해시테이블
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다. 해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 한다.
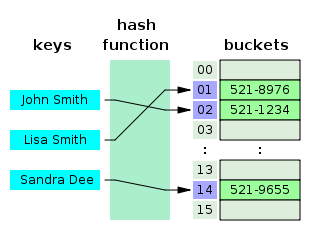
예를 들어 우리가 (Key, Value)가 ("John Smith", "521-1234")인 데이터를 크기가 16인 해시 테이블에 저장한다고 하자. 그러면 먼저 index = hash_function("John Smith") % 16 연산을 통해 index 값을 계산한다. 그리고 array[index] = "521-1234" 로 전화번호를 저장하게 된다.
이러한 해싱 구조로 데이터를 저장하면 Key값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되므로 매우 빠르게 데이터를 저장/삭제/조회할 수 있다. 해시테이블의 평균 시간복잡도는 O(1)이다.
셋
Set(세트)는 우리가 흔히 수학에서 배웠던 집합의 개념과 같다. 즉, 중복되지 않는 항목들이 모인 것을 Set(세트)라한다.
Set는 순서가 없다. 만약, 순서가 필요없고 고유값을 원한다면 Set가 최선의 자료구조이다.
셋의 특징
- 데이터를 비순차적(unordered)으로 저장할 수 있는 자료구조
- 삽입(Insertion) 순서대로 저장되지 않는다.
- 수정이 가능하다
- 동일한 값을 여러번 삽입이 불가능하다. 동일한 값이 여러번 삽입되면 나중에 들어온 값으로 치환된다.
- Fast Lookup 이 필요할 때 사용된다.
- 고유값을 찾고자 할 때 사용된다.
- set는 array에 저장된다(Bucket)
Object와 Map의 차이
- key
- Map: 타입 제약 없음
- Object: String, Symbol
- {key:value} 수
- Map: size 프로퍼티로 구함.
- Object: 전체를 읽어서 구해야 합니다.
- 처리 시간: MDN
- key, value의 추가 삭제가 빈번할수록 Map이 더 뛰어난 성능을 보여줍니다.
Array와 Set의 차이
Set과 Array를 구별하는 Set의 가장 큰 특징은 중복된 값을 허용하지 않는다는 것이다.

나