이번에도 재밌는 논문을 알게 되어서 다른 사람도 읽었으면 좋겠어서 가져왔다.
아직 자세히 읽지는 않았고 이해하지 않고 간략하게 읽어서 참고용도로 읽기 바란다.
추후 기회가 되면 자세히 논문리뷰를 작성해보겠다.
소개
titans 논문은 test time에 어떻게 memorize를 할까? 에 관한 논문이다.
기존의 RNN, LSTM 등은 각각 hidden state로 정보를 압축해서 저장을 하려는 목표가 있었는데
최근의 transformer는 각 embedding을 덧붙이면서 기억을 하는 것으로 볼 수 있다.
이때 transformer는 모든 embedding을 유지하면서 모든 기억을 retrieve할 수 있고 잘 활용할 수 있지만 token을 점점 생성하면서 O(N^2)으로 computation이 점점 늘어난다.
그렇기에 이 논문은 어떻게 이전의 RNN, LSTM의 hidden state처럼 정보를 압축해서 저장할지 아이디어를 제시한다.
모델
크게 3가지로 구성이 되는데
- core: 사람의 전두엽 처럼 주어진 context에서 계산을 수행하는 역할
- Long-term Memory: 장기 기억으로 정보를 저장하는 memory test time에 학습
- Persistent Memory: 학습가능하고 data에 independent한 기억이다. 약간 task specific한 정보인 것 같다.
위 그림은 메모리를 사용하는 여러가지 방법 중 하나이다. 참고해서 보면 될 것 같다.
여기에서 아무래도 장기기억이 제일 중요할 것 같은데
장기기억의 구조를 간략히 적어보겠다.
우선 정보를 저장할 때 어떻게 이 정보가 놀라운지 아닌지 알 수 있을까?
이는 gradient의 크기로 측정을 하였다.
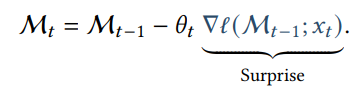 그래서 놀라운 정보는 더 담고 아닌 정보를 parameter에 덜 담는 것이다.
그래서 놀라운 정보는 더 담고 아닌 정보를 parameter에 덜 담는 것이다.
이때 너무 놀라운 정보가 들어오면 기억이 싹다 갈아엎고 이전의 정보를 잊을 수 있으니까
momentum을 추가한다.
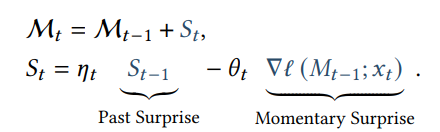
이것이 정보를 저장하는 방법이다.
이때 loss는 어떻게 되는 것일까?
만약 query, key, value의 구조에서
 key와 value를 위와 같이 설정한다면
key와 value를 위와 같이 설정한다면
memory architecture를 이용해서
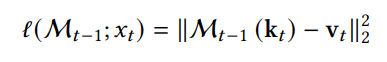 key로 value를 예측하는 구조로 loss를 구성하였다.
key로 value를 예측하는 구조로 loss를 구성하였다.
왜 이렇게 구성한지는 자세히 안읽어서 잘 모르겠다.
논문소개니까...
이후 정보를 찾을 때에는
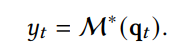 query를 이렇게 넣어서 찾는다.
query를 이렇게 넣어서 찾는다.
결국
이때 기억을 너무 많이하려고 하면 터질 수 있기에 forget 즉 까먹는 term도 있는데 이는 decay로 구현이 되었다.
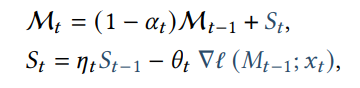
만약 이면 이전 memory의 모든 것을 바로 까먹는 것이다.
결론
현재 인턴중이라 바빠서 잘 못읽어봤는데
test time memory는 매우 유용하게 사용될 수 있을 것 같다.
사실 나는 인공지능이 폭발적으로 성장하기 위해서는 사람과 같이 기억력을 가져야 한다고 생각한다.
기억을 할 수 있으면 이전에 자신의 실수와 잘한 내용을 기억하고 개선할 수 있지 않을까? 생각했기 때문이다.
그렇기에 이번 titan논문은 meta learning 등 다양한 방법론이 복합적으로 사용이 되었는데 그렇기에 다른 사람들도 꼭 읽어봤으면 좋겠는 논문이라 소개한다.
