이 논문도 핵심만 빠르게 리뷰하겠다. 자세한 내용은 직접 읽어보길 바란다.
Introduction
우선 LLM은 COT 등의 방법으로 test time에 computation을 추가로 넣어서 성능을 올리는 것이 가능하다.
하지만 diffusion model은 test time에 denoising step을 증가시킬 수 있지만 그렇게 해도 어느정도 성능이 증가하면 plateau에 빠진다.
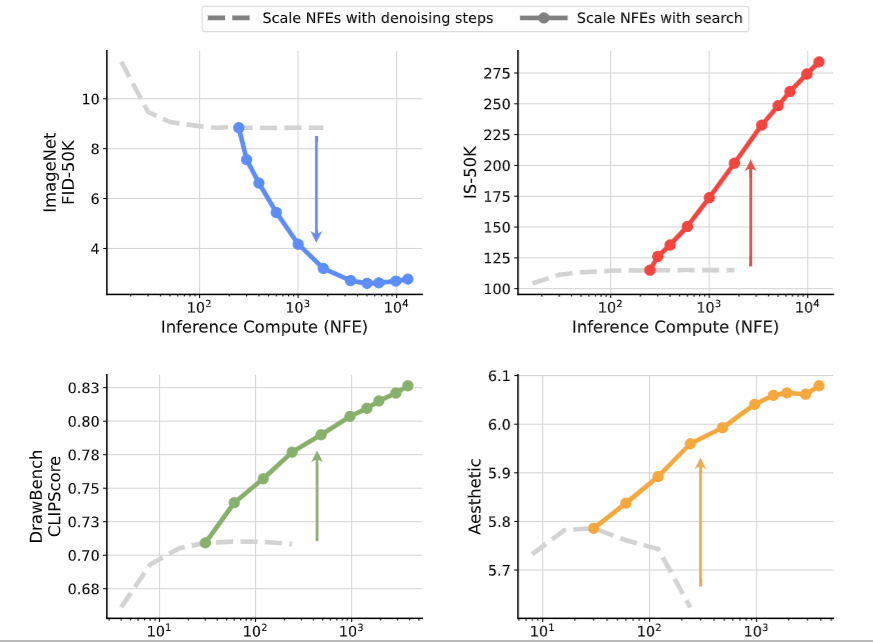 하지만 이 논문은 test time에 computation을 추가로 넣어서 diffusion의 성능을 끌어올리는 방법을 제시한다.
하지만 이 논문은 test time에 computation을 추가로 넣어서 diffusion의 성능을 끌어올리는 방법을 제시한다.
그 방법은 초기 noise setting이다.
 위 ddpm의 sampling 부분을 보면 를 처음에 샘플링하는데 어떻게 샘플링 되느냐에 따라서 성능의 편차가 생각보다 크게 존재한다.
위 ddpm의 sampling 부분을 보면 를 처음에 샘플링하는데 어떻게 샘플링 되느냐에 따라서 성능의 편차가 생각보다 크게 존재한다.
이때 원래는 denoising 각 step마다 noise를 더해주지만 이는 SDE(stochastic differential equation)확률미분 방정식 관점에서의 denoising이고
이 논문에서는 ODE(ordinal differential equation)의 관점으로 denoising을 진행해서 haun? heun? sampler를 진행하기에 초기 noise 말고는 randomness가 업다고 한다.
즉, 초기 를 뽑을때를 제외하면 denoising step에서 randomness가 없고 deterministic하게 진행이 된다고 생각하면 된다.
그래서 이 논문은 어떻게 초기 sample 를 잘 뽑을 수 있을까? 가 주요 요지이다.
method
우선 탐색은 2가지 axis로 봐야 하는데
- verifier: 어떤게 좋은 noise인지 평가
- algorithm: 평가 점수로 어떻게 좋은 noise를 찾을지
위 2개의 축으로 구성된다.
그리고 각각 다시 3개의 구성요소로 구성되는데
- verifier
- oracle: 마지막 결과를 안다(평가 metric)
- supervised: conditional 생성에서 condition target을 안다.
- self-supervised: conditional 생성에서 condition target을 모른다.
- algorithm
- random: 랜덤으로 noise 뽑고 좋은거 1개 선택
- zero-order search: 랜덤으로 1개 뽑은 noise 주변 candidate 탐색해서 가장 좋은걸 기준으로 다시 랜덤으로 뽑고 반복
- search over path: 위 과정들은 처음 noise 단계에서부터 샘플링을 위해서 denoising step 끝까지 진행하는 과정을 반복하는 식의 cost가 크기 때문에 denosing 중간에 찾는 방법
이고
이를 하나씩 자세히 다루겠다.
verifier
oracle
oracle은 간단하게 최종 평가 metric이다. FID, IS 등으로 원래 GAN등 생성형 모델을 평가할 때 사용하는 metric으로 현재 noise candidate 들을 마지막 step까지 생성해서 최종 나온 결과를 평가하는 것이다.
supervised
앞에서 생성할때 conditional 생성이라고 하였다.
