세미나 자료 준비하면서 정리
우선 간단한 정리
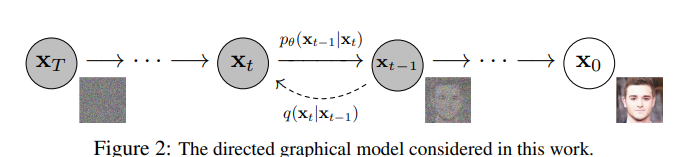
p(x0,x1,...,xT)=p(x0∣x1)p(x1∣x0)...p(xT−1∣xT)p(xT)=p(xT)∏i≥1p(xi−1∣xi)
p(x1,x2,...,xT∣x0)=p(x1∣x0)p(x2∣x1)...p(xT∣xT−1)=∏i≥1p(xt∣xt−1)
라고 하자
-log likelihood를 간접적으로 상승시키는 것이 목적
−logpθ(x0)=−log∫x1:Tpθ(x0,x1,...,xT)dx1:T
=−log∫x1:Tpθ(x0:T)q(x1:T∣x0)q(x1:T∣x0)dx1:T
=−logEq(x1:T∣x0)[q(x1:T∣x0)pθ(x0:T)]
from Jensen's Inequality
−logpθ(x0)≤Eq(x1:T∣x0)[−logq(x1:T∣x0)pθ(x0:T)]
=Eq(x1:T∣x0)[−log∏i≥1q(xt∣xt−1)pθ(xT)∏i≥1pθ(xi−1∣xi)]
=Eq(x1:T∣x0)[−logpθ(xT)−∑i≥1logq(xt∣xt−1)pθ(xt−1∣xt)]
=Eq(x1:T∣x0)[−logpθ(xT)−∑i>1logq(xt∣xt−1)pθ(xt−1∣xt)−logq(x1∣x0)pθ(x0∣x1)]
이때 q(xt∣xt−1)=q(xt∣xt−1,x0)=q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0)
=Eq(x1:T∣x0)[−logpθ(xT)−∑i>1logq(xt−1∣xt,x0)pθ(xt−1∣xt)q(xt∣x0)q(xt−1∣x0)−logq(x1∣x0)pθ(x0∣x1)]
=Eq(x1:T∣x0)[−logq(xT∣x0)pθ(xT)−∑i>1logq(xt−1∣xt,x0)pθ(xt−1∣xt)−logpθ(x0∣x1)]
pθ(xT):=p(xT)학습 x
=Eq(x1:T∣x0)[−logq(xT∣x0)p(xT)−∑i>1logq(xt−1∣xt,x0)pθ(xt−1∣xt)−logpθ(x0∣x1)]
결국
−logpθ(x0)≤Eq(x1:T∣x0)[DKL(q(xT∣x0)∣∣p(xT))+∑i>1DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))−logpθ(x0∣x1)]
오른쪽 elbo를 줄이면 −logpθ(x0)가 줄어들어서 likelihood가 증가
