이번에 Gemini diffusion이 출시가 되었기에 쉬는 시간에 discrete diffusion을 소개하기 위해서 글을 작성해본다.
소개

링크
gemini diffusion이 출시되었다.
최근 discrete diffusion을 이용한 text generation을 관심있게 보고있는 중인데
드디어 google에서도 이를 출시한건 좋은 소식인 것 같다.
기존에서는 Inception Labs라는 곳에서 Mercury coder가 discrete diffusion 기반 model로 엄청나게 빠른 속도를 보여주었는데
AR model은 1개의 token을 로 예측하기 때문에 1개의 token씩 예측한다.
but discrete diffusion은 whole sequence를 parallel하게 생성하기 떄문에 기본적인 구조에서 비교도 할 수 없이 빠르다.
실제로 Mercury coder에서도 5배에서 10배정도 빠른 속도를 보여주었다.
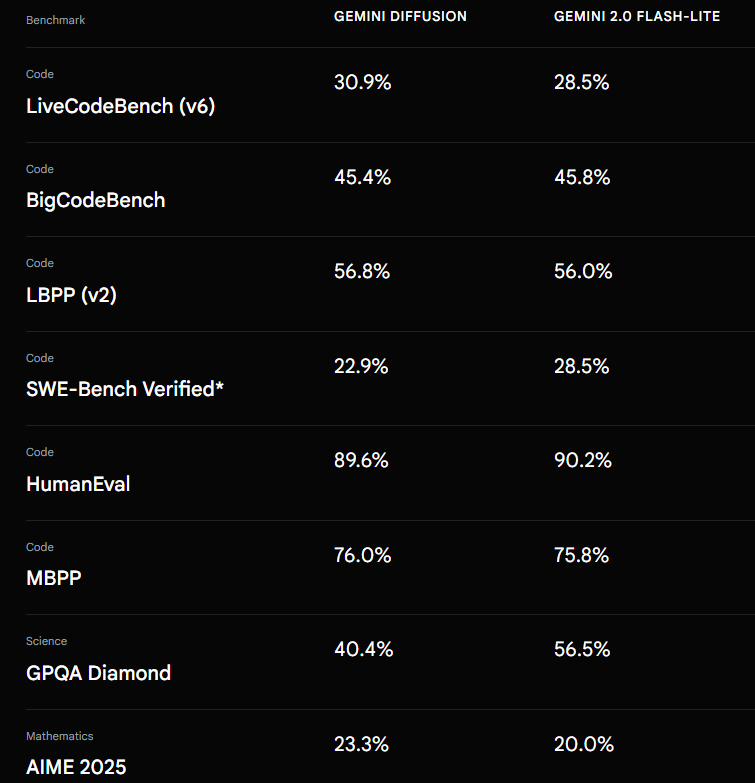
성능은 아래와 같은데 더욱 큰 AR model과 비슷한 성능을 보여준다고 한다.
추가로 discrete diffusion은 noise를 활용하는 종류가 여러개인데
- Absorb: [MASK] token을 가지고 원본을 예측
- uniform: 임의의 token으로 랜덤하게 바뀐 것을 가지고 원본을 예측
gemini는 기존의 text를 바꿔서 refinement를 할 수 있다고 하는데 이런 측면에서는 uniform이 사용된 것으로 추측한다.
absorb는 한번 open한 token을 바꿀 수 없는 것이 원칙이기 때문.
하지만 Remasking Discrete Diffusion Models with Inference-Time Scaling논문에서 absorb noise를 사용하는 discrete diffusion model을 다시 masking하게 구성하는 내용을 다루기도 했어서 이를 적용했을 수도 있다.
Discrete diffusion은 AR에 비해서 안좋을까?
discrete diffusion을 위와 같이 매우 빠르다고 이야기를 하면 대부분 드는 생각이 위와 같이 1개의 token씩 공을 들여서 생성하는 AR model에 비해서 안좋지 않을까? 라고 생각할 수 있다.
그러나 이는 틀렸다.
Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning
라는 논문에서 이에 대해서 다루었는데
AR model은 Autoregressive like data를 학습하는데 특화가 되어있다.
그러니까 data가 로 이전의 context를 토대로 다음 context를 명확하게 예측할 수 있는 것에는 잘 풀지만 만약 그렇지 못한다면 큰 문제가 된다.
그런데 이전 context로 다음 context를 예측할 수 없는 문제가 있을까?
있다!
예를 들어서
"a,b,c,d,e,f,g,h,i,j,k의 11개의 random한 숫자를 생성하고 이때 중간인 f는 항상 11개의 숫자 중 middle 값을 가지게 생성하라."
위와 같이 준다면 f를 생성하는 도중에는 뒷부분에 대한 정보가 전혀 없기 때문에 현재 생성하는 f가 middle 값인지 아닌지 알기 어렵다.
그렇기에 문제가 더욱 어렵게 된다.