이때 CLIP, DINO와 같은 모델이 pretrain되어 있다면 이 모델을 이용하여 생성된 이미지를 classification을 진행하고 생성할 때 준 label을 이용하여 그 logit을 통해 잘 생성이 되었는지 평가할 수 있다.
즉, class를 1로 주고 생성한 이미지를 classifier에 넣었을 때 class 1의 logit이 높으면 잘 생성한 것이고 낮으면 잘못 생성한 것이겠다.
self supervised
앞에서 dino, clip에 label을 가지고 평가하였는데 이를 모를 때의 가정이다.
이때에는 이전에는 logit으로 평가를 하였는데 이제 label을 모르니까 어느것이 logit인지 모른다.
하지만 샘플의 denoising 단계가 많이 진행되었을 때 인 단계와 인 최종 결과물의 cosing distance가 낮으면 원래 label의 logit이 높다는 인과관계를 찾을 수 있었다.
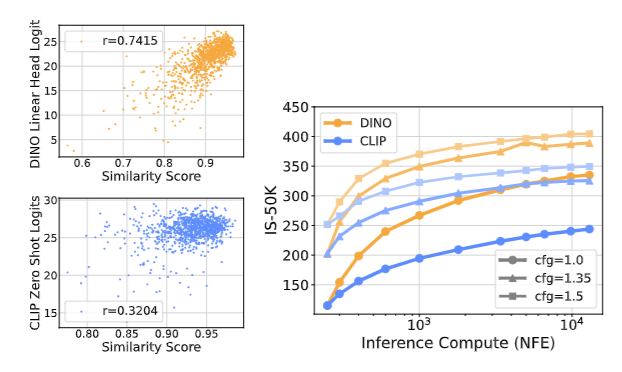 위 그림의 왼쪽처럼 noise가 적은 이미지와 최종 이미지의 cosine 유사도가 크면 실제 label의 logit이 커진다.
위 그림의 왼쪽처럼 noise가 적은 이미지와 최종 이미지의 cosine 유사도가 크면 실제 label의 logit이 커진다.
이를 통해 cosine 유사도를 기준으로 판단한다.
algorithm
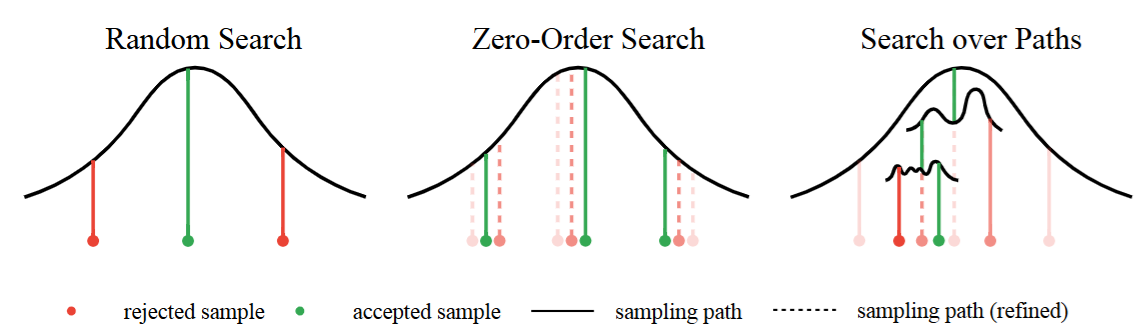
random
random으로 noise를 여러개 뽑은 다음 이를 최종 생성하고 이들을 평가하였을 때 가장 좋은 것을 선택하는 알고리즘.
naive하다.
Zero-order search
위 그림에서는 3개인데 1개라고 생각하고 해보자
1개의 noise를 기준으로 가까운 거리에 후보 noise들을 여러개 뽑는다.
그리고 그 후보 noise들을 전부 생성한 후에 가장 점수가 좋은 것이 있을 것인데
이를 다시 기준 noise로 잡고 가까운거리에 후보 noise를 뽑는 것을 반복.
간단하게 gradient descent 느낌으로 기준을 계속 옮겨가는 것이다.
이때 gradient descent는 first order인데 여기에서는 sampling으로 미분이 없으니까 zero-order이다.
Search over path
위 과정들은 후보를 정하고 끝까지 샘플링 한 다음에 평가하는 것이었는데
이는 cost적으로 비효율적으로 보일 수 있다.
Search over path는
처음 를 N개를 뽑고 로 일정 단계까지 denoising을 한 다음에
각 독립적인 noise M개를 뽑아서 로 noise를 조금 더해준다. 이러면 현재 NxM개의 noise sample들이 있을 것이다.
그리고 로 denoising을 해준다.
이제 denoising 된 sample을 verifier로 평가하는데 이때 noise가 끼어서 제대로 평가할 수 없으니 조금 더 denoising을 더해주고 평가해준다고 한다.
아마 를 예측하고 그것을 토대로 평가하는게 아닐까 싶다.
이후 이렇게 평가된 NxM개의 sample 중 N개만 뽑고 다시 noise M개 더해주고 denoisning 하고 평가하고 N개 뽑고 반복이다.
결론
초기 noise에 따른 성능차이가 존재하고 어떻게 좋은 초기 noise를 찾을까에 대한 내용이다.
