
나는 이번에 프로젝트를 하면서 새로운 기술을 접해보자는 생각으로 시작했다.
헬스 입문자들을 위한 웹사이트를 만들어보았다. 아키텍처는 아래와 같다.
헬스장 입문자들은 일일이 본인의 기록을 인바디를 통해 같은 번호로 인바디를 재서 그 때 비교하는 것말고는 크게는 안 할 것 같다.
그래서 내가 생각한 것이 OCR API를 통해 데이터를 반환받아 저장해두면서 본인의 변화추이를 확인하는 것도 좋고, 그것을 활용해서 라이벌과의 비교라든지 좀 더 확장성이 좋다고 생각하였고 그래서 OCR 찾아본 것이 Google Cloud Vision API 였다.
Google Cloud Vision API 와 Google Storage로 직접 적용을 했다.
Kakao도 Vision API가 있었던 걸로 생각했는데 없어진지 좀 됐다고 한다.
Google Cloud Vision 플랫폼 설정하기
- Google Cloud을 검색하고 콘솔 창으로 이동
- API 및 서비스 -> 사용자 인증 정보
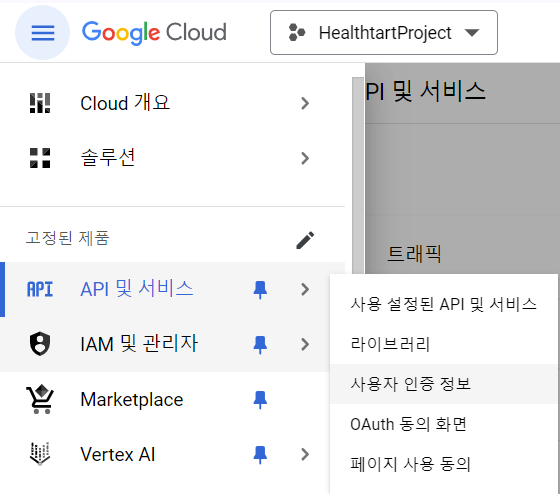
- 사용자 인증 정보 화면에서
사용자 인증 정보 만들기->API 키클릭
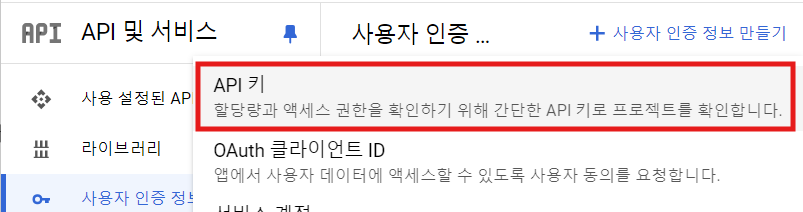
즉시 생성이 되는데 이후에는 API를 활성화해줘야 한다.
- API 및 서비스 ->
사용 설정된 API 및 서비스클릭 - 중앙 상단의 검색창에
Cloud Vision API검색하여 사용 버튼을 누르면 된다.

- IAM 및 관리자 -> 서비스 계정 클릭
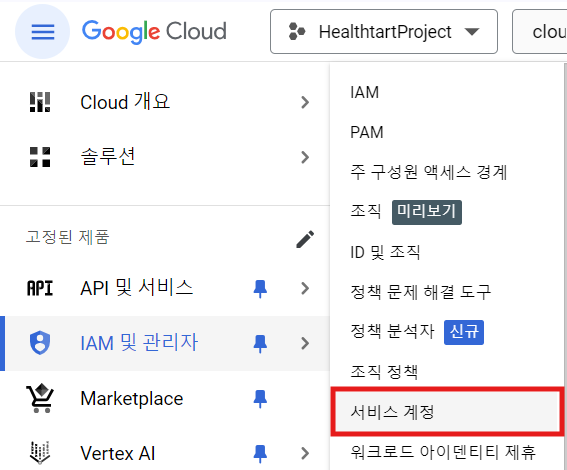
- 서비스 계정에 관한 이름이나 정보들을 입력한 뒤 2단계에서 액세스 권한은
- 소유자
- 저장소 관리자
- 저장소 개체 관리자
- Vision AI 관리자
4가지 역할을 선택하였다. (좀 더 찾아보니 일부 누락이 돼도 크게 문제는 되지 않는다고 한다.)
