대규모 트래픽으로 인한 서버 과부하 해결방법에 대해 알아보자.
서버 과부하
서버가 리소스를 소진하여 들어오는 요청을 처리하지 못할 때 발생한다.
이 때 서버는 사용자의 웹요청을 처리하지 못해 응답없음이 뜨게 된다.
해결방법
모니터링을 통한 자원 할당
서버가 응답없음이 뜨는 것은 여러가지 이유가 있지만 그 중 하나가 바로 자원의 한계점 도달 이다.
보통 서버의 CPU 사용량이 80-90%에 도달하거나 메모리가 부족해 계속해서 스와핑이 발생하면 과부화 상태가 됩니다.
스와핑에 대해
가상 메모리는 존재하는데 실제 메모리인 RAM 에는 현재 없는 데이터 or 코드에 접근하는 경우
-> 페이지 폴트 발생스와핑 : 메모리에서 당장 사용하지 않는 영역을 하드디스크로 옮기고 하드디스크의 일부를 메모리처럼 불러와 쓰는 것
마치 페이지 폴트가 발생하지 않은 것처럼 만든다.
이를 모니터링을 통한 자원의 적절한 할당으로 해결할 수 있다.
자원에 속하는 것들
- CPU
- 메모리
- 대역폭
AWS 오토스케일링
AWS 오토스케일링이란 인스턴스가 있을 때 사용자가 몰리게 돼서 서비스 이용 불가능 상태 발생하기 이전에 cloud watch가 계속해서 모니터링하여 서버 대수를 늘려주는 방법입니다.
AWS Auto Scaling은 애플리케이션을 자동으로 모니터링하고 자원의 용량을 자동으로 조정한다.
netdata를 이용한 모니터링
만약 AWS를 사용하지 않는다고 했을 때 무료 모니터링 서비스도 있다.
https://github.com/netdata/netdata
이를 기반으로 지속적인 모니터링, 그리고 이를 기반으로 자원할당을 해서 해결할 수도
있다.
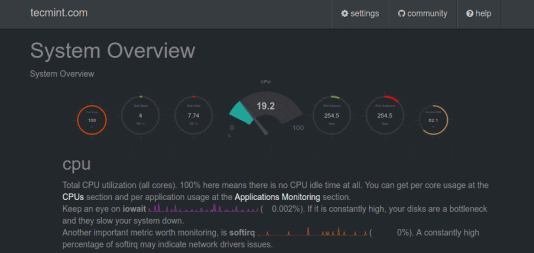
위와 같은 화면은 slack 과 연동해 임계치를 기반으로 알림 서비스 또한 구축 가능하다.
모니터링 하는 이유
모니터링을 왜 할까?
먼저 서버과부화로 인해 서버 중지에 대한 대처를 할 수 있다.
1. 어떤 페이지에 어떤트래픽이 얼마나 발생했느냐.
2. 어떤 네트워크에서 병목현상이 일어났냐.
등을 모니터링에서는 알려준다.
또한 모니터링을 하면 활용도가 낮은 페이지, 높은 페이지를 파악할 수 있어 나중에 서비스 개선에도 도움이 된다.
즉, 해결하기 위한 문제점을 파악하기 위해 모니터링은 필수
또 일부 서비스는 모니터링한 결과물을 알려주면서 서비스의 중단 등의 여부를 사용자에게 알려주기도 한다.
ex) cloudflare -> https://www.cloudflarestatus.com/
로드밸런서
앞서 설명한 AWS 오토스케일링은 빠르긴 하나 구성에 시간이 걸리기 때문에 앞단에 로드밸런서를 통해 트래픽을 분산해야 한다.
또한, 로드밸런서는 한 서버에 장애가 발생하면 로드 밸런서는 트래픽을 다른 기능 서버로 리디렉션하여 시스템 중단을 방지할 수도 있다.
블랙스완 프로토콜
블랙스완 : 예측할 수 없는 사고
중요한 것은 이러한 블랙스완은 매번 일어나기 때문에 이에 따라 대비를 해야 한다.
구글의 블랙스완이 발생 시 수칙
- 영향을 받은 시스템과 각 시스템의 상대적 위험 수준을 확인
- 체계적으로 데이터를 수집하고 원인에 대한 가설을 수립한 후 이를 테스팅
- 잠재적으로 영향을 받을 수 있는 내부의 모든 팀에 연락
- 최대한 빨리 취약점에 영향을 받는 모든 시스템을 업데이트
- 복원계획을 포함한 우리의 대응 과정을 파트너와 고객 등 외부에 전달
서킷 브레이커
서비스 장애를 감지하고 연쇄적으로 생기는 에러를 방지하는 기법
서비스와 서비스 사이에 서킷브레이커 계층을 두고 미리 설정해놓은 timeout 임계값에 도달하면 서킷브레이커가 그 이후의 추가 호출에 무조건 에러를 반환
만약 서비스 A, B, C가 있고 결제 서비스라고 했을 때 A는 개인정보, B는 장바구니, C는 미리 결정해둔 카드 정보들을 관리. 그리고 A, B, C 끼리 HTTP로 통신한다고 하자.
만약 스레드가 100개 중 98개는 A에 요청, 나머지 2개는 각각 B, C에 요청한다고 하자.
근데 A가 고장나버린다면.. 기다리는 동안 B와 C에 대해서도 스레드가 차단될 수도 있다.
이것을
스레드 차단이라고 한다.
혹은
- A <-> B
- B <-> C
가 연결돼 있는데 A가 고장나버리면 B가 멈추게 되고, 연쇄적으로 C도 멈추게 된다.
이것을
계단식 에러라고 한다.
이럴 때를 대비해서 서비스 사이에 서킷 브레이커를 두고 에러를 방지하는 것이다.
