이번에 사내 PMS(빌딩플러스) 시스템을 개발하면서 정산 로직의 자동 납부 기능을 개발하게 되었다. 그런데 쿼리의 복잡도에 비해 기능이 느리게 작동한다는 생각을 하게 되었고 개선해 볼 여지가 있는지 확인해 보고 싶었다.
요 며칠 프로파일링에 대해 알아보고 있었고, 이 지식을 이용해서 한 번 들여다 보면 좋을 것 같았다.
# 프로파일링을 통한 문제 탐색
먼저 pyinstrument 를 통해 프로파일링 해봤다.
pyinstrument 는 python3.8 이상을 지원하는 프로파일링 도구다. 비동기에 대한 프로파일링이 가능하다.
github repo
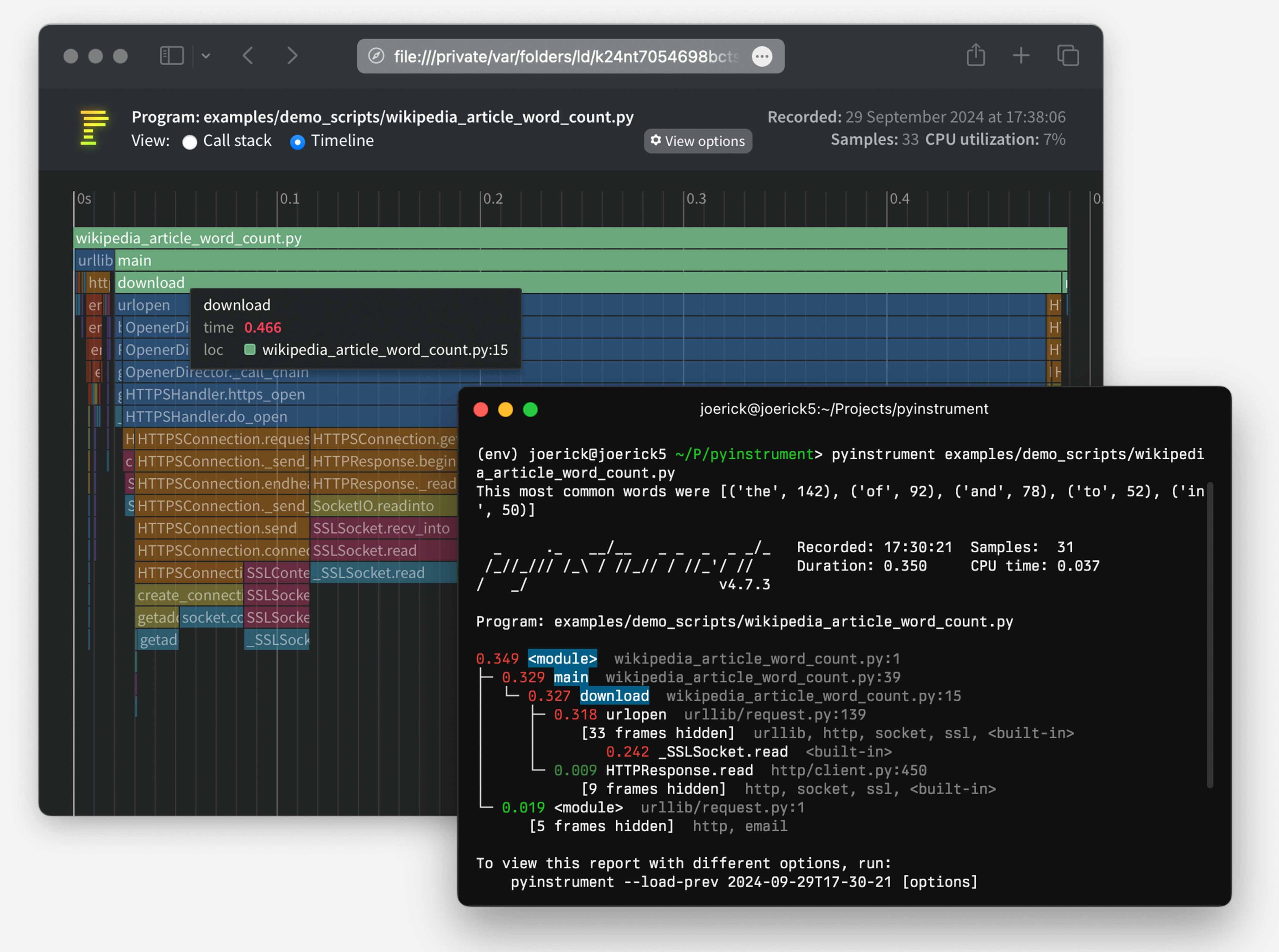
pyinstrument 를 설치하고, 미들웨어로 만들어준다.
