📅 공부 기간 : 07. 23(화)
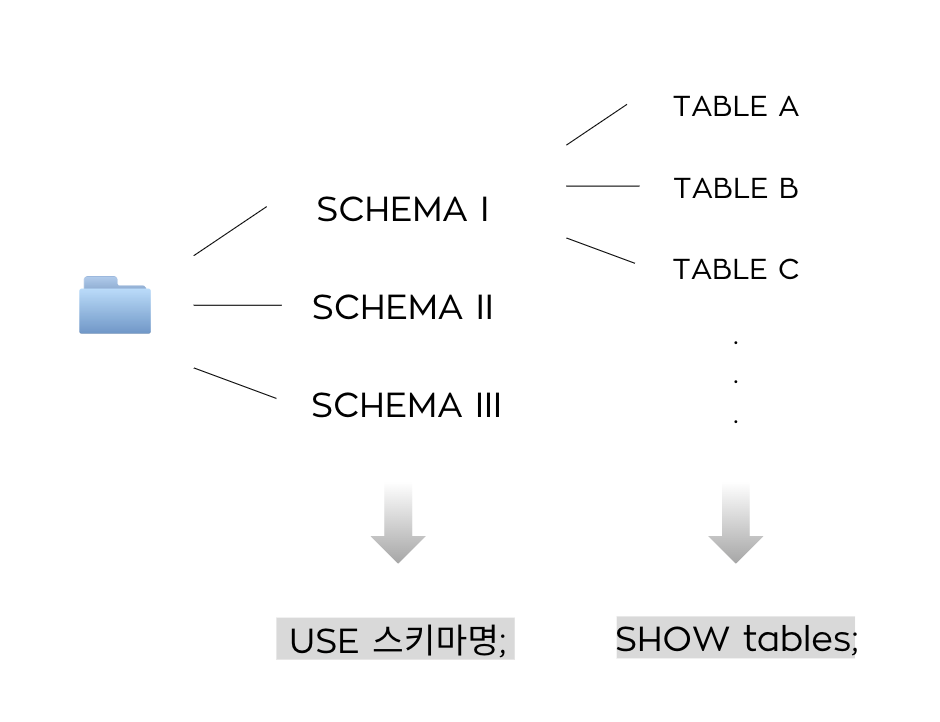
Schema(스키마) = Database(데이터베이스)
CREATE
- 테이블 생성
CREATE TABLE sample
(
seq int AUTO_INCREMENT PRIMARY KEY -- auto_increment : 자동으로 pk 상승
, name varchar(15) NOT NULL
, address varchar(100)
, age decimal(3) DEFAULT 0
);INSERT
INSERT한 후에는 복사본이 생성되는 것이기 때문에 꼭COMMIT해서 원본에 저장
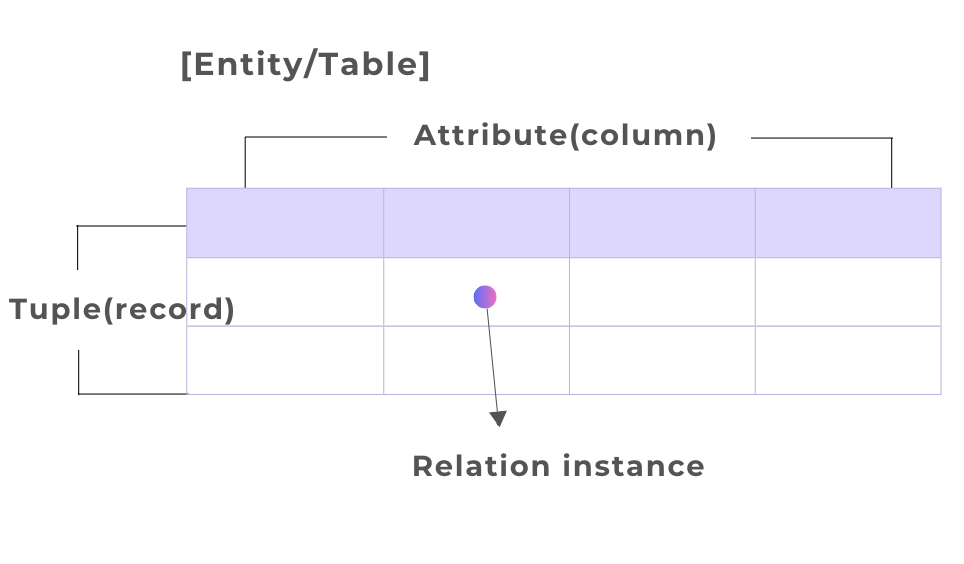
- relation instance 값 채우기
INSERT INTO sample
(name, address, age)
VALUES
('저팔계', '서울시 강남구', 27);
COMMIT;SELECT
- 테이블의 내용을 조회
SELECT 컬럼명 FROM 테이블명;
SELECT DISTINCT 컬럼명 FROM 테이블명 -- 중복된 컬럼 삭제
WHERE절과 연산자
- 비교 연산자 : =, !=, >=, <=, >, <
- 논리 연산자 :
AND,OR,NOT - BETWEEN 연산자 :
BETWEEN AND(~이상 ~이하) IS NULL,IS NOT NULL- LIKE 연산자 : 문자열 내에 포함된 특별한 문자값을 찾아서 조회할 때
- IN 연산자
- LIMIT 연산자(건너뛸 개수, 조회할 개수)
-- [연습] 급여가 5000 이상 10000 이하인 직원의 사원번호, 이름, 급여, 직급을 조회하시오
SELECT employee_id, first_name, salary, job_id
FROM employees e
WHERE salary >= 5000 AND salary <= 10000;
-- [연습] BETWEEN 연산자를 이용하여 위의 문제를 수정
SELECT employee_id, first_name, salary, job_id
FROM employees e
WHERE salary BETWEEN 5000 AND 10000
ORDER BY salary DESC ;
-- [연습] 이름이 'J'로 시작하는 직원의 이름과 부서를 조회하시오
SELECT FIRST_name, department_id
FROM employees e
WHERE first_name LIKE 'J%';
-- [연습] 이름이 'n'으로 끝나며 이름이 5자인 직원의 이름과 부서를 조회하시오
SELECT FIRST_name, department_id
FROM employees e
WHERE first_name LIKE '____n';
-- [연습] 사원번호가 145번이거나 147번, 158번인 사람을 조회
-- 사원번호, 이름, 전화번호
SELECT employee_id, first_name, phone_number
FROM employees e
WHERE
employee_id IN (145, 147, 158);
-- 맨 앞에서부터 10개 건너뛰고, 10개 조회
SELECT employee_id, first_name, salary
FROM employees e
LIMIT 10, 10;IN 연산자는 같은 컬럼 내 중복되는 정보를 찾을 경우 사용
제약조건
데이터의 오류를 줄이고 견고하게 만들기 위해 설정
- PK(Primary Key) : 기본키에 입력되는 값은 중복될 수 없으며 NULL 값이 입력될 수 없음
- CHECK : 실수 입력 방지
- DEFAULT : 기본값 설정
- NOT NULL : 값을 꼭 입력

인류의 위대한 대화에 참여하기 위해 다양한 언어를 탐구합니다.