코드잇의 알고리즘의 정석 수업을 수강하고 정리한 글입니다.
정확하지 않거나 빠트린 내용이 있을 수 있기 때문에 강의를 수강하시길 권장합니다.
이전 포스트에서 그리디 알고리즘에 대한 개념과 장단점을 정리했다.
그리고 문제가 주어졌을 때 그리디 알고리즘을 통해 최적의 답을 보장받을 수 있는지 확인하는 법을 배웠다.
이번 포스트에서도 계속해서 문제를 분석하고 그리디 알고리즘으로 풀어본다.
7. 지각 벌금 적게 내기 분석
익중이네 밴드부는 매주 수요일 오후 6시에 합주를 하는데요. 멤버들이 너무 상습적으로 늦어서, 1분에 1달러씩 내야 하는 벌금 제도를 도입했습니다.
그런데 마침 익중이와 친구 넷이 놀다가 또 지각할 위기입니다. 아직 악보도 출력해 놓지 않은 상황이죠.
어차피 같이 놀다 늦은 것이니 벌금을 다섯 명이서 똑같이 나눠 내기로 하고, 벌금을 가능한 적게 내는 방법을 고민해 보기로 합니다.
다섯 사람이 각각 출력해야 하는 페이지 수는 3장, 1장, 4장, 3장, 2장입니다. 프린터는 한 대밖에 없고, 1장을 출력하기 위해서는 1분이 걸립니다.
현재 순서대로 출력한다면,
-
첫 번째 사람: 3분 지각
3
-
두 번째 사람: 3+1분 지각
3 + 1
-
세 번째 사람: 3+1+4분 지각
3 + 1 + 4
-
네 번째 사람: 3+1+4+3분 지각
3 + 1 + 4 + 3
-
다섯 번째 사람: 3+1+4+3+2분 지각
3 + 1 + 4 + 3 + 2
총 39달러의 벌금을 내야 합니다.
흠… 더 적게 내는 방법이 있지 않을까요?
출력할 페이지 수가 담긴 리스트 pages_to_print를 파라미터로 받고 최소 벌금을 리턴해 주는 함수 min_fee를 작성해 보세요.
def min_fee(pages_to_print):
# 코드를 작성하세요.
# 테스트
print(min_fee([3, 1, 4, 3, 2]))
32최적 부분 구조가 있는가? (O)
- 각 출력 페이지 수가 3, 1, 4, 3, 2라면 다음과 같이 표현할 수 있다.
min_fee([3, 1, 4, 3, 2]) - 첫번째 사람이 먼저 출력을 한다면? 나머지 모두가 3분씩 기다려야 한다. 그리고 나머지 친구들 사이에서도 순서를 결정해야 한다. 다음과 같이 표현이 가능하겠다.
3 * 5 + min_fee([1, 4, 3, 2]) - 가능한 경우를 모두 보면 다음과 같다.
3 * 5 + min_fee([1, 4, 3, 2])1 * 5 + min_fee([1, 4, 3, 2])4 * 5 + min_fee([1, 4, 3, 2])3 * 5 + min_fee([1, 4, 3, 2])2 * 5 + min_fee([1, 4, 3, 2])각 경우의 부분문제를 모두 풀고 서로 비교하면 최적의 경우를 구할 수 있다. 최적 부분 구조가 존재한다.
탐욕적 선택 속성이 존재하는가? (O)
- 먼저 출력한 사람이 3분 걸리면, 나머지가 모두 3분을 기다려야 한다.
- 기다리는 시간을 최소화 하려면 페이지 수가 적은 사람 순으로 출력하는것이 최선임을 알 수 있다.
- 탐욕적 선택 속성이 존재한다.
최적 부분 구조와 탐욕적 선택 속성이 존재하기 때문에 그리디 알고리즘으로 최적의 솔루션을 구할 수 있다.
8. 지각 벌금 적게 내기
익중이네 밴드부는 매주 수요일 오후 6시에 합주를 하는데요. 멤버들이 너무 상습적으로 늦어서, 1분에 1달러씩 내야 하는 벌금 제도를 도입했습니다.
그런데 마침 익중이와 친구 넷이 놀다가 또 지각할 위기입니다. 아직 악보도 출력해 놓지 않은 상황이죠.
어차피 같이 놀다 늦은 것이니 벌금을 다섯 명이서 똑같이 나눠 내기로 하고, 벌금을 가능한 적게 내는 방법을 고민해 보기로 합니다.
