set operator, join의 차이 같은 개념은 꼭 알아야 한다.
그러기 위해 join을 알아보고 그룹함수를 많이 다루지는 않고 가볍게 알아보자.
추후에 그룹함수에 대해서도 작성할 것이다.
JOIN은 2개 이상의 테이블을 공통 속성을 묶어서 하나의 테이블로 나타낼 때 사용할 수 있다.
이전에 나왔던 AS (별칭) 을 활용해서 2개의 테이블을 간단하게 나타내면서 해볼 것이다.
INNER JOIN (== JOIN)
Mapping 되는 것들만 묶어줄 때 사용하는 내부 조인이다.
SELECT
category_name
, menu_name
FROM tbl_menu a
INNER JOIN tbl_category b
ON a.category_code = b.category_code;
간단하게 tbl_menu를 a라는 별칭, tbl_category를 b라는 별칭으로 나타낸다.
ON 절
위에서 쓰인 on절은 조건이 만족하지 않으면 (true가 아니면) 조인을 하지 않는다.
즉, a.category_code = b.category_code가 만족하지 않으면 조인이 안 된다.
(같은 카테고리 코드가 없으면 안 한다는 뜻)
그리고 조건에 만족하면 그에 맞춰서 JOIN을 해준다.
그래서 카테고리 코드를 맞춰서 조인했기 때문에 메뉴마다 하나의 카테고리 이름으로 연결지어진 것이다.
SELECT 에 특정한 것이 아닌 전체를 조회한다면?
SELECT
*
FROM tbl_menu a
INNER JOIN tbl_category b
ON a.category_code = b.category_code;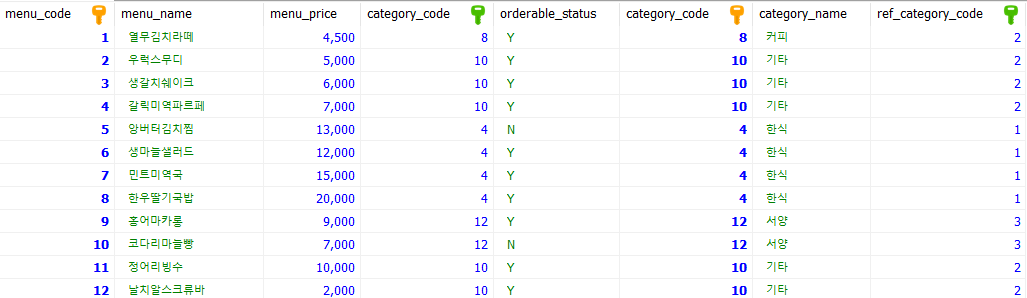
join은 그냥 menu 테이블에 category 테이블을 이어붙여준 것이다.
위에서는 category_name, menu_name 만 조회했기 때문에 간단하게 나왔던 것이다.
사진에서처럼 category_code가 2개가 보이게 되는데, 둘은 같은 속성이기 때문에 2개가 보일 이유가 없다.
별칭을 활용해서 하나만 조회하면 된다.
USING
on과 관련있지만 권장되지는 않는 using 방식도 있다.
SELECT
b.category_name
, a.menu_name
, a.category_code
FROM tbl_menu a
INNER JOIN tbl_category b USING (category_code);이렇게 해도 category_code만 컬럼이 추가됐을 뿐 결과 자체는 다르지 않다.
권장되지 않는 이유는 join할 테이블들의 mapping column 명이 동일할 때만 사용 가능한 문법이기 때문이다.
OUTER JOIN
조건에 부합하지 않는 행도 포함시켜 결합하는 것
기본적으로 LEFT, RIGHT or FULL이 OUTER JOIN이다.
FULL JOIN 은 사용할 일이 거의 없으며, ODBC에 따라 지원하지 않는 경우도 있다.
LEFT JOIN
왼쪽 테이블을 중심으로 오른쪽의 테이블을 매치시킨다.
왼쪽 테이블을 무조건 표시하고, 매치되는 레코드가 오른쪽에 없으면 NULL을 표시한다.
SELECT
a.category_name
, b.menu_name
FROM tbl_category a
LEFT JOIN tbl_menu b ON (a.category_code = b.category_code);
RIGHT JOIN
LEFT JOIN과의 반대로 오른쪽 중심이다.
