벨만-포드 알고리즘이란?
한 노드에서 다른 노드까지의 최단 거리를 구하는 알고리즘이다. 다익스트라 알고리즘이 모든 가중치가 양수인 경우에만 사용할 수 있는 반면에 벨만-포드 알고리즘은 노드 간의 간선 가중치가 음수인 경우에도 사용할 수 있다.
다익스트라 알고리즘 VS 벨만-포드 알고리즘
다익스트라의 시간 복잡도는 O(V^2)인 것에 비해 벨만-포드 알고리즘은 O(VE)이다. dense graph인 경우 E는 V^2에 근사해지므로 다익스트라 알고리즘이 더 빠르다는 것을 알 수 있다. 하지만 음수의 가중치를 가진 경로의 경우 벨만-포드를 이용해야 한다. negative-cycle 즉, 무한히 시간이 작아지는 것을 고려해야 하기 때문이다.
벨만-포드 알고리즘
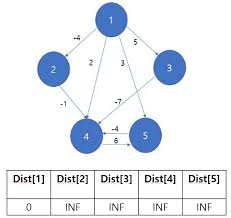
- 출발 노드 설정
- 최단 거리 테이블 초기화
- 다음의 과정을 N - 1번 반복한다.
- 전체 간선 E개를 하나씩 확인.
- 각 간선을 거쳐 다른 노드로 가는 비용을 계산하여 최단 거리 테이블을 갱신. 현재 노드의 거리를 알 수 없다면 무시한다.
만약 음수 간선 순환이 발생하는지 체크하고 싶다면 3번의 과정을 한 번 더 수행한다. 이때(N 번 째 순환) 최단 거리 테이블이 갱신된다면 음수 간선 순환이 존재하는 것이다.
왜 N 번 탐색을 해야 하는지에 대해서 생각을 해보!
면 생각보다 간단하다. N 개의 노드에서 n - 1까지의 탐색을 마친다면 어떤 그래프일지라도 하나의 노드에서 가장 먼 노드까지의 탐색이 끝난 상태이다. 한 번 더 탐색을 했는데 최솟값이 업데이트된다는 것은 negetive cycle이 존재하지 않고서는 불가능하기 때문에 N 번까지 탐색을 해봐야 한다.
백준 11657번 타임머신에서 활용할 수 있다.
유투브 링크
잘 정리된 유투브 링크이다.
import sys
def bf(start):
dist[start] = 0
# n - 1만큼 반복해야 함
for i in range(n):
# 모든 간선들을 확인하기 위함
for cur, next, cost in vertexes:
if dist[cur] != 1e9 and dist[next] > dist[cur] + cost:
dist[next] = dist[cur] + cost
if i == n - 1:
return True
return False
input = sys.stdin.readline
n, m = map(int, input().split())
vertexes = []
dist = [1e9 for _ in range(n + 1)]
for _ in range(m):
vertexes.append(list(map(int, input().split())))
if bf(1):
print(-1)
else:
for i in range(2, n + 1):
print(dist[i] if dist[i] != 1e9 else -1)
٩( ᐛ )و