최근 자동화 툴과 AI Agent, MCP의 인기에 힘입어, 실제 업무에 적용할 수 있는 자동화 워크플로우를 구축해보았다.
자동화 툴은 n8n 을 셀프 호스팅하여 사용했고, 아이디어는 개발 커뮤니티에서 참고하여 GitHub PR과 Notion 문서를 연동하여 PR의 우선순위를 자동으로 판단하고 알림을 보내는 시스템을 만들었다.
# 워크플로우 구성
n8n에서는 전체 자동화 흐름을 'workflow'라고 부른다(Zapier에서는 Zap, Make에서는 Scenario).
최초 플로우 구성은 아래처럼 잡아봤다.
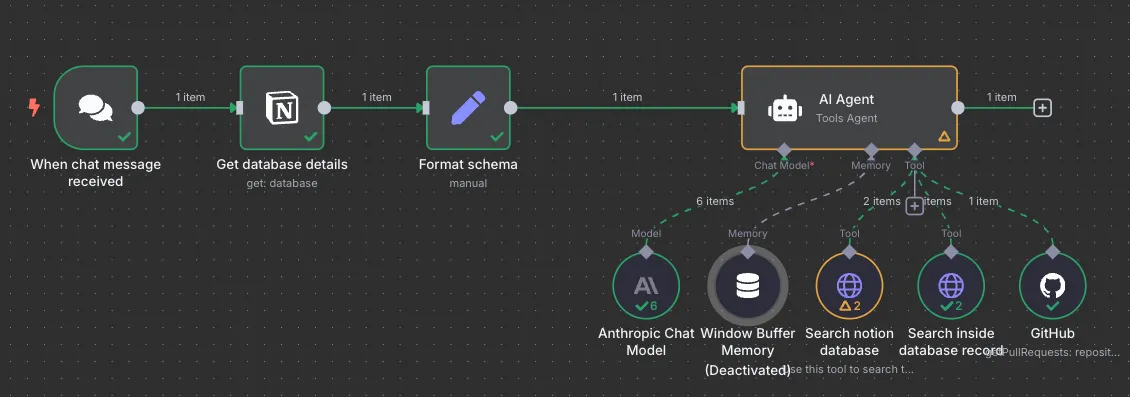
## 트리거
워크플로우의 시작점(트리거)으로 다음 옵션들을 고려했다:
- PR webhook: PR 발생 시마다 중요도를 평가할 필요는 없다고 판단. PR 자체 알림은 이미 GitHub이나 Slack을 통해 받을 수 있으며, 급한 PR은 별도 워크플로우로 처리하는 것이 좋을거라 생각.
- 스케줄러: 실제 운영 환경에서는 이 방식이 적합하나, 테스트 단계에서는 제외.
- 채팅 명령: 테스트 중 원하는 시점에 워크플로우를 실행할 수 있어 이 방식을 채택.
## 세부 플로우
노션과 관련된 워크플로우는 https://n8n.io/workflows/2413-notion-knowledge-base-ai-assistant/를 참고 했다. 처음 플로우를 만들다 보니 기존 레퍼런스를 참고하는게 좋을 것 같았고, 마침 notion database 기반으로 질문을 날리면 해당 내용을 가공하여 반환해주는 레퍼런스가 있었다.
제안해주는 방식대로 먼저 내가 지정한 노션 데이터베이스의 정보를 가져온다.
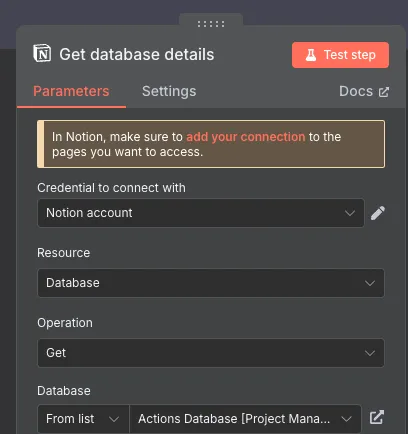
그리고 해당 데이터베이스의 이름과 id, 사용된 옵션 등을 가공해준다. LLM이 불필요한 데이터로 토큰을 소모하지 않도록 가공하는게 중간중간 필요하다.
