
이전 글 -
2024.01.24 - [개발] - [AI 음성 생성] AWS Polly(폴리)를 이용한 TTS(Text To Speech, 음성 합성) 구현 (3) - Streamlit 프로젝트
이전 글에서 AWS polly를 활용한 음성합성 프로젝트를 하나 만들어봤었는데요.
실제로 이 서비스를 프로덕션에서 운영하면서 사용자들에게 비용을 지불할 수 있게 하려면, 사용량에 대한 체크가 필요해요. 프리 티어에서 월 몇 백만 글자를 제공한다고 해도, 어느 정도 소진되고 있는지는 알아야 비용을 책정할 수 있으니까요!
그래서 AWS 에서 각 서비스의 사용량에 대한 정보를 제공하는 API 가 있는지 살펴보다가, Boto3에서 Cloudwatch 클라이언트를 통해 데이터를 제공한다는 걸 알게 됐어요. 자세한 내용은 Boto3 Documentation에 담겨 있는데요, 일단 클라우드워치가 뭔지부터 알아볼게요.
문서에서는 클라우드 워치를 아래와 같이 설명하고 있어요.
아마존 클라우드워치는 아마존 웹 서비스 (Amazon Web Services) 리소스 및 해당 리소스 및 애플리케이션의 실시간 모니터링을 제공합니다. 클라우드워치를 사용하여 리소스 및 애플리케이션에 대한 측정항목인 메트릭을 수집하고 추적할 수 있습니다.
클라우드워치 알람은 규칙을 정의한 기준에 따라 모니터링 중인 리소스를 변경하거나 알림을 보냅니다. 예를 들어, Amazon EC2 인스턴스의 CPU 사용률 및 디스크 읽기/쓰기를 모니터링할 수 있습니다. 그런 다음 이 데이터를 사용하여 부하 증가를 처리하기 위해 추가 인스턴스를 시작해야 하는지 여부를 결정할 수 있습니다. 또한 이 데이터를 사용하여 미사용 중인 인스턴스를 중지하여 비용을 절약할 수 있습니다.
아마존 웹 서비스와 함께 제공되는 내장 메트릭을 모니터링하는 것 외에도 사용자 정의 메트릭을 모니터링할 수 있습니다. 클라우드워치를 사용하면 리소스 이용률, 애플리케이션 성능 및 운영 건강에 대한 시스템 전반적인 가시성을 얻을 수 있습니다.
실시간 모니터링을 제공하는게 클라우드 워치 서비스의 핵심인데요, 모니터링하면서 수집한 데이터들을 Boto3을 통해서도 읽을 수 있더라고요.
# get_metric_statistics
Boto3는 get_metric_statistics를 통해 수치 데이터를 제공하고 있어요. 기본적으로 시간의 범위를 지정하여 데이터를 조회할 수 있는데, 짧은 주기의 수집 데이터는 시간이 지나면 사라져요. 예를 들어, 60초(1분) 주기로 수집된 데이터는 15일 동안 조회 가능하고, 300초(5분) 주기로 생성된 데이터는 63일, 3600초(1시간) 단위로 생성된 데이터는 455일(15개월) 동안 조회할 수 있어요.
아무래도 데이터가 많아지니까 초기에 더 자세히 수집된 데이터를 소멸시키는 것 같아요.
CloudWatch.Client.get_metric_statistics(**kwargs)
지정된 메트릭에 대한 통계 정보를 가져옵니다.
단일 호출에서 반환되는 데이터 포인트의 최대 수는 1,440개입니다. 1,440개 이상의 데이터 포인트를 요청하면 CloudWatch에서 오류를 반환합니다. 데이터 포인트 수를 줄이려면 지정된 시간 범위를 좁히고 인접한 시간 범위에 대해 여러 요청을 수행하거나 지정된 기간을 늘릴 수 있습니다. 데이터 포인트는 시간 순서대로 반환되지 않습니다.
CloudWatch는 지정한 기간의 길이를 기반으로 데이터 포인트를 집계합니다. 예를 들어, 1시간 기간으로 통계를 요청하면 CloudWatch는 각 1시간 기간 내의 타임스탬프가 있는 모든 데이터 포인트를 집계합니다. 따라서 CloudWatch에 의해 집계되는 값의 수는 반환되는 데이터 포인트의 수보다 큽니다.