다섯 사람이 각각 출력해야 하는 페이지 수는 3장, 1장, 4장, 3장, 2장입니다. 프린터는 한 대밖에 없고, 1장을 출력하기 위해서는 1분이 걸립니다.
현재 순서대로 출력한다면,
-
첫 번째 사람: 3분 지각
3
-
두 번째 사람: 3+1분 지각
3 + 1
-
세 번째 사람: 3+1+4분 지각
3 + 1 + 4
-
네 번째 사람: 3+1+4+3분 지각
3 + 1 + 4 + 3
-
다섯 번째 사람: 3+1+4+3+2분 지각
3 + 1 + 4 + 3 + 2
총 39달러의 벌금을 내야 합니다.
흠… 더 적게 내는 방법이 있지 않을까요?
출력할 페이지 수가 담긴 리스트 pages_to_print를 파라미터로 받고 최소 벌금을 리턴해 주는 함수 min_fee를 Greedy Algorithm으로 구현하세요.
def min_fee(pages_to_print):
# 코드를 작성하세요.
# 테스트
print(min_fee([6, 11, 4, 1]))
print(min_fee([3, 2, 1]))
print(min_fee([3, 1, 4, 3, 2]))
print(min_fee([8, 4, 2, 3, 9, 23, 6, 8]))# 콘솔 출력
39
10
32
188풀이
- 앞서 살펴봤듯이 이 문제는 탐욕적 선택 속성이 존재한다.
- 탐욕적 선택을 먼저 생각해본다. 페이지가 적은 사람 순으로 출력하는 것이다.
코드
def min_fee(pages_to_print):
fee = 0
sorted_list = sorted(pages_to_print) # 적은사람 순으로 출력하기 위해 정렬한다. (O(nlogn))
for i in range(len(sorted_list)): # O(n)
fee += sorted_list[i] * (len(sorted_list)-i)
return fee
# 테스트
print(min_fee([6, 11, 4, 1]))
print(min_fee([3, 2, 1]))
print(min_fee([3, 1, 4, 3, 2]))
print(min_fee([8, 4, 2, 3, 9, 23, 6, 8]))# 콘솔 출력
39
10
32
188O(nlogn + n)이므로, O(nlogn)으로 볼 수 있다.
9. 수강 신청 분석
이번 학기 코드잇 대학교의 수업 리스트가 나왔습니다.
[(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 6), (13, 16), (9, 11), (1, 8)]리스트에 담겨있는 튜플들은 각각 하나의 수업을 나타냅니다. 각 튜플의 0번째 항목은 해당 수업의 시작 시간, 그리고 1 번 항목은 해당 수업이 끝나는 시간입니다. 예를 들어서 0번 인덱스에 있는 튜플값은 (4, 7)이니까, 해당 수업은 4교시에 시작해서 7교시에 끝나는 거죠.
(2, 5)를 듣는다고 가정합시다. (4, 7) 수업은 (2, 5)가 끝나기 전에 시작하기 때문에, 두 수업은 같이 들을 수 없습니다. 반면, 수업 (1, 3)과 (4, 7)은 시간이 겹치지 않기 때문에 동시에 들을 수 있습니다.
열정이 불타오르는 신입생 지웅이는 최대한 많은 수업을 들을 수 있는 수업 조합을 찾아주는 함수 course_selection 함수를 작성하려고 합니다.
course_selection은 파라미터로 전체 수업 리스트를 받고 가능한 많은 수업을 담은 리스트를 리턴합니다.
템플릿
def course_selection(course_list):
# 코드를 쓰세요
# 테스트
print(course_selection([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 6), (13, 16), (9, 11), (1, 8)]))
[(1, 3), (4, 7), (8, 10), (13, 16)]최적 부분 구조가 있는가? (O)
- 다음 문제가 있다고 가정해보자.
course_selection([(4, 7), (2, 5), (1, 3), (8, 10)]) - 어떤 수업을 선택했느냐에 따라 다음과 같이 가능한 경우를 나눌 수 있다.
[(4, 7)] + course_selection([(2, 5), (1, 3), (8, 10)])[(2, 5)] + course_selection([(8, 10)])[(1, 3)] + course_selection([(4, 7), (8, 10)])[(8, 10)] + course_selection([(4, 7), (2, 5), (1, 3)])
- 각 부분문제를 풀고 서로 비교해서 최적의 수를 선택하면 기준 문제의 최적의 답을 구할 수 있다. 최적 부분 구조가 존재한다.