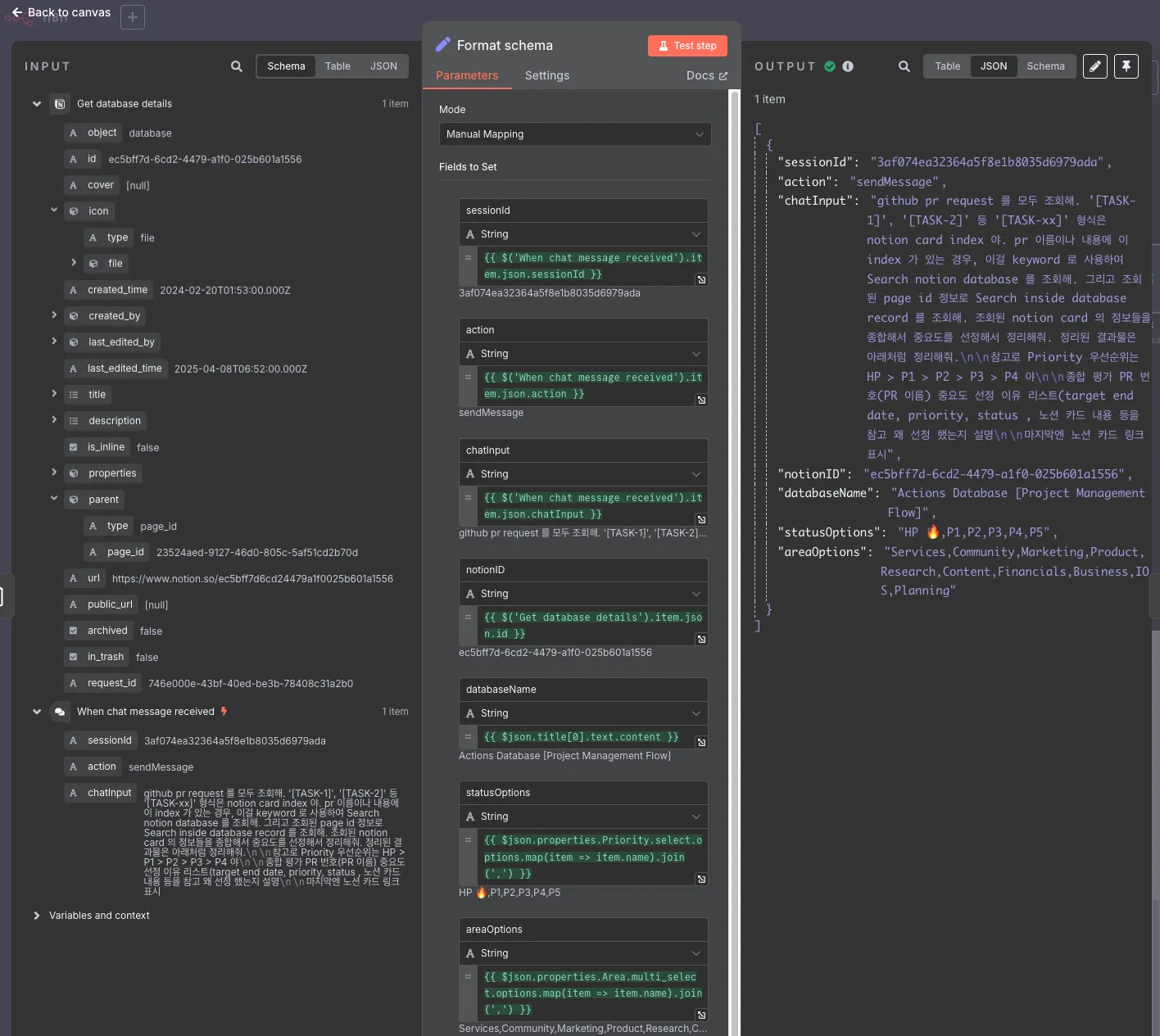
그리고 이 가공된 정보를 AI Agent 에 전달한다.
AI Agent 는 현재 ChatGPT나 Claude 에서 말하는 Agent 와 의미가 같다고 보면 될 것 같다. Agent를 이끌어갈 모델을 설정하고, Agent가 사용할 툴을 지정할 수 있다.
현재 회사에서 ai 관련 지원을 해주고 있진 않아서 Gemini 에서 제공하는 무료 API 를 사용하다가, 조금만 사용해도 임계치를 넘어서는지 반응이 느려져서 기존에 일부 충전해 놨던 Claude API 를 사용했다. 그중 모델은 저렴한 Claude 3.5 haiku 로 테스트 했다.