# pyinstrument 설치
pip install pyinstrumentPyinstrument 미들웨어는 request 에 대한 프로파일 결과를 뽑아내기위한 역할을 한다. 결과물은 profile.html 에 저장해준다.
from pyinstrument import Profiler
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
from starlette.requests import Request
from starlette.responses import Response
class PyInstrumentMiddleWare(BaseHTTPMiddleware):
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
profiler = Profiler(interval=0.001, async_mode="enabled")
profiler.start()
response = await call_next(request)
profiler.stop()
# Write result to html file
profiler.write_html("profile.html")
return response그리고 애플리케이션 구동 시 미들웨어로 붙여준다.
...
application.add_middleware(
PyInstrumentMiddleWare,
)
...
이제 하나의 요청이 끝날 때마다 프로파일링 된 파일을 확인할 수 있다.
요청을 한 번 해보고 결과를 보자.
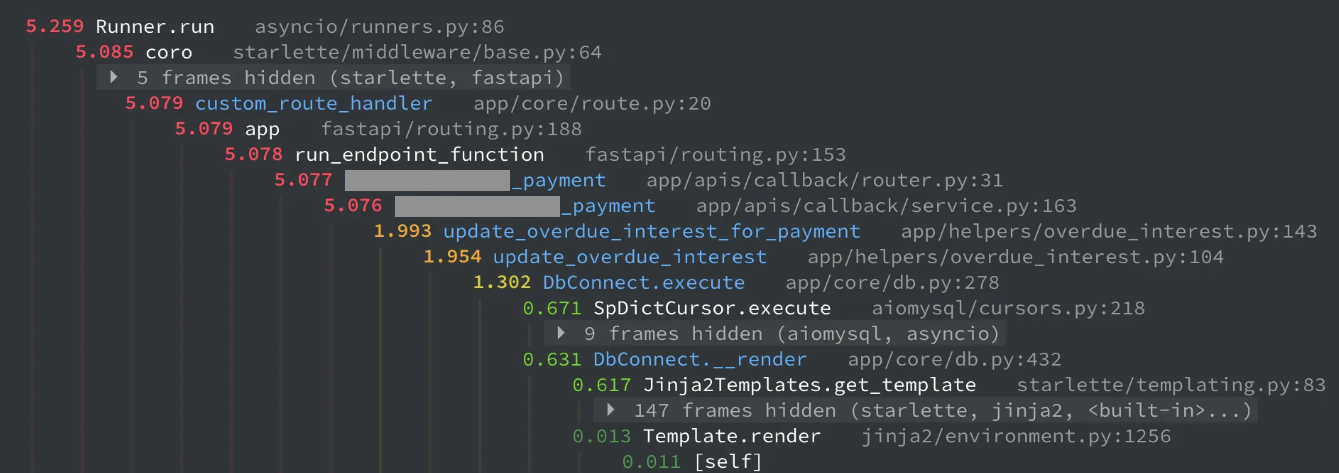
가상계좌 연동 후 자동납부 요청에 대한 전체 로직 실행 시간이 5.2초가 걸렸다. 자동 납부 대상이 되는 여러 수납 건이 존재할 수 있고, 각각에 대한 연체이자가 쌓였을 경우 날마다 처리되어야하는 로직의 양이 많아질 수 있다.
그렇긴 해도 실행시간이 좀 느린 감이 있다. 결과를 보고 개선할 여지가 있는 부분을 찾아보자.
내 경우에 눈에 띄었던 부분은 DbConnect.__render 부분이었다. 쿼리 실행부인 .execute 와 거의 1:1의 시간으로 실행되고 있었다. 렌던데..? 이래도 되나..?
라고 처음에 생각 했으나, 애초에 하나하나의 쿼리나 렌더는 매우 빠르기에 실행 시점에 따라 달라져 별로 의미 없는 추론이었다.
