[논문 리뷰]Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning
diffusion
이번에는 논문에 대한 자세한 설명보다는 이해한 내용을 위주로 설명하겠다.
이 논문은 Autoregressive model의 한계점을 지적한다.
Introduction
최근 NLP에서 GPT와 같이 Autoregressive model이 매우 성공적으로 작동하는 것을 보여서 사람들이 AGI가 나온다 하면서 축제 분위기인데
사실 AutoRegressive Model은 한계점이 명확하게 존재한다.
Autoregressive model이란 이전의 input을 바탕으로 다음 input을 예측하는 모델이다.
GPT가 계속 다음 token을 예측하는 것을 생각하면 편하다.
AutoRegressive Model의 한계점은 Reasonning과 Planning에서 볼 수 있다.
기본적으로 왼쪽에서부터 오른쪽으로 word를 생성하는 GPT를 생각해보면 편한데
논문에서는 다음과 같이 문제를 구성하였다.
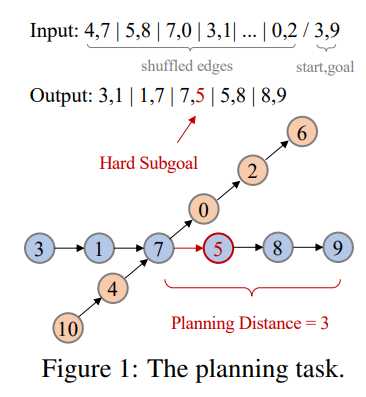 문제는 간단한게 input으로 shuffled edge와 start, goal position이 주어지면
문제는 간단한게 input으로 shuffled edge와 start, goal position이 주어지면
output으로 start에서 goal까지의 경로를 출력하는 것이다.
간단한 planning 문제라고 볼 수 있다.
여기에서 논문의 중요한 요점인 subgoal imbalance가 나온다.
subgoal imbalance
이 부분이 왜 있는건지 잘 이해가 안갔는데
원본 설명은 다음과 같다.
Proposition 1 (Subgoal imbalance due to the unknown data distribution q(x)) The autoregressive modeling decomposes the model distribution pθ(x) into multiple subgoals: pθ(x1), . . . , pθ(xN | x1:N−1). Given that the true data distribution q(x) is unknown, the generation of individual tokens may not inherently follow an autoregressive pattern (i.e., xn ̸∼ q(xn | x1:n−1)). Consequently, the difficulty of learning various subgoals can differ significantly. Given only the left context, some subgoals may require substantially more data to learn or may even be infeasible to learn.
내가 이해한 내용은 autoregressive model은 GPT를 보면 sequence를 각각 token으로 쪼갠 다음 이전 sequence를 input으로 받고 다음 token을 예측하는 subgoal prediction problem으로 만들어서 학습을 하는데
이때 각 subgoal은 difficulty가 각각 다를 수 있어서 특정 subgoal은 data가 더 있어야 학습할 수 있다는 내용이다.
이것 보다는 내가 이해한 내용을 설명하겠다.
쉬운 설명
처음 보인 예시 문제에서
 위처럼 output을 점점 생성해나가는 Autoregressive model을 생각해보자
위처럼 output을 점점 생성해나가는 Autoregressive model을 생각해보자
그림을 보면 상대적으로 3, 1에서 다음 path를 예측하는 것은 선택지가 1개이기 때문에 상대적으로 쉽지만 7은 선택지가 2개이기 때문에 매우 어렵다.
이를 subgoal imbalance라고 생각하면 될 것 같다.
이때 다음 token을 예측하기는 매우 어려운데 다음 diffusion model을 생각해보자
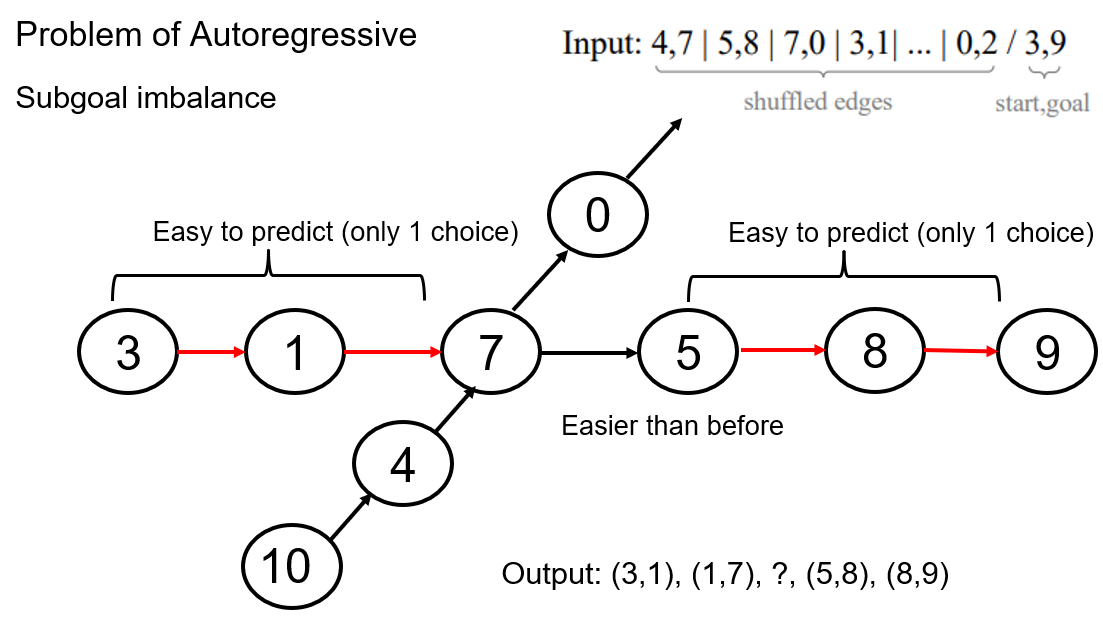
만약 위 diffusion model처럼 뒤에 나올 경로를 알 수 있다면 예측은 매우 쉬워진다.
즉 내가 이해하기로는 subgoal 중 난이도가 각자 다른 부분이 존재하고 이 subgoal에서 어려운 부분 때문에 autoregressive model은 생성이 막힐 수 있다.
하지면 diffusion model은 뒷부분도 생성을 할 수 있기에 뒤에서 추가적인 정보를 얻을 수 있기 때문에 autoregressive model에 비해서 이점을 가진다.
위처럼 diffusion model은 planning에 이점이 있기 때문에 나중에 좋은 선택지가 되지 않을까 싶다.
결과
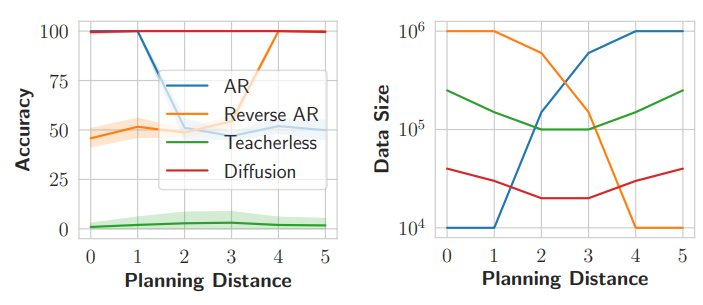 실제로 Autoregressive model이 매우 성능이 뛰어나고 필요한 data의 숫자도 적다.
실제로 Autoregressive model이 매우 성능이 뛰어나고 필요한 data의 숫자도 적다.