탐욕적 선택 속성이 존재하는가? (O)
- 탐욕적 선택 속성은 가장 먼저 끝나는 수업을 고르는 것이다.
- 정답 리스트를 answer, 전체 목록을 끝나는 순으로 정렬한 것을 sorted_list라고 할 때 수업 개수가 바뀌지 않고 먼저 끝나는 수업은 포함이 가능하다.
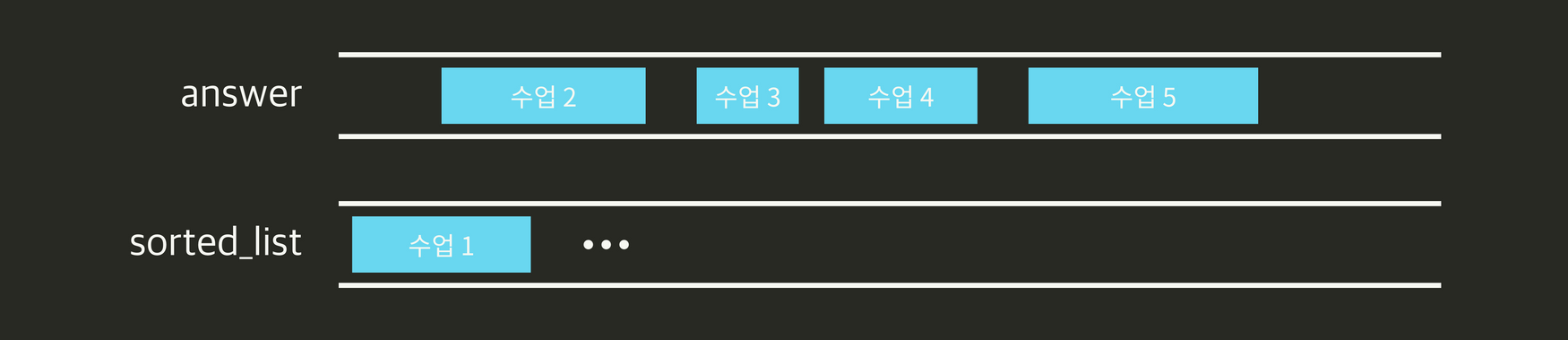
- 즉 남은 수업 중 끝나는 수업을 선택하면 늘 최선의 결과를 이뤄낼 수 있다.
최적 부분 구조와 탐욕적 선택 속성이 존재하기 때문에 그리디 알고리즘으로 최적의 솔루션을 구할 수 있다.
10. 수강 신청
문제
이번 학기 코드잇 대학교의 수업 리스트가 나왔습니다.
[(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 6), (13, 16), (9, 11), (1, 8)]
리스트에 담겨있는 튜플들은 각각 하나의 수업을 나타냅니다. 각 튜플의 0번째 항목은 해당 수업의 시작 교시, 그리고 1 번 항목은 해당 수업이 끝나는 교시입니다. 예를 들어서 0번 인덱스에 있는 튜플값은 (4, 7)이니까, 해당 수업은 4교시에 시작해서 7교시에 끝나는 거죠.
(2, 5)를 듣는다고 가정합시다. (4, 7) 수업은 (2, 5)가 끝나기 전에 시작하기 때문에, 두 수업은 같이 들을 수 없습니다. 반면, 수업 (1, 3)과 (4, 7)은 시간이 겹치지 않기 때문에 동시에 들을 수 있습니다.
(단, (2, 5), (5, 7)과 같이 5교시에 끝나는 수업과 5교시에 시작하는 수업은 서로 같이 듣지 못한다고 가정합니다)
열정이 불타오르는 신입생 지웅이는 최대한 많은 수업을 들을 수 있는 수업 조합을 찾아주는 함수 course_selection 함수를 작성하려고 합니다.
course_selection은 파라미터로 전체 수업 리스트를 받고 가능한 많은 수업을 담은 리스트를 리턴합니다.
def course_selection(course_list):
# 코드를 작성하세요.
# 테스트
print(course_selection([(6, 10), (2, 3), (4, 5), (1, 7), (6, 8), (9, 10)]))
print(course_selection([(1, 2), (3, 4), (0, 6), (5, 7), (8, 9), (5, 9)]))
print(course_selection([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 5), (13, 16), (9, 11), (1, 8)]))# 콘솔 출력
[(2, 3), (4, 5), (6, 8), (9, 10)]
[(1, 2), (3, 4), (5, 7), (8, 9)]
[(1, 3), (4, 7), (8, 10), (13, 16)]풀이
- 최적 부분 구조가 존재하고, 탐욕적 선택 속성이 존재하기 때문에 그리디 알고리즘을 적용한다.