AWS 에도 AWS Bedrock 을 통해 api 를 제공하긴 하는데, 프리티어에서는 제공하지 않아서 패스..
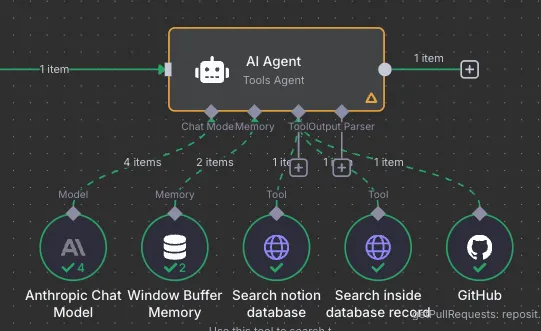
AI Agent가 해야할 일은 이렇다.
Github 노드를 통해 특정 repository의 Pull Request를 조회한다. 조회된 PR의 제목이나 내용에 노션 이슈 카드 인덱스(예를 들어 [TASK-001] 등 사용자가 지정한 값)가 있는 경우, 노션을 통해 이슈 카드를 검색하도록 한다.
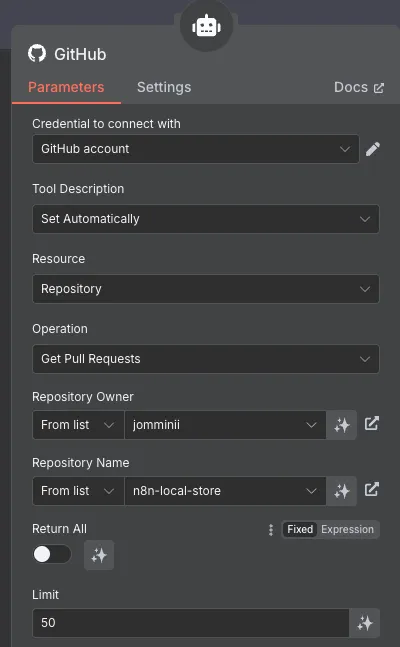
노션 카드를 조회하는 일은 두 개의 api request 노드에서 진행한다. 각각을 일종의 MCP 느낌이라고 생각해도 될 것 같다.
첫 번째 api request 노드는 이전 노션 노드에서 찾은 특정 데이터베이스의 id 값을 이용해 데이터베이스의 특정 데이터를 조회한다. 이를 위해 description 에 LLM 이 참고할 수 있게 이 툴에 대한 설명을 간략히 적는다.
그리고 request body에 노션 이슈카드 인덱스를 포함하는 노션카드를 조회하도록 한다.