코드도 순서를 바꿔서 실행해보았는데 컬럼의 순서만 바뀌고 똑같이 나온다.
SELECT
a.menu_name
, b.category_name
FROM tbl_menu a
RIGHT JOIN tbl_category b ON (a.category_code = b.category_code);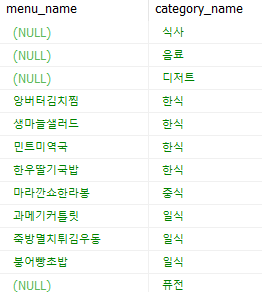
다음은 모든 경우를 나타내주는 CROSS JOIN, 내 테이블이 나를 참조해서 결합하는 SELF JOIN에 대해 알아보자.
CROSS JOIN
그냥 유의미한 코드는 아니지만 CROSS JOIN을 나타내기 위한 코드이다.
단순하게 모든 경우를 나타내준다.
SELECT
a.menu_name
, b.category_name
FROM tbl_menu a
CROSS JOIN tbl_category b;모든 경우의 수로 곱해져서 총 252개 row가 조회됐다.

SELF JOIN
SELECT
a.category_name
, b.category_name
FROM tbl_category a
JOIN tbl_category b ON (a.ref_category_code = b.category_code)결과는 아래 사진처럼 나온다.
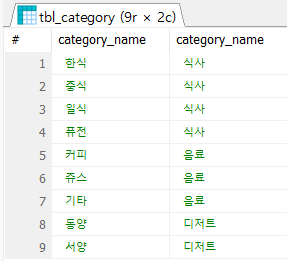
마치 a가 하위 카테고리, b가 상위 카테고리처럼 나오게 되는데
그 이유는
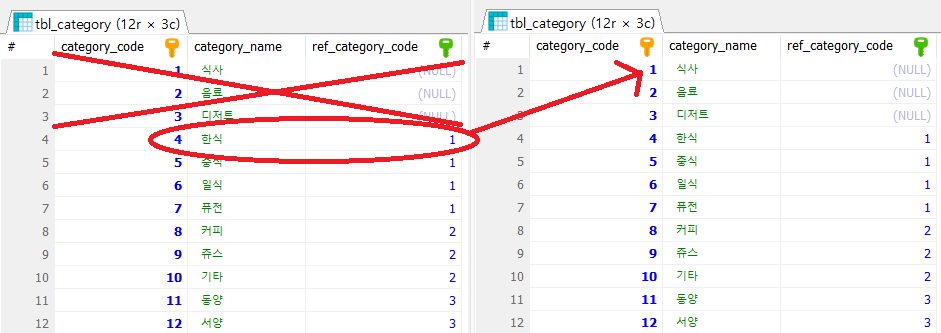
a의 ref_category_code 가 null 때문에 b의 category_code와 매치되지 않다가, 4번째 row와 1번째 row가 매치되기 시작하기 때문이다.
그룹 함수 (SUM, AVG, COUNT) 를 적용하기 위해서 GROUP BY를 사용한다.
컬럼에 있는 값을 이용해서 그룹을 만드는데 DISTINCT와 유사해보이긴 한다.
GROUP BY
COUNT (개수 세는 함수)
SELECT
COUNT(*)
FROM tbl_menu a
GROUP BY a.category_code;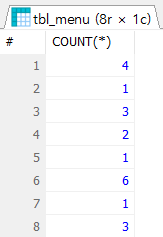
좀 더 추가하면? (concat 문자열 붙이는걸 사용해보았다.)
SELECT
COUNT(*)
, CONCAT(a.category_code, '번 카테고리') AS '카테고리 번호'
FROM tbl_menu a
GROUP BY a.category_code;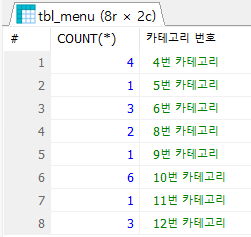
- GROUP BY 한 컬럼말고 다른 컬럼은 조회하지 않아야 한다.
(MariaDB는 조회가 되지만 다른 곳은 오류가 난다.)
COUNT메소드는 아래와 같이 사용해야 한다.