-
만든 계정의 키 관리 버튼 클릭
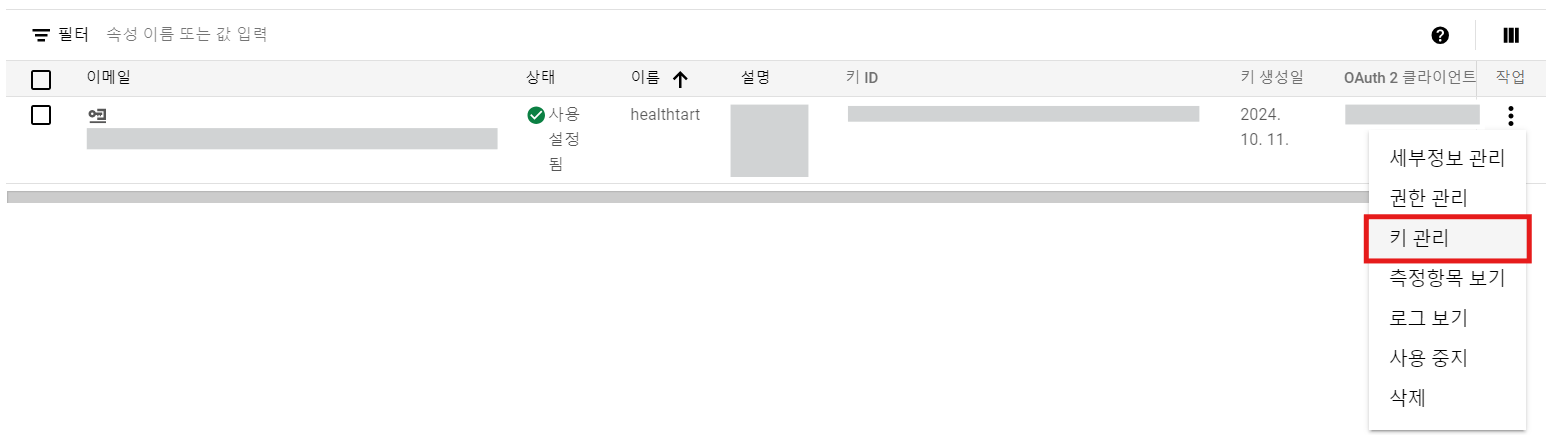
-
새 키 만들기버튼 눌러서 JSON 파일 다운로드 받기 (필수)이걸 누르면 JSON 파일을 다운로드 하는데 꼭 경로를 기억해두자.
스프링부트 설정
이건 IntelliJ 하는 설정이다.
오른쪽 위에 Run 왼쪽의 애플리케이션으로 돼 있는 부분을 누르면 Edit Configurations... 이 있다.
누른 뒤 Modify Options -> Environment variables 클릭
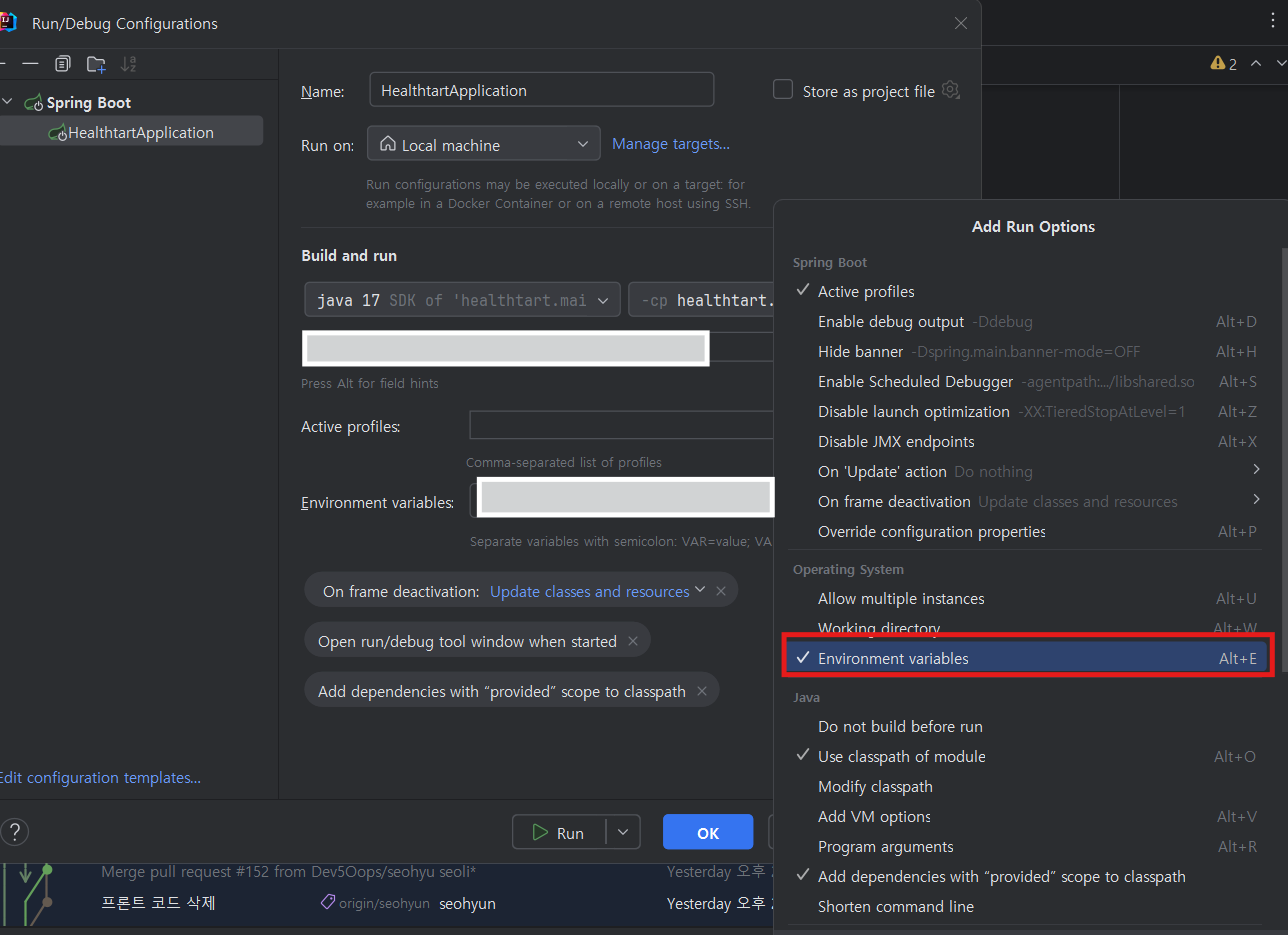
지금 나는 이미 세팅이 돼 있어서 그렇지 처음 한다면 Environment variables 가 생길 것이다.
환경변수에 아래와 같이 입력한다.
핵심은 다운로드 받은 JSON 파일의 경로를 입력하는 것이다.
GOOGLE_APPLICATION_CREDENTIALS=JSON 파일의 경로(상대 경로도 가능)
나는 프로젝트에서 src 패키지와 같은 위치에 JSON 파일을 넣고 경로를 지정해줬었다.
의존성 추가하기
build.gradle
dependencies {
// Google Cloud Vision API 클라이언트 라이브러리
implementation 'com.google.cloud:google-cloud-vision:3.34.0'
...
}컨트롤러와 서비스 코드
- OCRController
- VisionService
- FileUploadController (내가 추가한 코드)
우선 내가 프로젝트에서 한 흐름은 이렇다.
1. 사진을 업로드를 하면 FileUploadController 에서 Google Storage에 올리는 API 요청
2. 이어서 OCR 컨트롤러에서 해당 올라온 이미지 파일을 텍스트 형태로 받기
3. 그것을 Parser를 통해 원하는 데이터만 추려서 JSON 형태로 반환하기
그래서 위 3가지 코드가 필요한 것이다.
근데 일단은 기반이 된 코드들을 보여주려고 한다. 당장은 postman과 같은 곳에서 api 호출을 해서 반환이 어떻게 되는지 보는 것이 중요하다고 생각한다.
내가 만든 코드는 맨 마지막에 추가해두겠다.