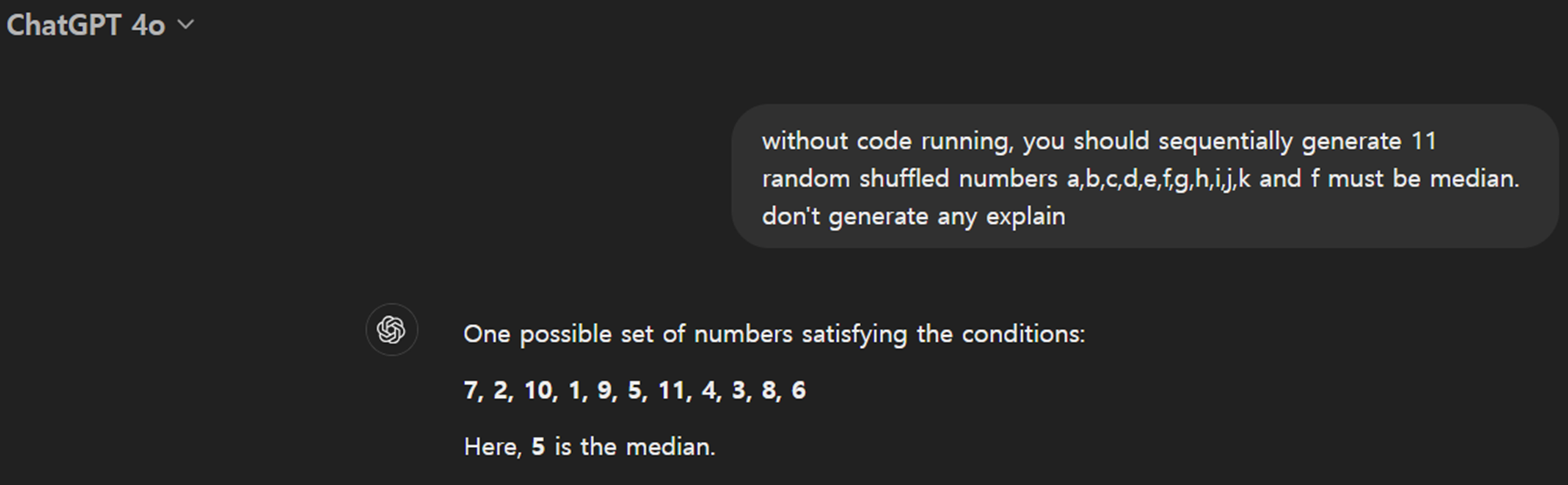 실제로 gpt4o의 경우 중간 값이 5라고 하는데
실제로 gpt4o의 경우 중간 값이 5라고 하는데
실제로 중간 값은 1,2,3,4,5,6,7,8,9,10,11으로 6이다.
그러나 이러한 문제는 reasoning model의 경우 1차로 전부 생성한 다음 이를 고치는 중간 reasoning step이 들어갈 수 있기 때문에 쉽게 풀 수 있을 것으로 생각한다.
하지만 전체 sequence를 parallel하게 생성하는 discrete diffusion model은 전체 sequence를 끈끈하게 생성하기 떄문에 절대 틀릴 수 없고 오히려 매우 쉬운 문제가 된다.
즉, AR model은 알지 못하는 뒷부분의 정보를 활용할 수 있기 때문이다.
어떻게 보면 Autoregressive model은 discrete diffusion의 specific한 경우라고 볼 수 있다.
그렇지만 아직 discrete diffusion은 성능이 그렇게 뛰어나지 못하다.
하지만 discrete diffusion은 일반적으로 AR model에 비해서 성능이 뛰어나지 못하다.
이는 학습의 불안정성, parallel generation 과정에서의 multi modal error 등 다양한 요인이 있겠지만
내가 생각하는 근본적인 원인은
"학습의 어려움" 이라고 생각한다.
Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions 논문에서 언급한 내용을 예를 들자면
Autoregressive model은 기저에 inductive bias로 이전의 context에서 다음의 token을 맞출 수 있다고 생각하고 있고 실제로 그렇게 학습한다.
결국 AR model은 학습 과정에서 previous token만 활용해서 다음 token을 predict하게 학습하는데
이때 discrete diffusion은 특정 부분을 random하게 [MASK]처리하고 이를 복구하게 학습한다. 그리고 이를 위해서는 가능한 모든 masking 경우의 수를 고려해야 한다.
결국 학습의 복잡성이 exponential하게 증가하는데 deeplearning 과정에서 학습 target이 너무 복잡해지면 성능이 떨어지는 것은 당연하다.
또한 실제로 text는 대부분 left to right로 작성된, AR format을 따르기 때문에 AR model이 학습하기 매우 편하다.
결론
결국 discrete diffusion은 특정 부분에서는 AR model을 outperform 하지만 아직 AR model을 replace하기에는 무리가 있다고 생각한다.
그러나 매우 효율적인 구조상 discrete diffusion의 단점을 극복하면 미래에 AR model을 비용, 성능 모두에서 압도하는 결과를 보일 수도 있지 않을까?