백분위 통계를 계산하려면 CloudWatch는 원시 데이터 포인트가 필요합니다. 통계 세트를 사용하여 데이터를 게시하는 경우 다음 조건 중 하나가 충족되어야만 해당 데이터에 대한 백분위 통계를 검색할 수 있습니다.
통계 세트의 SampleCount 값이 1인 경우.
통계 세트의 Min 및 Max 값이 동일한 경우.
메트릭 값 중에 음수인 경우 메트릭에 대한 백분위 통계를 사용할 수 없습니다.
Amazon CloudWatch는 메트릭 데이터를 다음과 같이 보존합니다.
60초 미만의 주기로 생성된 데이터 포인트는 3시간 동안 사용 가능합니다. 이러한 데이터 포인트는 고해상도 메트릭이며 StorageResolution이 1로 정의된 사용자 정의 메트릭에만 사용 가능합니다.
60초 (1분) 주기로 생성된 데이터 포인트는 15일 동안 사용 가능합니다.
300초 (5분) 주기로 생성된 데이터 포인트는 63일 동안 사용 가능합니다.
3600초 (1시간) 주기로 생성된 데이터 포인트는 455일 (15개월) 동안 사용 가능합니다.
초기에 더 짧은 주기로 게시된 데이터 포인트는 장기 보관을 위해 집계됩니다. 예를 들어, 1분 주기로 데이터를 수집하면 데이터는 1분 해상도로 15일 동안 사용 가능합니다. 15일이 지난 후에도 데이터는 사용 가능하지만 5분 해상도로만 집계 및 검색할 수 있습니다. 63일이 지난 후에는 데이터가 추가로 집계되며 1시간 해상도로 사용 가능합니다.
CloudWatch는 2016년 7월 9일부터 5분 및 1시간 메트릭 데이터를 보존하기 시작했습니다.
# 데이터 요청
데이터 요청은 아래처럼 할 수 있는데요, NameSpace는 AWS의 서비스를 의미해요. AWS services that publish CloudWatch metrics에서 각 서비스 별로 사용해야할 네임스페이스가 명시되어 있고, 각각의 서비스에 대해 어떤 metric(계량된 수치)을 확인할 수 있는지 문서들이 링크되어 있어요. 꼭 살펴보세요!
Polly의 경우는 이 문서에 자세히 설명되어 있어요.
MetricName은 요청 글자 수와 같이 확인하고자 하는 metric이고, Dimension은 해당 metric에 대한 필터 조건 같은 개념이에요. 여기서는 요청한 글자 수 중 음성 합성에서 사용한 수를 필터링해서 가져오고 있어요.
StartTime과 EndTime은 조회하고자 하는 기간이고, Period는 초 단위로 내가 조회하고자 하는 데이터 포인트의 단위를 의미해요. 예를 들어 86,400 초의 경우 하루를 의미하는 시간 단위이고, 하루 단위의 데이터를 조회하겠다는 의미를 가지고 있어요.
Statistics는 가져오고자 하는 집계 데이터예요. 샘플 수, 평균, 합, 최소 값, 최대 값 등을 가지고 있어요. ExtendedStatistics 백분위 수 통계를 가져올 수 있고, Unit은 집계 단위를 의미해요.
# 요청 문법
response = client.get_metric_statistics(
Namespace='string',
MetricName='string',
Dimensions=[
{
'Name': 'string',
'Value': 'string'
},
],
StartTime=datetime(2015, 1, 1),
EndTime=datetime(2015, 1, 1),
Period=123,
Statistics=[
'SampleCount'|'Average'|'Sum'|'Minimum'|'Maximum',
],
ExtendedStatistics=[
'string',
],
Unit='Seconds'|'Microseconds'|'Milliseconds'|'Bytes'|'Kilobytes'|'Megabytes'|'Gigabytes'|'Terabytes'|'Bits'|'Kilobits'|'Megabits'|'Gigabits'|'Terabits'|'Percent'|'Count'|'Bytes/Second'|'Kilobytes/Second'|'Megabytes/Second'|'Gigabytes/Second'|'Terabytes/Second'|'Bits/Second'|'Kilobits/Second'|'Megabits/Second'|'Gigabits/Second'|'Terabits/Second'|'Count/Second'|'None'
)
# polly 사용량 집계 코드
response = client.get_metric_statistics(
Namespace='AWS/Polly',
MetricName='RequestCharacters', # AWS Polly에서 문자 수를 나타내는 메트릭
Dimensions=[
{
'Name': 'Operation',
'Value': 'SynthesizeSpeech' # 'SynthesizeSpeech' 작업에 대한 메트릭
}
],
StartTime=start_datetime,
EndTime=end_datetime,
Period=86400, # 하루 단위로 데이터 집계
Statistics=['Sum'] # 총 사용량을 확인하고자 할 때
)저는 Polly를 통해 사용한 하루 단위 음성 합성에 사용된 문자 요청 수를 가져왔어요.