이후 두 번째 요청 노드에서는 앞에서 조회한 노션 카드의 page id 로 세부 페이지를 조회해서 상세 내용을 읽어온다. (사실 첫 번째로 할 지 두 번째로 요청할지는 agent 가 판단한다)
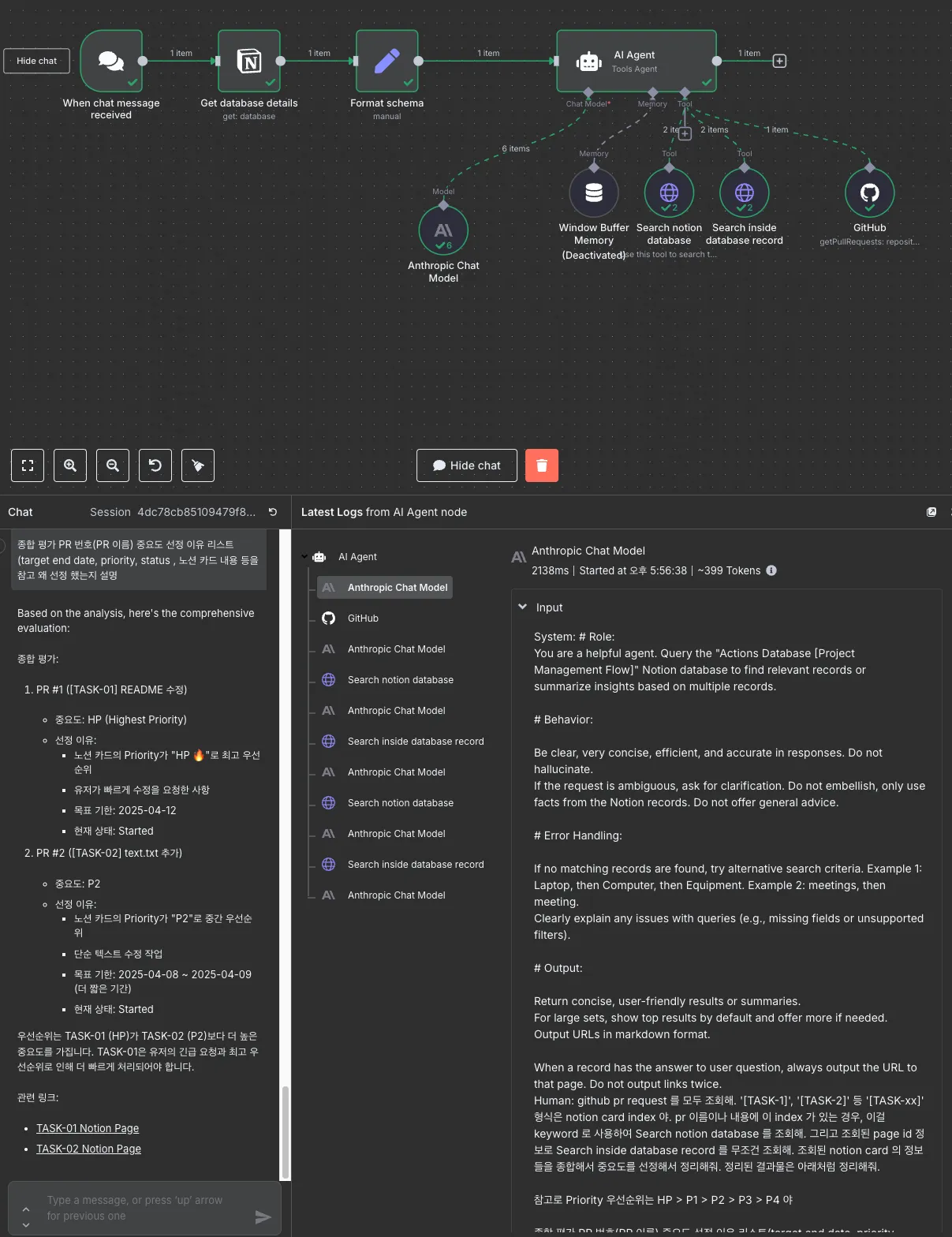
AI Agent 는 이 정보들을 조합해 PR의 우선순위를 판단해서 메시지로 돌려준다.
요청할때마다 조금은 다르지만 이런 느낌의 답변을 준다.
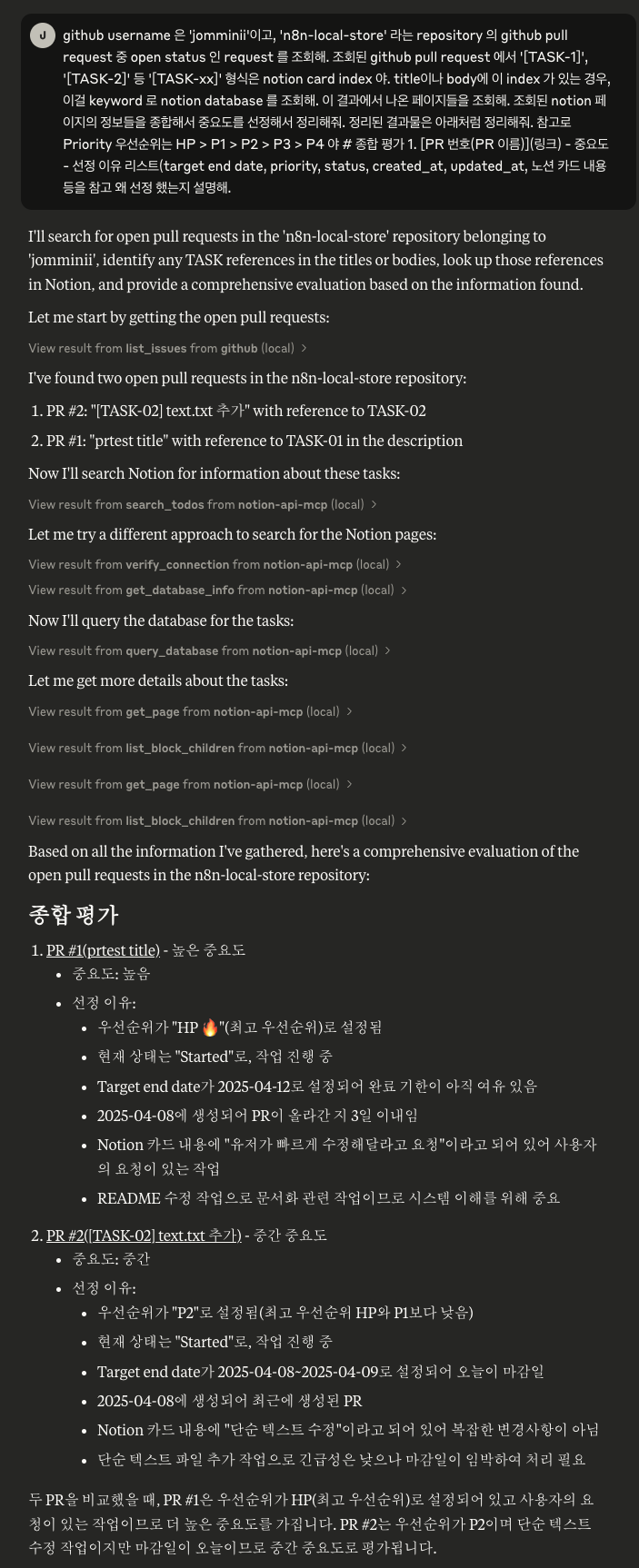
# 종합 평가
1. PR #1 ([TASK-01] README 수정)
- 중요도: HP (최상위)
- 선정 이유:
- 최상위 우선순위 (HP 🔥)
- 유저의 빠른 수정 요청
- 목표 날짜: 2025-04-12
- 현재 상태: Started
2. PR #2 ([TASK-02] text.txt 추가)
- 중요도: P2
- 선정 이유:
- 중간 우선순위 (P2)
- 단순 텍스트 수정
- 목표 날짜: 2025-04-08 ~ 2025-04-09
- 현재 상태: Started
# 우선순위 정리
[TASK-01] README 수정 (HP) - 가장 빠르게 처리 필요
[TASK-02] text.txt 추가 (P2) - 차순위로 처리전체 플로우는 이렇게 된다
어느정도 결과물은 만족스럽게 나온 것 같다.
