Raft Basic
A Raft cluster contains several servers; five is a typical number, which allows the system to tolerate two failures. At any given time each server is in one of three states: (unique)leader, follower, or candidate.
Raft divides time into terms of arbitrary length.
About
Term
- numbered with consecutive integers
- begins with an election
- If vote splitted, the term will end with no leader; a new term will be started
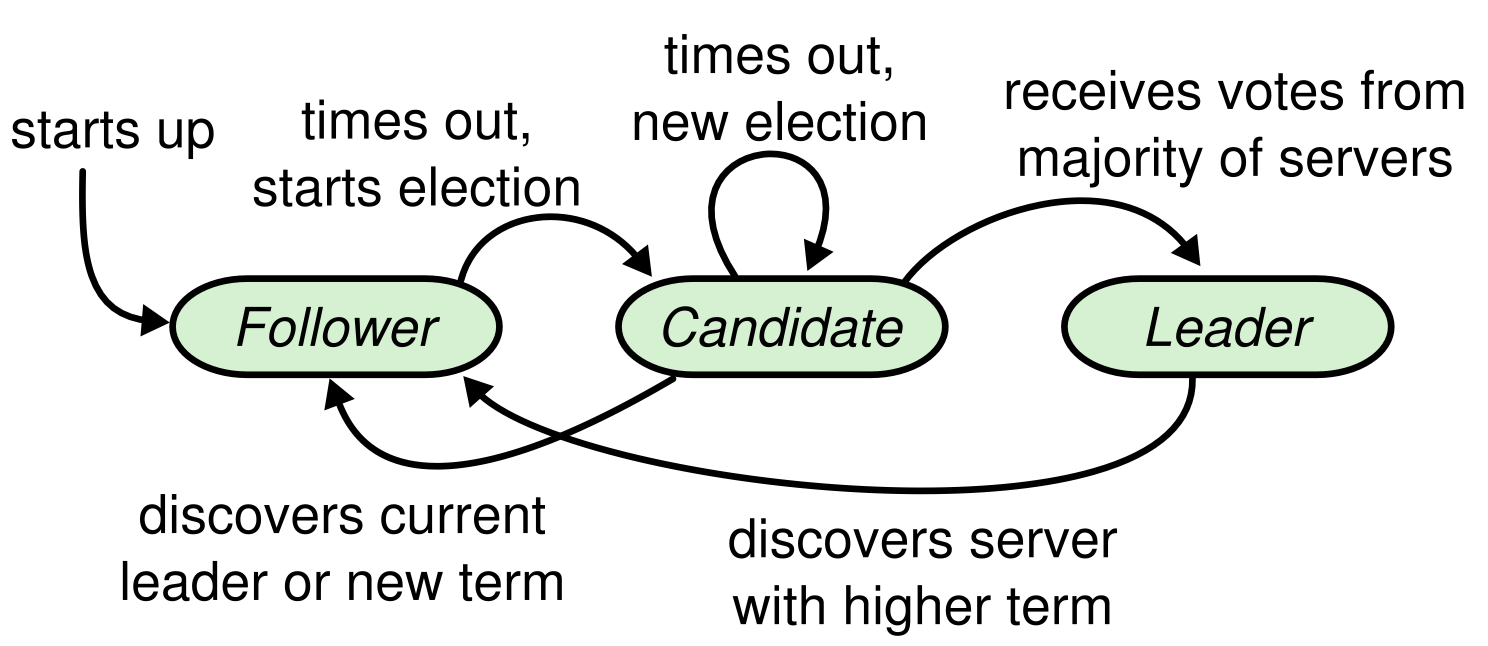
If a follower receives no communication, it becomes a candidate and initiates an election. A candidate that receives votes from a majority of the full cluster becomes the new leader.
Leaders typically opeerate until they fail.
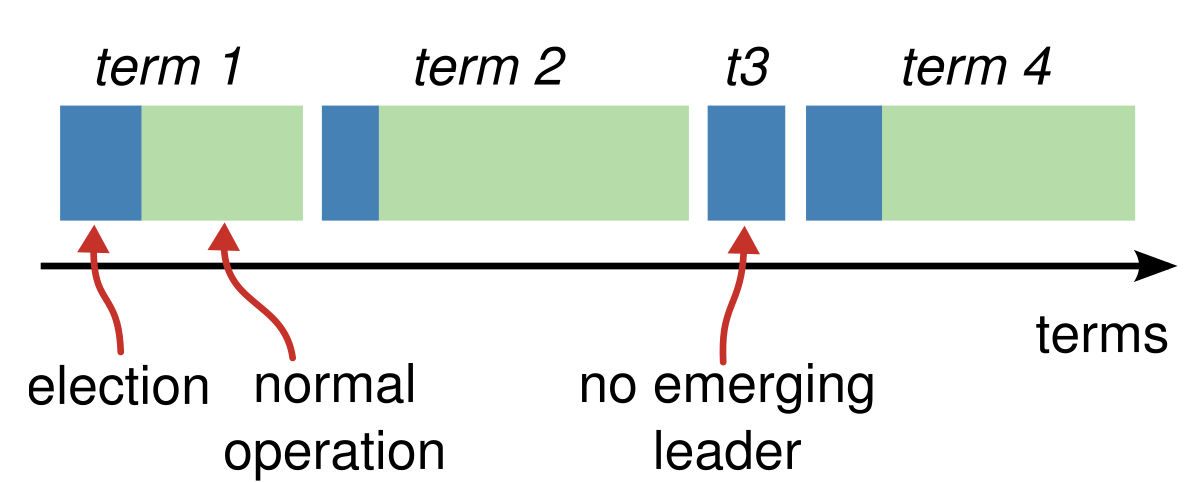
- server’s current term is smaller -> updates its current term to the larger value
- candidate or leader discovers that its term is out of date -> immediately reverts to follower state.