VisionService
import com.google.cloud.vision.v1.AnnotateImageRequest;
import com.google.cloud.vision.v1.AnnotateImageResponse;
import com.google.cloud.vision.v1.BatchAnnotateImagesResponse;
import com.google.cloud.vision.v1.Feature;
import com.google.cloud.vision.v1.Image;
import com.google.cloud.vision.v1.ImageAnnotatorClient;
import com.google.protobuf.ByteString;
import org.springframework.stereotype.Service;
import java.io.InputStream;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
@Service
public class VisionService {
public String extractTextFromImageUrl(String imageUrl) throws Exception {
URL url = new URL(imageUrl);
ByteString imgBytes;
try (InputStream in = url.openStream()) {
imgBytes = ByteString.readFrom(in);
}
Image img = Image.newBuilder().setContent(imgBytes).build();
Feature feat = Feature.newBuilder().setType(Feature.Type.TEXT_DETECTION).build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder()
.addFeatures(feat)
.setImage(img)
.build();
List<AnnotateImageRequest> requests = new ArrayList<>();
requests.add(request);
try (ImageAnnotatorClient client = ImageAnnotatorClient.create()) {
BatchAnnotateImagesResponse response = client.batchAnnotateImages(requests);
StringBuilder stringBuilder = new StringBuilder();
for (AnnotateImageResponse res : response.getResponsesList()) {
if (res.hasError()) {
System.out.printf("Error: %s\n", res.getError().getMessage());
return "Error detected";
}
stringBuilder.append(res.getFullTextAnnotation().getText());
}
return stringBuilder.toString();
}
}
}- OCRController
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class OCRController {
@Autowired
private VisionService visionService;
@GetMapping("/extract-text")
public String extractText(@RequestParam("imageUrl") String imageUrl) {
try {
return visionService.extractTextFromImageUrl(imageUrl);
} catch (Exception e) {
//e.printStackTrace();
return "Failed to extract text: " + e.getMessage();
}
}
}Postman 으로 테스트하기 위한 방법
http://localhost:8080/extract-text?imageUrl={웹상의_이미지_URL_경로}
웹에 올라와 있는 아무 사진으로 검색하면 확인할 수 있을 것이다.
Google Storage 버킷 만들고 적용해보기
이제 Google Storage를 만들어보자. (처음 만들면 어느 정도까지는 가격을 아낄 수 있다.)
진짜 쉽다. Cloud Storage도 메뉴에 있을 것이다.
Vision API를 사용하기로 한 계정에서 Cloud Storage로 가서 프로젝트를 만들고
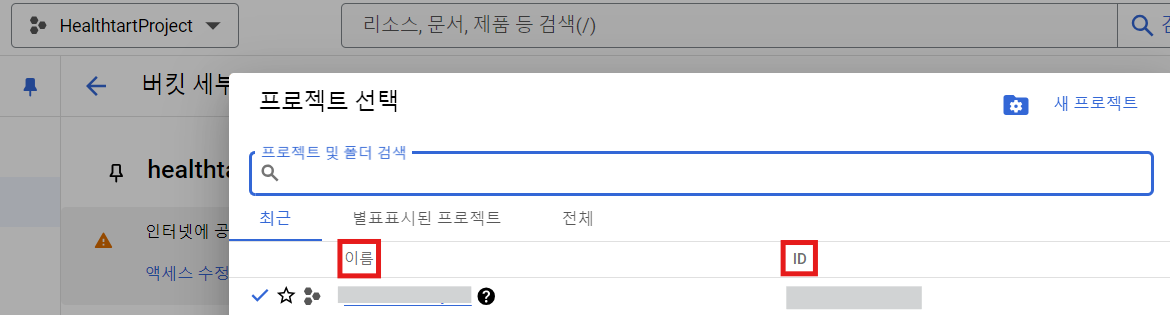
프로젝트 선택 화면을 듸우면 위 사진처럼 Project 이름와 ID를 확인할 수 있을 것이다.
다음으로 해당 프로젝트로 가서 버킷을 만들어보자.
버킷 이름 요구사항
위 링크를 이용해서 간단하게 버킷 이름을 정해주고
-
데이터 저장 위치는
region->asia-northeast3(서울) -
데이터의 스토리지 클래스 :
기본 클래스 설정->Standard -
공개 액세스 관리
-
스토리지에 있는 것들을 공개하고 싶지 않으면
- 공개 액세스 방지 적용
- 균일한 액세스 제어
-
상관없으면 아무 것도 체크하지 않고 넘어가면 된다.
-
내가 적용한 코드들 (활용)
이제 Storage에 버킷까지 만들었고, 위에서 말한 application.yml에 내용을 추가해보자.
application.yml
cloud:
gcp:
project-id: "내 프로젝트 아이디"
bucket-name: "버킷 이름"아까 사진에 있었던 프로젝트 이름과 만들었던 버킷 이름을 추가해줘야 한다.