에러가 고쳐질 때까지 기다리는게 뭐가 어때서? 라고 생각한다면.
사용자 입장에서 응답을 오래 기다려야 하는 것은 좋은 UX가 아니다. 성공인지 실패인지는 중요하지 않다. 중요한 것은 사용자가 기다리지 않아야 한다는 점이다.
동작과정
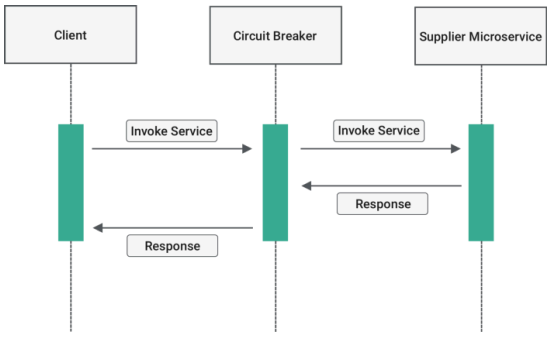
이렇게 정상적으로 작동하던 서비스가 있다고 가정했을 때
아래 사진처럼 Supplier Microservice 가 고장나게 된다면 바로 에러를 반환한다.
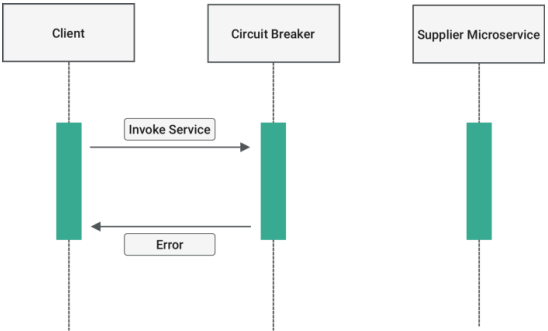
서킷브레이커는 closed, open, half_open 의 상태값을 가진다.
closed[정상] : 네트워크 요청의 실패율이 임계치보다 낮음open[에러] : 임계치이상의 상태를 말합니다. 요청을 서비스로 전송하지 않고 바로 오류를 반환합니다. 이를fail fast라고 한다.half_open[확인중] :open상태에서 일정timeout으로 설정된 시간이 지나면 장애가 해결되었는지 확인하기 위해half_open상태로 전환됩니다.
여기서 요청을 전송하여 응답을 확인.
장애가 풀리는지를 확인해서 성공하면closed, 실패하면 다시open으로 변경

장점
연속적인 에러 발생을 막아주며 일부서비스가 종료되더라도 다른 서비스들은 이상없이 동작하게 만들 수 있으며 사용자 경험을 높여준다.
이미 서킷브레이커는 구현된 라이브러리가 있는데, Netflix의 Hystrix 그리고 Resilience4j 가 대표적이다.
https://github.com/Netflix/Hystrix
https://github.com/resilience4j/resilience4j
컨텐츠 관리
불필요한 컨텐츠 제거
인프런의 장애 복구 사례를 예를 들어보자.
-> 불필요한 쿼리 등을 제거한다.
https://tech.inflab.com/202201-event-postmortem/

사용하지 않는 컬럼들도 가져온다든지 그런 것들을 제거해서 컨텐츠의 크기를 줄이거나 할 수 있다.
CDN을 통한 컨텐츠 제공
CDN을 통해 사용자 가까이, 그리고 분산된 대규모 서버 네트워크를 기반으로 컨텐츠를 제공해서 메인 서버에 대한 부하를 줄인다.
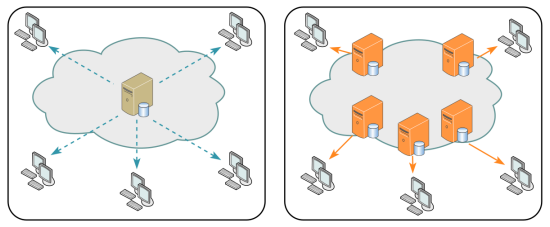
MainServer 에서 사용자가 원하면 데이터를 줄텐데 변하지 않는 Image, js, css, html 과 같은 정적 자원들은 MainServer가 주는 것이 CDN을 통해 주므로 비용을 줄일 수 있다.
ex) cpu의 10%를 해당 장적 자원들을 제공하는데 사용하고 있었다면 해당 비용을 줄일 수 있다.
컨텐츠 캐싱
네트워크 트래픽을 해결하는 가장 좋은 방법은 해당 트래픽이 발생하지 않도록 하는 것이다.
브라우저 캐시(쿠키, 로컬저장소, 세션저장소)를 통해 해당 요청에 관한 항목을 캐시에서 응답을 읽어 네트워크 요청에 관한 비용을 모두 제거한다.
컨텐츠 압축
텍스트 기반 리소스는 gzip 또는 Brotli를 통해 압축해야 한다. 압축하면 70% 정도까지 압축할 수 있습니다.
다만 압축했기 때문에 압축을 풀기위해 서버에서 자원(CPU)를 사용하는 양까지 고려해야 한다.
보통은 압축하면 좋다.
컨텐츠의 우하한 저하 (미리 준비된 응답하기)
시스템의 과도한 부하를 줄이기 위해 제공하는 컨텐츠 및 기능을 일시적으로 줄이는 전략이다.
예를 들어 정적 텍스트 페이지를 제공하거나, 검색을 비활성화하거나 더 적은 수의 검색 결과를 반환하거나, 필수적이지 않은 기능을 비활성화한다.
중요한 일이 생겼을 때 뉴스와 같은 홈페이지는 이미지, 영상, 지도와 같은 것들을 삭제하고
내용 전달에 중점을 두고 경량화된 컨텐츠를 제공한다.일본 NHK 웹의 정상 화면의 경우
서울 대피 당시 화면의 경우