가져온 데이터는 가공해서 반환해 줬는데요, 일단 데이터가 시간 순서대로 오지 않아서 Timestamp 기준으로 정렬을 해줬어요.
그 뒤에는 시간대가 한국 시간과 맞지 않아서 한국 시간으로 맞추는 작업을 pytz를 통해 하였고, 각 일자별 합계를 모두 더해 총합계를 만들어줬어요.
request_character_sum = 0
response['Datapoints'].sort(key=lambda x: x['Timestamp'])
chart_data_list = []
for i in response['Datapoints']:
original_datetime = i['Timestamp']
korea_timezone = pytz.timezone('Asia/Seoul')
korea_datetime = original_datetime.astimezone(korea_timezone)
formatted_date = korea_datetime.strftime('%Y-%m-%d')
request_character_sum += i['Sum']
chart_data_list.append({
"날짜": formatted_date,
"요청 글자 수": i['Sum'],
})
return chart_data_list, request_character_sum위의 코드를 기존 streamlit 프로젝트에 반영해서 아래와 같은 결과물을 얻어냈어요. 커서를 막대에 올리면 해당 날짜와 요청 글자 수도 확인할 수 있어요.
Streamlit 덕분에 UI를 큰 품 안 들이고 만들 수 있어서 좋네요 :)
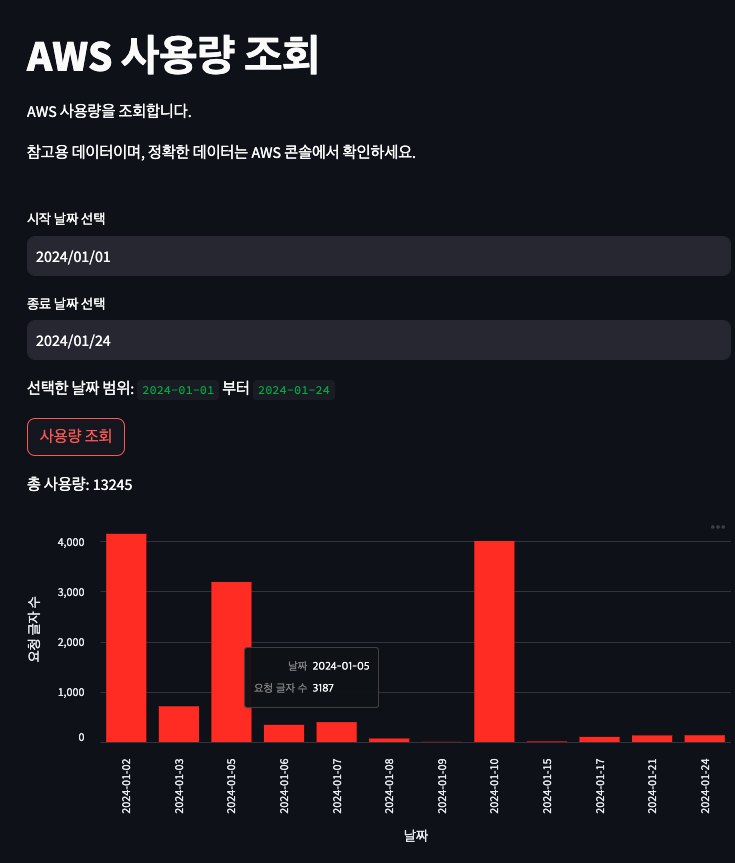
하나씩 기능을 붙여가니 점점 완성도가 올라가는 게 보여서 기분이 좋네요 ㅎㅎ
보시면서 궁금한 부분 있으면 편하게 댓글 남겨주세요~
github에서도 코드를 확인해 보세요!