- VisionService
import com.google.cloud.vision.v1.*;
import com.google.cloud.storage.Blob;
import com.google.cloud.storage.Storage;
import com.google.cloud.storage.StorageOptions;
import com.google.protobuf.ByteString;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Service("visionService")
public class VisionService {
@Value("${cloud.gcp.bucket-name}")
private String bucketName;
public String extractTextFromGCSImage(String fileName) throws IOException {
Storage storage = StorageOptions.getDefaultInstance().getService();
Blob blob = storage.get(bucketName, fileName);
ByteString imgBytes = ByteString.copyFrom(blob.getContent());
Image img = Image.newBuilder().setContent(imgBytes).build();
Feature feat = Feature.newBuilder().setType(Feature.Type.TEXT_DETECTION).build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder()
.addFeatures(feat)
.setImage(img)
.build();
List<AnnotateImageRequest> requests = new ArrayList<>();
requests.add(request);
try (ImageAnnotatorClient client = ImageAnnotatorClient.create()) {
BatchAnnotateImagesResponse response = client.batchAnnotateImages(requests);
StringBuilder stringBuilder = new StringBuilder();
for (AnnotateImageResponse res : response.getResponsesList()) {
if (res.hasError()) {
System.out.printf("Error: %s\n", res.getError().getMessage());
return "Error detected";
}
stringBuilder.append(res.getFullTextAnnotation().getText());
}
return InbodyDataExtractor.extractInbodyDataFromLines(stringBuilder.toString().split("\n"));
}
}
}@Value("${cloud.gcp.bucket-name}") 은 이후에 구글 스토리지에서 버킷을 만들게 되는데 그것을 application.yml 에 적용한 뒤 불러온 것이다.
InbodyDataExtractor는 내가 Inbody 사진을 스캔해서 올렸을 때 데이터 파서를 하기 위해서 넣어둔 것이다.
- OCRController
import com.dev5ops.healthtart.inbody.service.VisionService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/ocr")
public class OCRController {
@Autowired
private VisionService visionService;
@GetMapping("/extract-text")
public String extractText(@RequestParam("fileName") String fileName) {
try {
return visionService.extractTextFromGCSImage(fileName);
} catch (Exception e) {
return "Failed to extract text: " + e.getMessage();
}
}
}- FileUploadController
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import com.google.cloud.storage.*;
import java.io.IOException;
import java.net.URL;
import java.util.UUID;
@RestController
@RequestMapping("/upload")
public class FileUploadController {
@Value("${cloud.gcp.bucket-name}")
private String bucketName;
@Value("${cloud.gcp.project-id}")
private String projectId;
@PostMapping("/image")
public String uploadImageToGCS(@RequestParam("file") MultipartFile file) {
try {
String fileName = UUID.randomUUID() + "-" + file.getOriginalFilename();
Storage storage = StorageOptions.newBuilder().setProjectId(projectId).build().getService();
BlobId blobId = BlobId.of(bucketName, fileName);
BlobInfo blobInfo = BlobInfo.newBuilder(blobId).setContentType(file.getContentType()).build();
storage.create(blobInfo, file.getBytes());
URL imageUrl = new URL("https://storage.googleapis.com/" + bucketName + "/" + fileName);
return imageUrl.toString();
} catch (IOException e) {
e.printStackTrace();
return "Failed to upload image: " + e.getMessage();
}
}
}위와 같은 코드에서 이제 Parser 내용은 제외했지만, Inbody 770 데이터를 스캔한 것을 가지고 했을 때 원하는 값을 나올 수 있도록 최선을 다 해서 구현을 했었다.
결과
- 이미지 파일 업로드
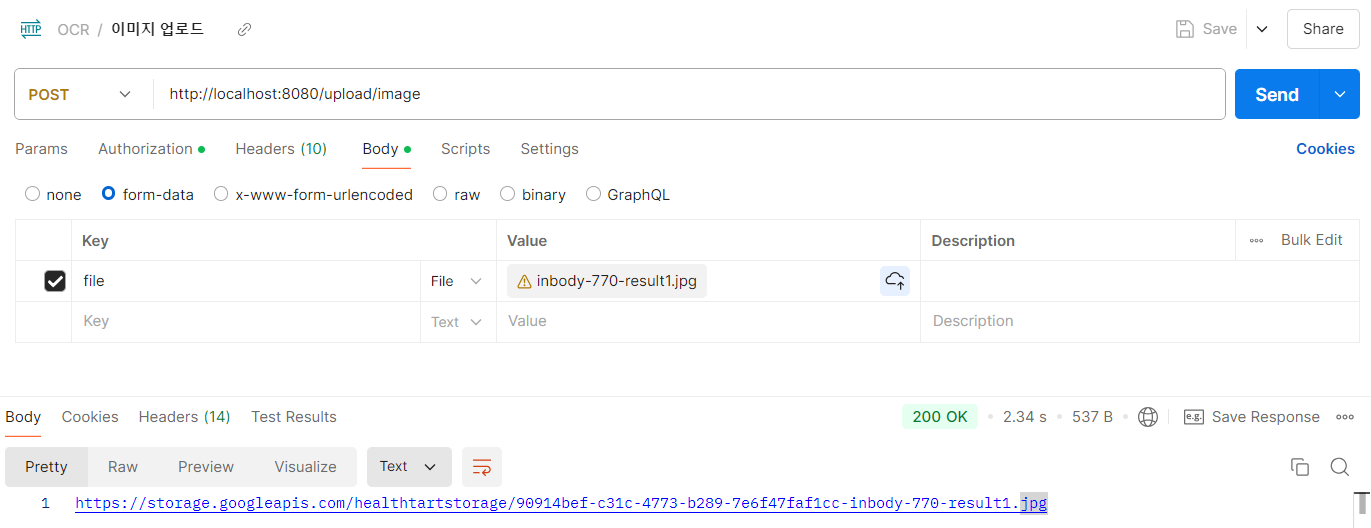
위의 요청을 실행하면 구글 스토리지에 저장된다.
