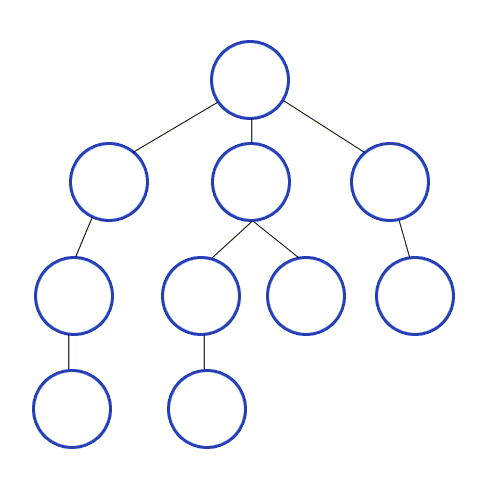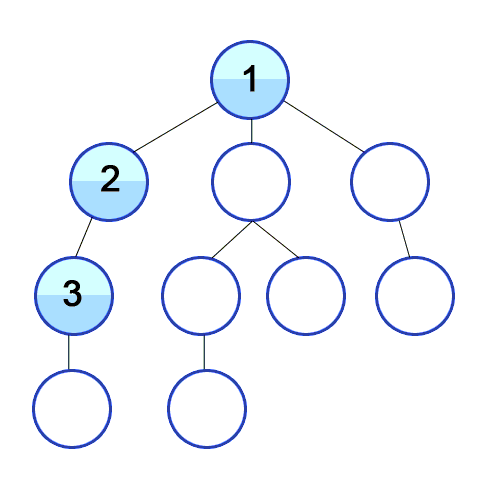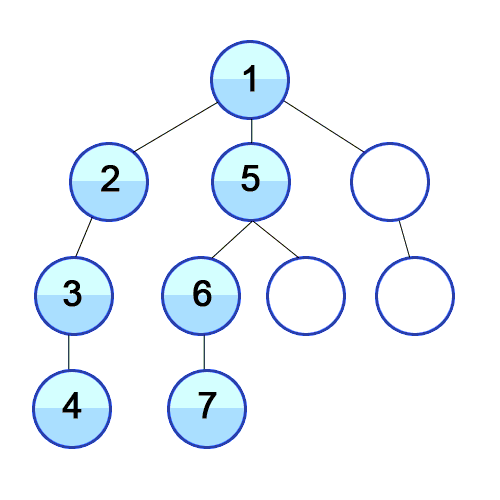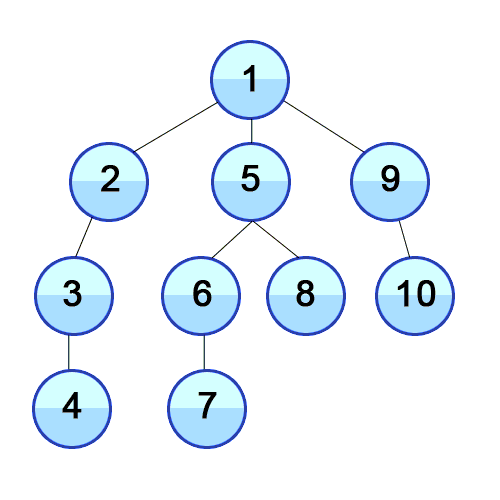
출처: 위키백과
2. 깊이 우선 탐색의 장점과 단점
장점
- 단지 현 경로상의 노드들만을 기억하면 되므로 저장공간의 수요가 비교적 적다.
- 목표노드가 깊은 단계에 있을 경우 해를 빨리 구할 수 있다.
단점
- 해가 없는 경로에 깊이 빠질 가능성이 있다. 따라서 실제의 경우 미리 지정한 임의의 깊이까지만 탐색하고 목표노드를 발견하지 못하면 다음의 경로를 따라 탐색하는 방법이 유용할 수 있다. 즉, 탈출 조건을 정해줘야 한다.
- 얻어진 해가 최단 경로가 된다는 보장이 없다. 이는 목표에 이르는 경로가 다수인 문제에 대해 깊이우선 탐색은 해에 다다르면 탐색을 끝내버리므로, 이때 얻어진 해는 최적이 아닐 수 있다는 의미이다.
3. DFS의 구현
깊이우선탐색은 재귀함수, 혹은 자료구조의 하나인 스택(stack)으로 구현이 가능하다.
그러나 여기서 탈출 조건 없이 재귀함수를 이용할 때 무한정 깊어지는 노드가 있는 경우 에러가 발생 할 수 있다!
따라서 스택을 이용하여 구현하는 것이 좀 더 안정적이다.
스택을 이용하여 DFS를 구현 할 경우 다음의 과정을 고려한다.
1. 루트 노드를 스택에 넣는다.
2. 현재 스택의 노드를 빼서 방문 확인 리스트에 추가한다.
3. 현재 방문한 노드와 인접한 노드 중 방문하지 않은 노드를 스택에 추가한다.
4. 2번의 과정부터 다시 반복한다.
5. 스택이 비면 탐색을 종료한다.
def dfs_stack(adjacent_graph, start_node):
stack = [start_node]
visited_arr = []
while stack:
current_node = stack.pop()
visited_arr.append(current_node)
for adjacent_node in adjacent_graph[current_node]:
if adjacent_node not in visited_arr:
stack.append(adjacent_node)
return visited_arr자료 2) DFS의 구현
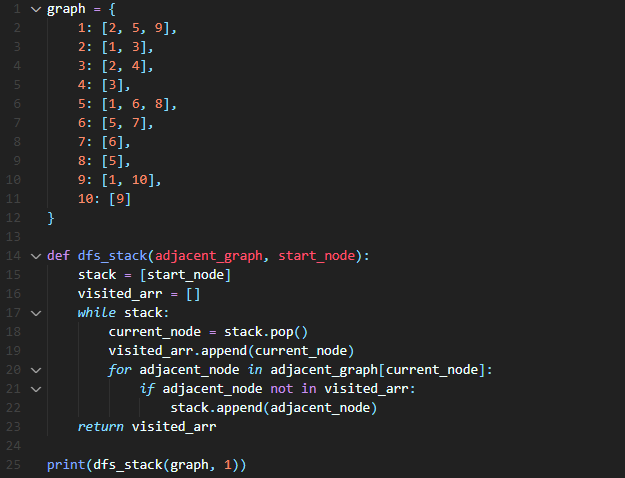
해당 코드를 실행하면 깊이우선탐색을 통해 모든 노드를 순회함을 알 수 있다!

조금 늦어도 꾸준하게