- server receives a request with a stale term number -> reject the request
- RequestVote RPCs are initiated by candidates during elections
- AppendEntries RPCs are initiated by leaders
Leader election
- Leader send periodic heartbeats (
AppendEntriesRPCs that carry no log entries) - If a follower receives no communication over a period of time called the
election timeout, then it begins an election to choose a new leader - Increase term, votes for itself and issues
RequestVoteRPCs in parallel to each of the other servers in the cluster. - This status until one of three things happens:
- It wins the election
- Another server establishes itself as leader
- A period of time goes by with no winner. Each candidate will time out and start a new election by increments its term and initiating another round of
RequestVoteRPCs.
How to win election
A candidate wins an election if it receives votes from a majority of the servers in the full cluster for the same term. Majority rule ensures Election Safety Property. Once a candidate wins an election, it becomes leader.
Receive AppendEntries RPC while Vote
AppendEntries RPC from another server claiming to be leader. If the leader’s term (included in its RPC) is at least as large as the candidate’s current term, then the candidate recognizes the leader as legitimate and returns to follower state.
Randomized Election
Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly. To prevent split votes in the first place, election timeouts are chosen randomly from a fixed interval (e.g., 150–300ms).
The same mechanism is used to handle split votes. Each candidate restarts its randomized election timeout at the start of an election, and it waits for that timeout to elapse before starting the next election
Election restriction
Raft uses the voting process to prevent a candidate from winning an election unless its log contains all committed entries. The RequestVote RPC implements this restriction: the RPC includes information about the candidate’s log, and the voter denies its vote if its own log is more up-to-date than that of the candidate.
up-to-date: The logs have last entries with different terms and the log with the later term is more up-to-date
Log replication
Once a leader has been elected, it begins servicing client requests. When new command has added, the leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry. If followers crash or run slowly, or if network packets are lost, the leader retries AppendEntries RPCs indefinitely (even after it has responded to the client) until all followers eventually store all log entries.
Commit Entry
The leader decides when it is safe to apply a log entry to the state machines; such an entry is called committed. Raft guarantees that committed entries are durable and will eventually be executed by all of the available state machines. A log entry is committed once the leader that created the entry has replicated it on a majority of the servers. This also commits all preceding entries in the leader’s log, including entries created by previous leaders. After that, leader respond to the client.
Committing entries from previous terms
How to guarantee consistency
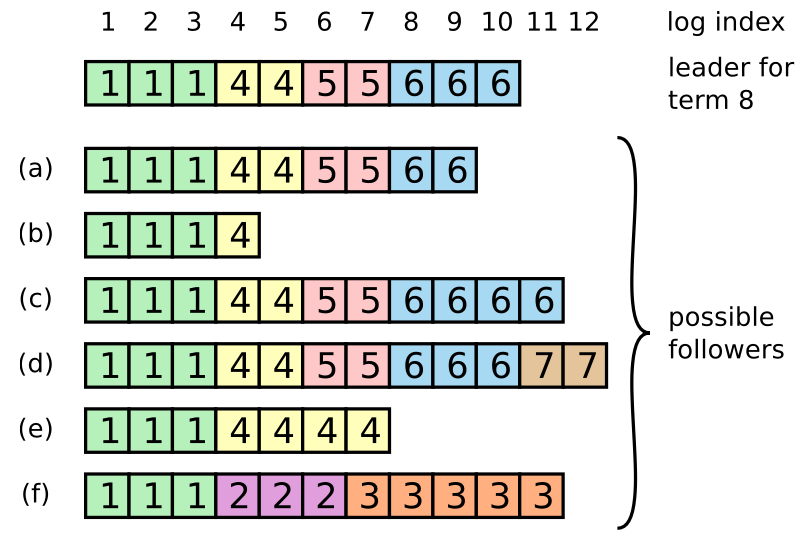
- (a - b): A follower may be missing entries
- (c - d): May have extra uncommitted entries
- (e - f): both
In Raft, the leader handles inconsistencies by forcing the followers’ logs to duplicate its own.
To bring a follower’s log into consistency with its own, the leader must find the latest log entry where the two logs agree, delete any entries in the follower’s log after that point, and send the follower all of the leader’s entries after that point. The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower. The leader maintains a nextIndex for each follower, which is the index of the next log entry the leader will send to that follower. After a rejection of AppendEntries RPC, the leader decrements nextIndex and retries the AppendEntries RPC. Eventually nextIndex will reach a point where the leader and follower logs match.