1. count(컬럼명 or *) 2. count(컬럼명) 또는 해당 컬럼에 null이 아닌 행의 개수 3. count(*) 모든 행의 개수
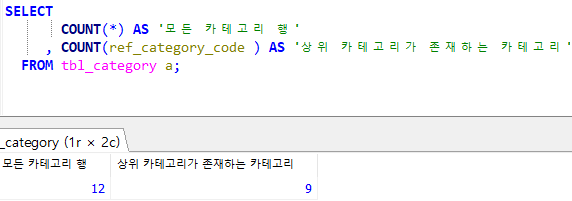
사진에서처럼 null 값이 3개가 있어서 상위 카테고리가 존재하는 카테고리는 3개 더 적다.
SUM 함수
SELECT
category_code
, SUM(menu_price)
FROM tbl_menu
GROUP BY category_code;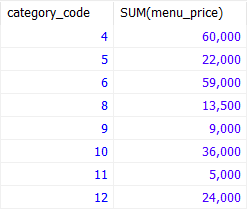
category_code 로 그룹을 묶으면서 select로 카테고리 코드를 조회하고 그 때의 sum 함수를 활용해서 메뉴 가격을 합산해보았다.
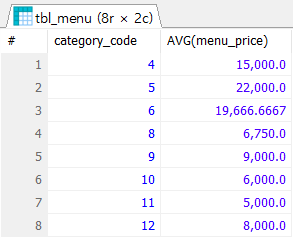
AVG 함수
SELECT
category_code
, AVG(menu_price)
FROM tbl_menu
GROUP BY category_code;위의 코드로 sum이 아니라 평균을 구해보았다.
궁금증 해결
어제 SQL에서 SELECT 7 / 3; 을 해보았는데, 2.333333... 이 아닌, 2.3333 딱 소수점 4자리까지만 나왔다. 5번째 자리에서 반올림을 하는 것이었어서 5번째 자리는 0이기 때문에
SELECT 7 / 3;
WHERE 7 / 3 = 2.33333;해도 나오지 않는다.
SELECT 7 / 3;= '2.33330' 으로 조회가 된다.
그래서 위에서 평균에서도 소수 4번째 자리는 반올림에 의해 7이 나오게 된다.
HAVING 절
GROUP BY 절 속에서의 조건문이라고 생각하면 편하다.
그룹 별로 조건이 가능하다.
where : 한 행씩 조건 (ex.직원 별로 조건)
group by : 그룹별로 조건 (ex.부서 별로 조건)
SELECT
SUM(menu_price)
, category_code
FROM tbl_menu
GROUP BY category_code
HAVING category_code BETWEEN 5 AND 9;그룹화한 category_code 가 5~9인 것들 중 메뉴 합산이 sum인 것들을 조회할 수 있다.
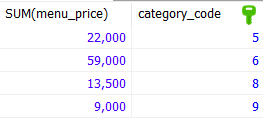
이 때는 where절을 사용해도 나온다. 그룹 함수를 사용하지 않기 때문이다.
그럼 아래는 어떻게 나올까?
SELECT
SUM(menu_price)
, category_code
FROM tbl_menu
GROUP BY category_code
HAVING SUM(menu_price >= 20000);SUM(menu_price >= 20000); 인 그룹을 가져오게 될 것이다.
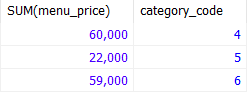
이 때는 그룹함수 중 하나인 SUM을 사용하기 때문에 where 절로 나타내면 안 된다.
Rollup
그룹을 묶을 때 하나의 기준 (하나의 컬럼)으로 그룹화하여 Rollup을 하면 총 합계의 개념이 나오게 된다.
SELECT
SUM(menu_price)
, category_code
FROM tbl_menu
GROUP BY category_code
WITH ROLLUP;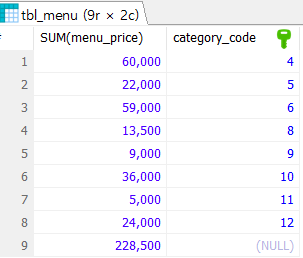
여러 개의 기준도 가능하다.
컬럼을 2개 이상 써보자.