하지만 이걸 상용에서 쓸 수 있을까? 결과물 자체는 괜찮지만 문제는 비용인데.
일단 n8n 을 로컬에서 셀프 호스팅으로 하고 있기 때문에 호스팅 비용은 들지 않고, zapier 나 make 처럼 플로우, 노드 단위로 비용이 들진 않는다.
하지만 AI Agent 가 사용하는 LLM 요청에는 돈이 들어간다.
위의 캡쳐 이미지에서 보듯 Anthropic Chat Model 은 6번 호출이 되었다. 각각의 chat model 요청은 왜 사용되었냐면,
- 최초 agent 실행 및 깃헙 호출 명령 x 1
- 조회된 깃헙 데이터 기반으로 노션 데이터베이스 조회 x 2
- 조회된 노션 정보로 상세 노션카드 조회 x 2
- 정보 조합하여 답변 생성 x 1
각각의 요청마다 input, output token 이 소모되고, github 에서 조회 된 PR 의 양이 많아 질 수록 x 2 로 요청 수가 늘어나는 구조다. 돈이 줄줄 새고 있다.
그럼 얼마를 쓰고 있는걸까. 로그를 보면 오른쪽 상단에 소모되었다는 토큰이 표시는 된다.
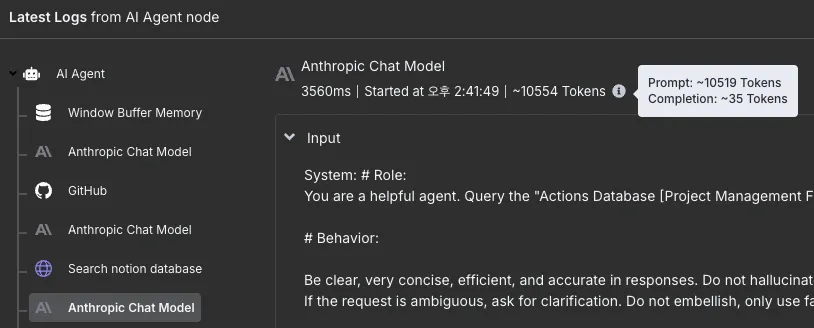
하지만 Anthropic 콘솔의 Logs를 들어가면 이보다 더 많은 토큰들을 소모된 걸 알 수 있다.