Optimized protocol
the protocol can be optimized to reduce the number of rejected AppendEntries RPCs. AppendEntries RPC can include the term of the conflicting entry and the first index it stores for that term. In practice, we doubt this optimization is necessary, since failures happen infrequently and it is unlikely that there will be many inconsistent entries.
Committing entries from previous terms
In Raft, a log entry from a previous term isn't considered committed just because it's replicated on a majority of servers. Instead, Raft only commits log entries from the current leader's term based on majority replication. Once an entry from the current term is committed, all preceding entries are considered committed due to the Log Matching Property. Raft avoids reassigning term numbers to older entries, maintaining consistency and simplicity in reasoning about the log. This approach contrasts with other consensus algorithms, which may require renumbering and re-replicating old entries.
Follower and candidate crashes
If a follower or candidate crashes, then future RequestVote and AppendEntries RPCs sent to it will fail. Raft handles these failures by retrying indefinitely; if the crashed server restarts, then the RPC will complete successfully
Timing and availability
One of our requirements for Raft is that safety must not depend on timing: the system must not produce incor- rect results just because some event happens more quickly or slowly than expected. Leader election is the aspect of Raft where timing is most critical.
broadcastTime ≪ electionTimeout ≪ MTBF
- broadcastTime: Average time it takes a server to send RPCs in parallel to every server in the cluster and receive their responses
- MTBF: Average time between failures for a single server.
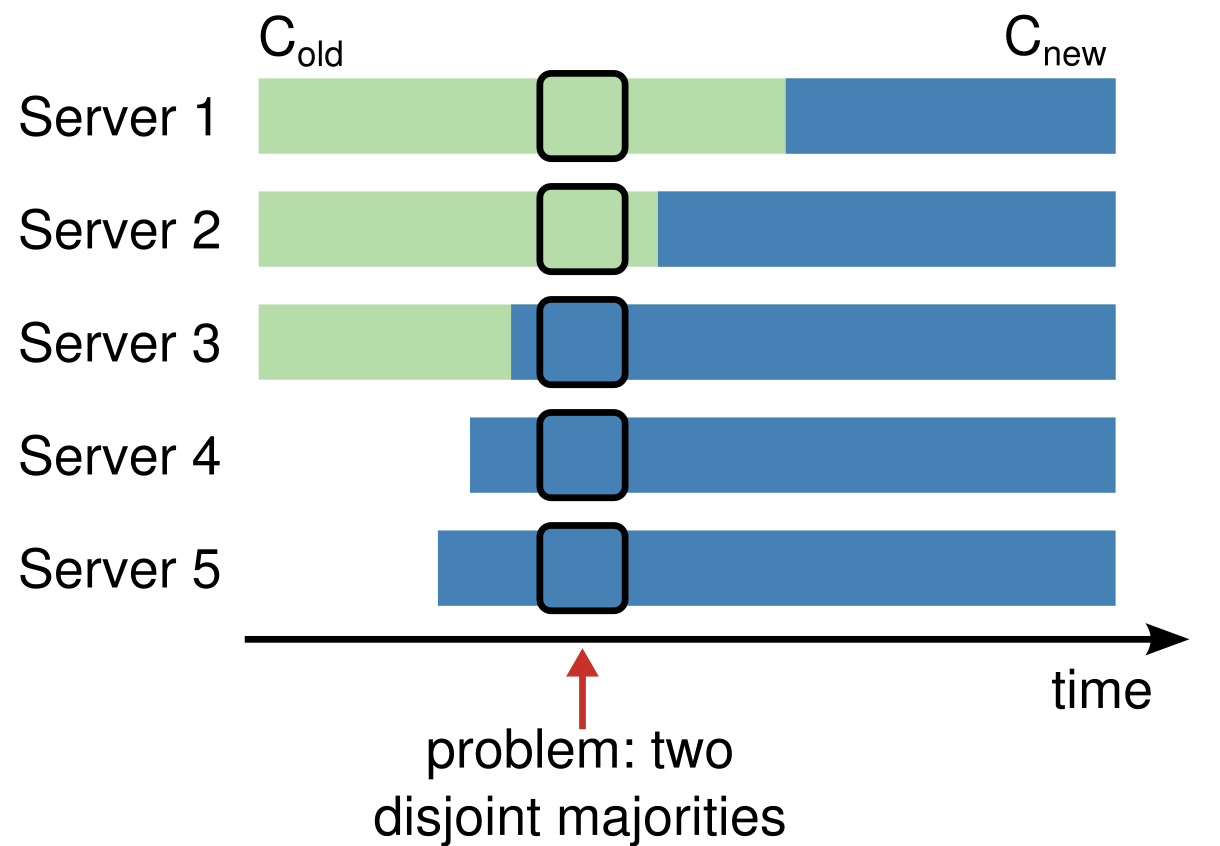
Switching directly from one configuration to an- other is unsafe because different servers will switch at dif- ferent times.