- OCR 기능 사용해서 응답된 내용 보기
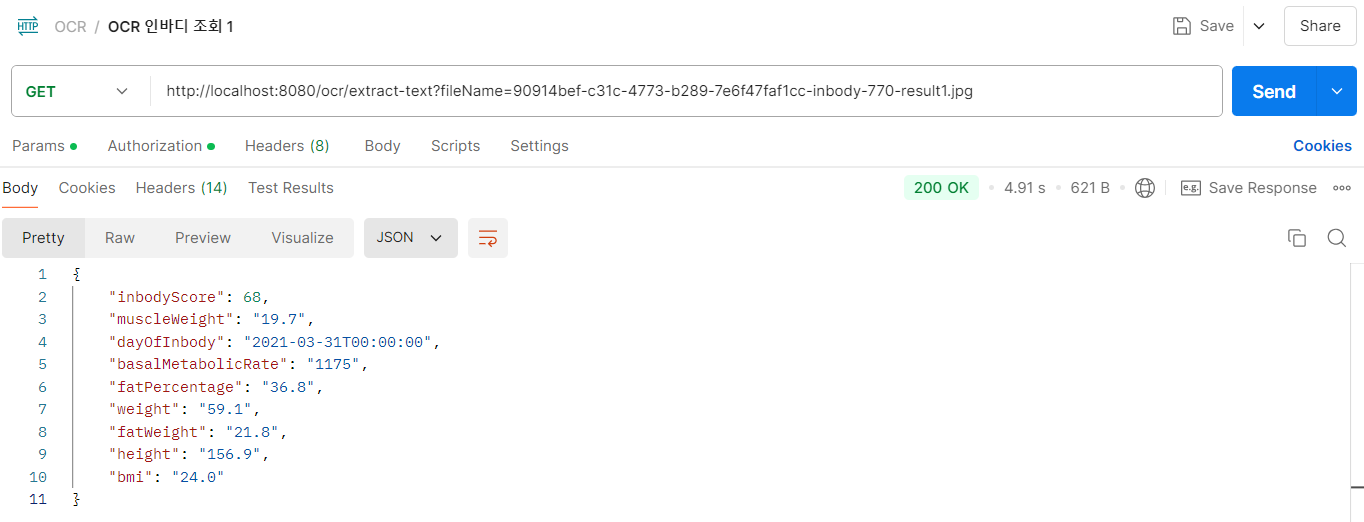
찾아본 내용 중에서는 x, y 좌표를 이용해 원하는 데이터를 찾는 것도 가능하다고 한다.
{
"description": "Example text",
"boundingPoly": {
"vertices": [
{"x": 100, "y": 200},
{"x": 400, "y": 200},
{"x": 400, "y": 300},
{"x": 100, "y": 300}
]
}
}이런 형태로 말이다.. 이것을 활용해서 직접 정규표현식으로 패턴을 찾아서 Parser 하는 방식이 아닌 x,y 좌표를 통해서도 원하는 데이터를 뽑아내면 낼 수 있을 것이라는 생각을 했다.
직접 찾아보고 적용하려는 사람들에게 내 정보 공유가 도움이 되었으면 한다.

우와 나중에 OCR 적용하게 되면 꼭 참고해봐야겠어요 !! ^^