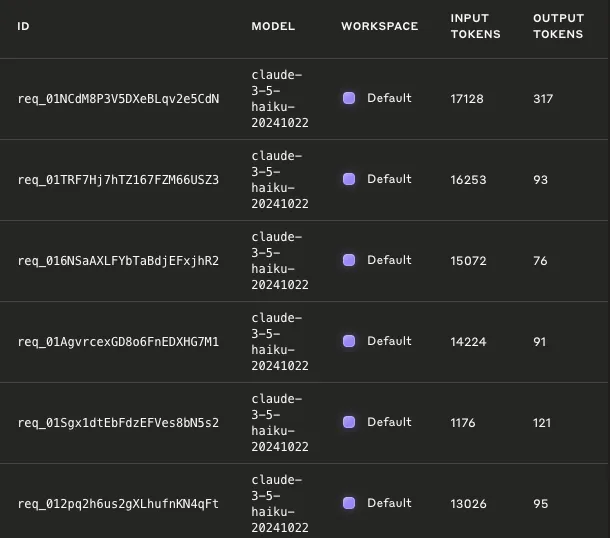
콘솔 로그를 기준으로 보면, INPUT : 76,879 tokens / OUTPUT : 793 tokens 를 사용하고 있다.
api pricing에서 가격을 따져보자.

3.5 haiku 모델은 위의 가격표를 가지고 있고, 계산해보면 INPUT 은 약 92원, OUTPUT은 약 4.7원. 총 96원이 든다. (환율 1,500원/1$ 적용)
PR이 2개 뿐인데도 이정도 드는데, 더 늘어나면, 아무리 사람의 손을 줄인다지만 재무팀 호출을 받을 수 있게 된다.
개선 방법을 한 번 생각해 보자.
# 비용 개선
## chat model 에 전달되는 input 정보 가공 / chat model 이 안해도 되는 행동 플로우 변경
### github response 중 필요한 데이터만 추출
input 데이터를 보면, github repository 를 조회한 데이터 중에 쓸데없는 데이터가 너무나 많고, 이 데이터가 모든 이후 요청에서 input 으로 사용되고 있어 덩치가 커지고 있다. (velog 는 토글이 안되서 보여주기 애매하여 생략)
그리고 github pr request 는 굳이 chat model 이 하지 않아도 될 것 같다. 이전 플로우에서 미리 조회를 해 놓고, 이 정보를 agent 에 전달하면 될 것 같다.
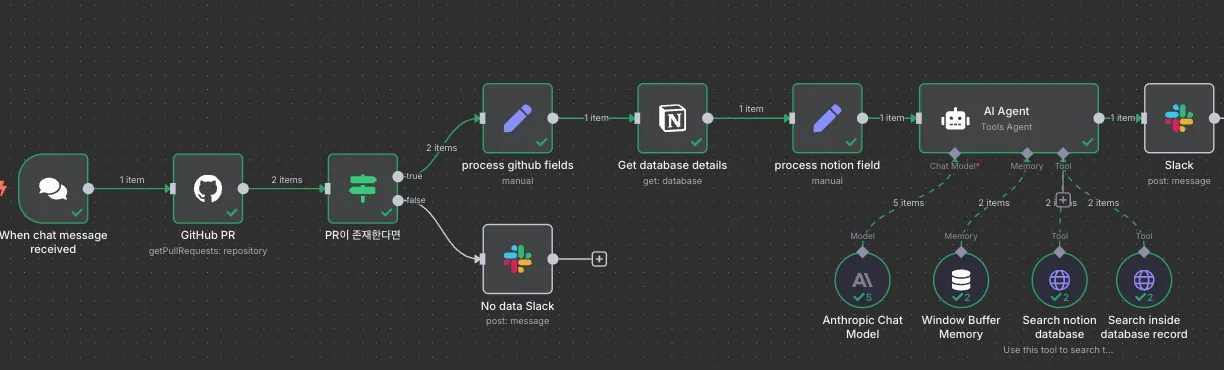
github pr 조회를 앞쪽으로 옮기고, 존재 여부에 따라 분기처리를 추가했다.
데이터가 있는 경우 필요한 데이터만 가공하는 로직을 추가했다.
