DataBase에 대해 작성하며 개념부터 차근차근 다뤄보려고 한다.
간단한 것부터 해서 SQL 관련해서까지 정리해보려고 한다.
기본 용어
- Data : 관찰의 결과로 나타난 정량적 or 정성적인 실제 값을 의미한다.
- Information : 데이터를 기반으로 하여 의미를 부여한 것이다.
Database란?
- Database : 한 조직에 필요한 정보를 여러 응용 시스템에서 공용할 수 있게 데이터를 모으고, 중복되는 데이터는 최소화해 구조적으로 통합 및 저장해둔 것이다.
Database의 정의
- 운영 데이터 (Operational Data) : 조직의 목적을 위해 사용되는 데이터
- 공용 데이터 (Shared Data) : 공동으로 사용되는 데이터
- 통합 데이터 (Integrated Data) : 중복을 최소화하여 중복으로 인한 데이터 불일치 현상 제거
-> 이후 DB 모델링에서 anomaly (이상, 변칙) 에 대해 다뤄볼 것이다. - 저장 데이터 (Stored Data) : 컴퓨터 저장 장치에 저장된 데이터
-> 영속성을 가져야 한다. (ex. 메모장, Excel 등)
Database의 특징
- 실시간 접근성 (Real Time Accessibility) : 사용자가 데이터를 요청하면 실시간으로 결과를 서비스한다.
- 계속적인 변화 (Continuous Change) : 데이터 값은 시간에 따라 항상 바뀐다.
- 동시 공유 (Concurrent Sharing) : 서로 다른 업무 또는 여러 사용자에게 동시 공유된다.
- 내용에 따른 참조 (Reference By Content) : 저장된 데이터는 데이터의 물리적 위치가 아니라 데이터 값에 따라 참조된다.
DBMS (Database Management System)
DBMS란?
DB에서 데이터를 정의, 제어, 조작, 추출 등 할 수 있게 해주는 DB 전용 관리 프로그램을 말한다.
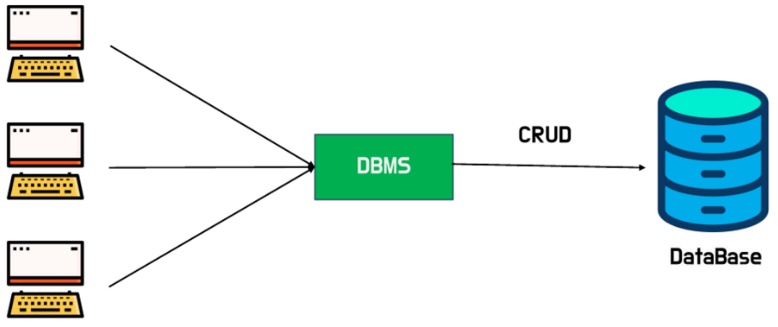
DBMS의 기능
| 주요 기능 | 내용 |
|---|---|
| 데이터 추출 (Retrieval) | 사용자가 조회하는 데이터 혹은 응용 프로그램의 데이터를 추출 (추출이라고 하지만, 복사하듯이 하는 것) |
| 데이터 조작 (Manipulation) | 데이터를 조작하는 소프트웨어(응용 프로그램)가 요청하는 데이터의 삽입, 수정, 삭제 작업을 지원 |
| 데이터 정의 (Definition) | 데이터의 구조를 정의하고 데이터 구조에 대한 삭제 및 변경 기능을 수행 |
| 데이터 제어 (Control) | 데이터베이스 사용자를 생성하고 모니터링하며 접근을 제어 백업과 회복, 동시성 제어 등의 기능을 지원 |
사용 시 이점
| 주요 이점 | 내용 |
|---|---|
| 데이터 중복 최소화 | 데이터와 응용 프로그램을 분리시킴으로써 상호 영향 정도를 줄일 수 있다. |
| 쿼리 언어 | DBMS는 SQL(Structured Query Language)과 같은 강력한 쿼리 언어를 제공하여, 복잡한 검색과 분석 작업을 손쉽게 수행할 수 있게 한다. |
| 데이터 무결성 | DBMS는 데이터의 무결성을 보장하기 위한 다양한 제약 조건과 규칙을 설정할 수 있다. 이는 데이터의 품질과 정확성을 보장한다. |