SELECT
SUM(menu_price)
, menu_price
, category_code
FROM tbl_menu
GROUP BY menu_price, category_code
WITH ROLLUP;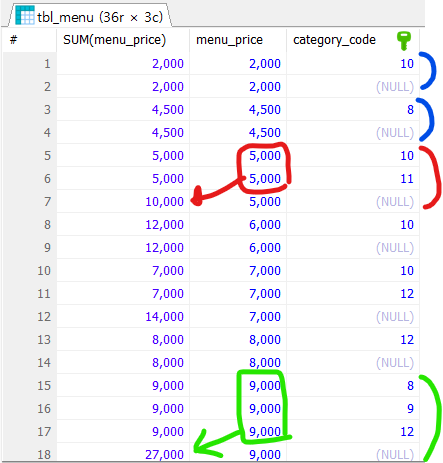
이렇게 메뉴 가격과 카테고리 코드로 그룹화하면 위 사진처럼 중간 합계가 이어지다가

마지막에 최종 합계가 따로 또 나온다. (중간에 생략돼있다.)
다음은 서브쿼리에 대해 다뤄보려고 한다.
서브쿼리
간단하게 시작해보자.
선행해서 쿼리에서 동작해야 할 쿼리를 서브쿼리로 작성한다.
내가 '민트미역국' (우웩) 이라고 하는 메뉴가 들어가는 카테고리 번호를 조회하고 싶다면
SELECT
category_code
FROM tbl_menu
WHERE menu_name LIKE '%민트미역국%';으로 구할 수 있다.
위의 결과는 category_code = 4 의 데이터를 조회할 수 있다.
그걸 이제 다르게 '민트 미역국'과 같은 카테고리의 메뉴를 조회를 하고 싶다면
-> 서브쿼리가 필요하다.
SELECT
menu_name
FROM tbl_menu
WHERE category_code = (SELECT category_code
FROM tbl_menu
WHERE menu_name LIKE '%민트미역국%'
);메인 쿼리 안에 서브 쿼리를 넣어서 category_code = 4라는 것을 where 절로 보낼 수 있다.
서브쿼리는 어느 절이든 들어갈 수 있다.
from 절에 들어가는건 '인라인 뷰'라는 이름으로 부른다.
MariaDB 에서는 서브쿼리를 from절에 사용 시(인라인 뷰) 반드시 별칭이 필요하다.
서브쿼리의 그룹함수의 결과를 메인 쿼리에서 쓰기 위해서는 반드시 별칭을 달아야 한다.
-- 다중행 다중열 서브쿼리
SELECT
*
FROM tbl_menu;
-- 다중행 단일열 서브쿼리
SELECT
menu_name
FROM tbl_menu;
-- 단일행 다중열 서브쿼리
SELECT
*
FROM tbl_menu
WHERE menu_name = '우럭스무디';
-- 단일행 단일열 서브쿼리
SELECT
category_code
FROM tbl_menu
WHERE menu_name = '우럭스무디';상관 서브쿼리
메인 쿼리를 활용한 서브쿼리라면 상관(메인쿼리와 서브쿼리의 상관관계 활용) 서브쿼리 라고 한다.
메뉴가 존재하는 카테고리 별로 평균을 구하기 위해서는
SELECT
AVG(menu_price)
FROM tbl_menu
WHERE category_code = 4;위와 같은 코드로 category_code 에 따라 4, 5, 6 ... 계속 바꿔줘야 하는 번거로움이 있다.
상관 서브쿼리를 활용해서 "메뉴별 각 메뉴가 속한 카테고리의 평균보다 높은 가격의 메뉴들만 조회"를 해보자.
SELECT
a.menu_code
, a.menu_name
, a.menu_price
, a.category_code
, a.orderable_status
FROM tbl_menu a
WHERE a.menu_price > (SELECT AVG(b.menu_price)
FROM tbl_menu b
WHERE b.category_code = a.category_code
);Where 절에서 하나의 메뉴에는 상위 개념으로 category_code가 있기 때문에 category_code 별로 가격 평균을 구하고 그것보다 가격이 높은 메뉴들을 조회할 수 있다.
EXISTS
서브쿼리의 결과를 체크해주는 키워드이다. (절 아님)
서브쿼리의 결과가 한 행이라도 조회된다면 -> true
되지 않는다면 -> false
"카테고리 중에 메뉴에 부여된 카테고리들의 카테고리 이름 조회 후 오름차순 정렬"을 해보자
SELECT
category_name
FROM tbl_category a
WHERE EXISTS (SELECT menu_code
FROM tbl_menu b
WHERE b.category_code = a.category_code)
ORDER BY 1;파생 테이블과 비슷한 개념이며 코드의 가독성과 재사용성을 위해 파생 테이블 대신 사용하게 된다.)