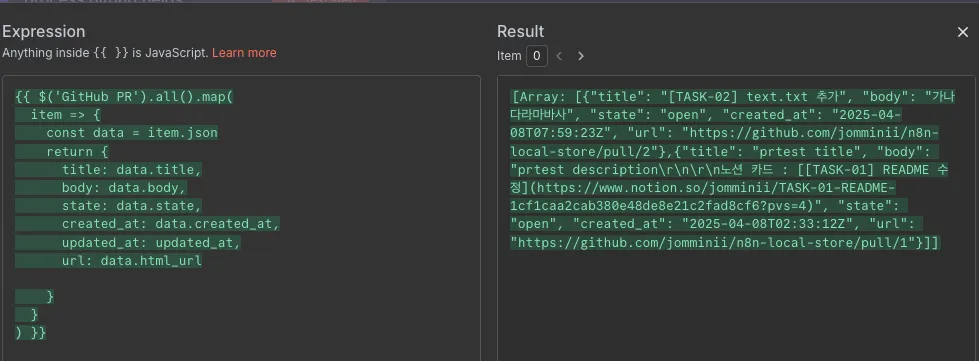
그 결과 토큰 사용량이 확연하게 줄었다.
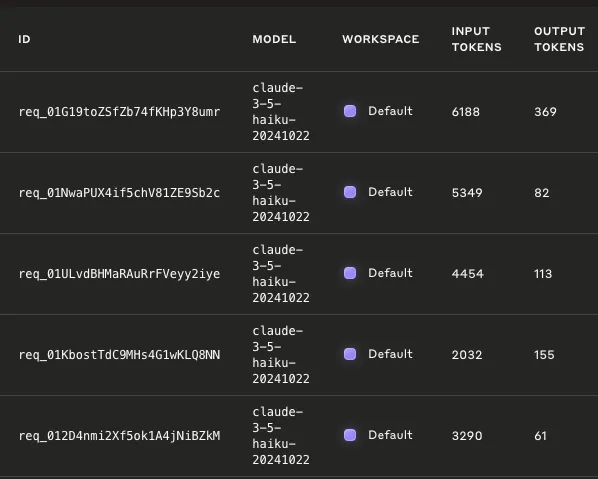
| 변경 전 | 변경 후 | |
|---|---|---|
| input token | 76,879 | 21,313 |
| output token | 793 | 780 |
| 비용 | 96원 | 30원 |
대충 70% 정도 비용 절감이 되었다.
### agent 가 사용하는 notion tool의 response 가공
- 데이터베이스에서 쿼리를 하는 첫 번째 노드의 response
{ "object": "list", "results": [ { "object": "page", "id": "1cf1caa2-cab3-8071-8991-ed73ad4fd7fa", "created_time": "2025-04-08T05:34:00.000Z", "last_edited_time": "2025-04-08T08:47:00.000Z", "created_by": { "object": "user", "id": "0466e15e-0ba3-47d0-a84f-29f0787320c3" }, "last_edited_by": { "object": "user", "id": "0466e15e-0ba3-47d0-a84f-29f0787320c3" }, "cover": null, "icon": null, "parent": { "type": "database_id", "database_id": "ec5bff7d-6cd2-4479-a1f0-025b601a1556" }, "archived": false, "in_trash": false, "properties": { "Priority": { "id": "%3CBoT", "type": "select", "select": { "id": "b21eef27-f6e2-480b-85a2-4a55c5805622", "name": "P2", "color": "yellow" } }, "Completed Date": { "id": "%3CL%5BX", "type": "date", "date": null }, xxx } - 특정 페이지를 조회하는 두 번째 노드의 response
[ { "object": "block", "id": "1cf1caa2-cab3-8040-a56d-d74be44e8e90", "parent": { "type": "page_id", "page_id": "1cf1caa2-cab3-8071-8991-ed73ad4fd7fa" }, "created_time": "2025-04-08T08:39:00.000Z", "last_edited_time": "2025-04-08T08:39:00.000Z", "created_by": { "object": "user", "id": "0466e15e-0ba3-47d0-a84f-29f0787320c3" }, "last_edited_by": { "object": "user", "id": "0466e15e-0ba3-47d0-a84f-29f0787320c3" }, "has_children": false, "archived": false, "in_trash": false, "type": "paragraph", "paragraph": { "rich_text": [ { "type": "text", "text": { "content": "단순 텍스트 수정", "link": null }, "annotations": { "bold": false, "italic": false, "strikethrough": false, "underline": false, "code": false, "color": "default" }, "plain_text": "단순 텍스트 수정", "href": null } ], "color": "default" } }, xxx ]
노션 노드에서 반환한 response 도 모두 agent 가 사용하면서 input 이 비대해지고 있었다.