| 데이터 백업 및 복구 | DBMS는 데이터의 백업과 복구를 지원하여, 시스템 장애나 데이터 손상 시에도 데이터를 복원할 수 있다. |
| 표준화 | DBMS는 표준화된 방법을 통해 데이터를 관리하므로, 데이터의 구조와 접근 방법이 일괄적이다. 이로 인해 애플리케이션 개발 및 유지보수가 용이해 진다. |
종류 및 특징
| SQL Server | Oracle | MySQL | MariaDB | DB2 | SQLite | |
|---|---|---|---|---|---|---|
| 제조사 | MS | Oracle | Oracle | MariaDB재단 | IBM | D.Richard Hipp(오픈소스) |
| 기반 운영체제 | 윈도우 | 윈도우, 유닉스, 리눅스 | 윈도우, 유닉스, 리눅스 | 윈도우, 유닉스, 리눅스 | 유닉스 | 모바일OS (안드로이드, IOS 등) |
| 용도 | 윈도우 기반 기업용 | 대용량 데이터베이스 | 소용량 데이터베이스 | 소용량 데이터베이스 | 대용량 데이터베이스 | 모바일 전용 데이터베이스 |
DB는 여러 변천 과정을 겪었으나 이제는 RDBMS를 주로 사용한다.
RDBMS
- 관계 데이터 모델(Relational Data Model)
: 데이터를 테이블 형태로 구성(행과 열로 구성)하며, 서로 다른 테이블 간의 관계는 키를 통해 정의함. 데이터의 무결성을 유지하고 SQL을 사용하여 복잡한 쿼리와 데이터 조작을 용이하게 함
- 관계형 데이터베이스(RDBMS, Relational Database Management System)
Relational 이 번역해서 "관계형"으로 느낄 수 있겠지만, 사실 Relation 이라고 하는 데이터를 원자 값으로 갖는 이차원의 테이블의 의미를 갖는다.
💡 데이터를 테이블의 형태로 저장하며, 각 테이블은 행(레코드)과 열(필드)로 구성되어 있다. 테이블 간의 관계는 공통 필드를 통해 형성된다.
SQL(Structured Query Language)은 RDBMS에서 데이터를 조작하고 쿼리하는데 주로 사용되는 언어로 엄격한 데이터 무결성 규칙을 가지며, ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션 속성을 지원한다.
- Atomicity(원자성) : 트랜잭션과 관련된 일은 모두 실행되던지 모두 실행되지 않도록 하던지를 보장하는 특성
- Consistency(일관성) : 트랜잭션의 실행이 완료되면, 데이터베이스는 일관된 상태를 유지해야 한다. (무결성 제약조건을 만족함을 보증)
- Isolation(고립성) : 동시에 실행되는 여러 트랜잭션이 서로 영향을 주지 않도록 관리해서 동시성을 관리해야 한다.
- Durability(지속성) : 트랙잭션이 성공적으로 완료되면 시스템에 장애가 발생하더라도 영구적으로 반영되어야한다.(커밋 되면 안전하게 저장됨을 보증)
장점
- 데이터 무결성을 유지하는데 효과적이다.
- 강력한 쿼리 언어(SQL)를 통해 복잡한 데이터 조작이 가능하다.
- 데이터의 정규화를 통해 중복성을 최소화한다.
단점
- 복잡한 객체 관계를 표현하는데 한계가 있다.
- 스키마 변경이 어렵고 비용이 많이 든다.

백엔드 개발자 꿈나무