- 탐욕적 선택 속성은 가장 먼저 끝나는 수업을 선택하는 것이다.
- 이미 고른 수업이 끝나는 시간이 다른 수업이 시작하는 시간보다 늦으면 두 수업은 겹친다고 볼 수 있다.
코드
내가 푼 코드
def conflict_schedule(course1, course2):
# 겹치는 수업임을 판별하는 함수다.
# 풀이의 3번째 원칙을 생각하지 못해서 비효율적인 함수를 작성하였다.
course1_times = list(range(course1[0], course1[1]+1))
course2_times = list(range(course2[0], course2[1]+1))
for course1_time in course1_times:
for course2_time in course2_times:
if course1_time == course2_time:
return True
return False
def course_selection_recursive(course_list):
if len(course_list) < 1:
return course_list
excluded_course_list = []
first_course = course_list[0] # 가장 빨리 끝나는 수업을 가져온다.
for course in course_list:
if not conflict_schedule(first_course, course):
excluded_course_list.append(course)
return [first_course] + course_selection_recursive(excluded_course_list)
def course_selection(course_list):
sorted_course_list = sorted(course_list, key=lambda x:x[1]) # 가장 빨리 끝나는 수업을 가져오기 위해 정렬하였다.
return course_selection_recursive(sorted_course_list)
# 테스트
print(course_selection([(6, 10), (2, 3), (4, 5), (1, 7), (6, 8), (9, 10)]))
print(course_selection([(1, 2), (3, 4), (0, 6), (5, 7), (8, 9), (5, 9)]))
print(course_selection([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 5), (13, 16), (9, 11), (1, 8)]))# 콘솔 출력
[(2, 3), (4, 5), (6, 8), (9, 10)]
[(1, 2), (3, 4), (5, 7), (8, 9)]
[(1, 3), (4, 7), (8, 10), (13, 16)]풀이를 기반으로 개선한 코드
def conflict_schedule(before_course, course):
# 겹치는 수업을 판별하는 함수를 풀이에서 언급한대로 작성하였다.
return before_course[1] > course[0]
def course_selection(course_list): # 재귀가 아닌 for문으로 작성
sorted_course_list = sorted(course_list, key=lambda x:x[1])
possible_course_list = [sorted_course_list[0]]
for course in sorted_course_list:
if not conflict_schedule(before_course=possible_course_list[-1], course=course):
possible_course_list.append(course)
return possible_course_list
# 테스트
print(course_selection([(6, 10), (2, 3), (4, 5), (1, 7), (6, 8), (9, 10)]))
print(course_selection([(1, 2), (3, 4), (0, 6), (5, 7), (8, 9), (5, 9)]))
print(course_selection([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 5), (13, 16), (9, 11), (1, 8)]))# 콘솔 출력
[(2, 3), (4, 5), (6, 8), (9, 10)]
[(1, 2), (3, 4), (5, 7), (8, 9)]
[(1, 3), (4, 7), (8, 10), (13, 16)]토픽 마무리
여기까지 코드잇의 알고리즘의 정석의 정리를 마무리 하고자 한다. 이 코스는 4개의 토픽으로 이루어져있으며 구성은 다음과 같다.
1. 좋은 알고리즘이란?
2. 재귀 함수
3. 알고리즘 패러다임
4. 문제 해결 능력 기르기
3번까지가 알고리즘의 기초 혹은 개념에 해당하기에 블로그에 정리해보았다. 4번은 문제풀이 위주이다. 개인 노션에만 정리하면 될 거 같다.
모든 강의가 설명이 쉽고 수업도 짧아서 부담 없이 들을 수 있었다. 또한 문제 풀이를 위한 웹IDE까지 제공해주어서 좋았다. 다만 강사분께서 직접 질문에 답변을 달아주지는 않는다.
추가로 문제 풀이마다 힌트도 하나씩 열어볼 수 있게 되어있다. 직접 강의를 수강하고 정리하기를 추천하고 싶다.
앞서 언급했듯이 이후 토픽은 문제 해결 능력 기르기로 이어지며 정리는 여기서 마치도록 하겠다.