실제 필요한 정보는 해당 카드의 생성일, 상태, 제목, 내용 정도기 때문에 이를 추출해서 사용하면 input 을 줄일 수 있을 것 같다.
다행히 http request 노드에서는 response 를 가공하는 옵션을 제공한다.
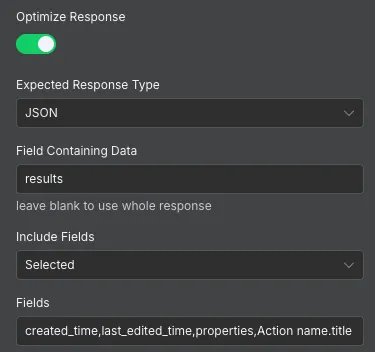
Optimize Response 옵션을 통해 response 에서 추출하고 싶은 필드들을 설정할 수 있고, 이것들만 추출해서 agent 에게 전달한다.
| 변경 전 | 변경 후 | |
|---|---|---|
| input token | 21,313 | 20,963 |
| output token | 780 | 809 |
| 비용 | 30.25원 | 30원 |
조금 줄긴 했네.
### 새로고침?
계속해서 앞 노드에서 가공한 github data 를 최초 메시지에서 조회하지 못하는 현상이 있었는데, 창을 나갔다가 다시 돌아오니 정상 작동하였다. 이로인해 불필요한 input 이 줄게 되었고 좀 더 개선이 일어났다.
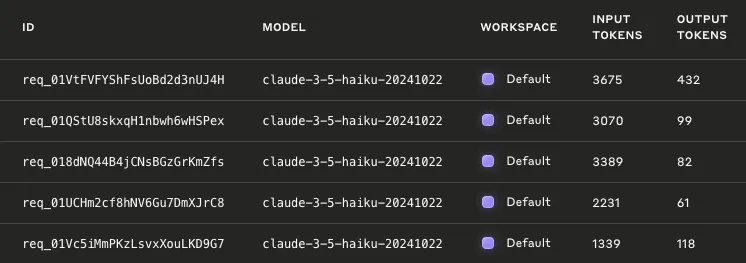
| 변경 전 | 변경 후 | |
|---|---|---|
| input token | 20,963 | 13,704 |
| output token | 809 | 792 |
| 비용 | 30원 | 21원 |
# 결과물
슬랙에는 이렇게 알림이 오게 된다.

최초에 비해 비용도 78% 줄었다.
| 변경 전 | 변경 후 | |
|---|---|---|
| input token | 76,879 | 13,704 |
| output token | 793 | 792 |
| 비용 | 96원 | 21원 |
# 결론
사용법만 좀 익힌다면 보다 복잡한 워크플로우도 손쉽게 구성해서 자동화 할 수 있을 것 같다. 이전에는 이러한 연동들은 개발자들이 직접 코드를 짜야 할 수 있었던 것이었다면, 이제는 드래그앤 드랍만 하고, 일부 설정만 적용하면 동일한 결과물을 가져올 수 있게 되었다.
특히나 플로우도 마다 비용을 내지 않아도 되는 n8n 을 사용한다면 비용도 적게 들고, 만들기도 쉬워지는.. 뭐 이런 선순환이 생긴다.
다만 보다 복잡한 로직을 적용하는데 한계가 있는건 사실이고, agent가 chat model 을 가져다 쓰는 부분도 아직은 과하게 가져다 써서 비용이 더 발생하는게 보인다. 분기를 더 나눈다거나 하는 식으로 더 최적화는 할 수 있지만, 아무래도 코드 단에서 하는게 아직까지는 더 효율적이 될거 같긴 하다.
하지만 모듈을 더 많이 갖다 써야하고, 코드 단에는 그 기능들이 구현되어있지 않다면, n8n 을 쓰는게 훨씬 빠르게 반영하는 선택이 될 것 같다.
# 번외 - MCP로 해보기
claude 에 github과 notion MCP 를 붙이고, 비슷한 명령어를 주니 동일한 동작을 바로 수행하네요, ChatGPT 처럼 scheduled task 개념이 적용되면 n8n 에 구현한 것처럼 자동화 툴로 사용할 수도 있겠어요, 구현 시간이 훨씬 줄어드네요.
요금제에 포함된거니 추가 비용도 들지 않고요!