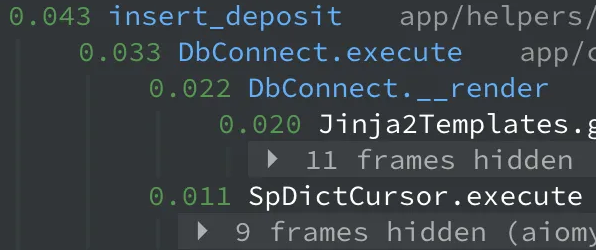
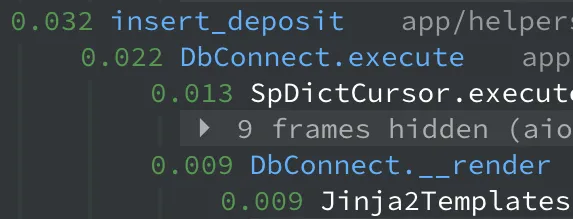
# 문제 해결 방안
방안 1. 템플릿 인스턴스 싱글톤
다만 위의 문제로 보이는 부분은 이자 관련 쿼리가 수십개가 실행된게 묶여서 통계적으로 나타내진 부분이었고, 그래도 뭔가 개선해 볼 부분이 있을지 확인해봤다.
각각의 쿼리는 execute, select_one 과 같은 메서드 내에서 __render 를 호출해 sql 파일을 렌더링하고 있다.
class DbConnect:
...
async def execute(self, **kwargs) -> int|None:
try:
async with self.__get_cursor() as cursor:
...
sql = self.__render(q_id, param)
affected_rows = await cursor.execute(sql, param)
...
def __render(self, q_id, param={}) -> str:
""" 쿼리 파일 렌더링 """
sql_path = str.replace(q_id, '.', '/')+'.sql'
models = Jinja2Templates(directory='app/sql', autoescape=False)
template = models.get_template(sql_path)모든 쿼리에서 __render 를 각각 호출하기 때문에, 여기에서 중복을 줄일 수 있으면 속도가 조금 개선될 것 같다. 코드를 보니 Jinja2Templates 인스턴스를 생성하는 부분이 보인다. 내부 코드를 한 번 보자.
# starlette > templating.py
class Jinja2Templates:
"""
templates = Jinja2Templates("templates")
return templates.TemplateResponse("index.html", {"request": request})
"""
def __init__(
self, directory: typing.Union[str, PathLike], **env_options: typing.Any
) -> None:
assert jinja2 is not None, "jinja2 must be installed to use Jinja2Templates"
self.env = self._create_env(directory, **env_options)
def _create_env(
self, directory: typing.Union[str, PathLike], **env_options: typing.Any
) -> "jinja2.Environment":
@pass_context
def url_for(context: dict, name: str, **path_params: typing.Any) -> str:
request = context["request"]
return request.url_for(name, **path_params)
loader = jinja2.FileSystemLoader(directory)
env_options.setdefault("loader", loader)
env_options.setdefault("autoescape", True)
env = jinja2.Environment(**env_options)
env.globals["url_for"] = url_for
return env
코드를 보니 인스턴스를 생성할 때 파일시스템을 로드하고, 환경도 설정하고 있다. 코드만 봐도 부하가 좀 있을것처럼 보인다.
다시 __render 코드를 보면, 실제로 각각의 쿼리마다 sql_path 로 차별성을 가지는 부분은 model.get_template(sql_path) 부분 부터인 걸 알 수 있다. 이 부분에서 path 를 기준으로 파일을 찾아서 쿼리를 꺼내준다.
그렇다면, Jinja2Templates 부분을 application 이 실행될 때 한 번 만들어두고 쓰면 부하를 줄일 수 있을 것 같다.
# main.py
from starlette.templating import Jinja2Templates
# Jinja2Templates 인스턴스를 애플리케이션 상태로 저장
application.state.template_env = Jinja2Templates(
directory='app/sql',
autoescape=False
)Fastapi app 을 생성할 때, application의 state(상태)에 인스턴스를 만들어 저장한다. application.state 는 Fastapi 서버가 떠 있는 라이프사이클 내내 유지되는 상태 저장소이다. request 를 받은 후에도 request.app.state 로 접근 가능하다.
그리고 __render 도 수정하자.
def __render(self, q_id, param={}) -> str:
sql_path = str.replace(q_id, '.', '/') + '.sql'
# models = Jinja2Templates(directory='app/sql', autoescape=False)
# template = models.get_template(sql_path)
template = self._request.app.state.template_env.get_template(sql_path)기존에는 템플릿 인스턴스를 각각 생성해서 썼다면, 이제는 한 번 생성한 인스턴스(싱글톤이라고 볼 수 있겠다)를 활용해서 템플릿을 로드할 수 있다.
개선이 됐는지 다시 한 번 실행해보자.
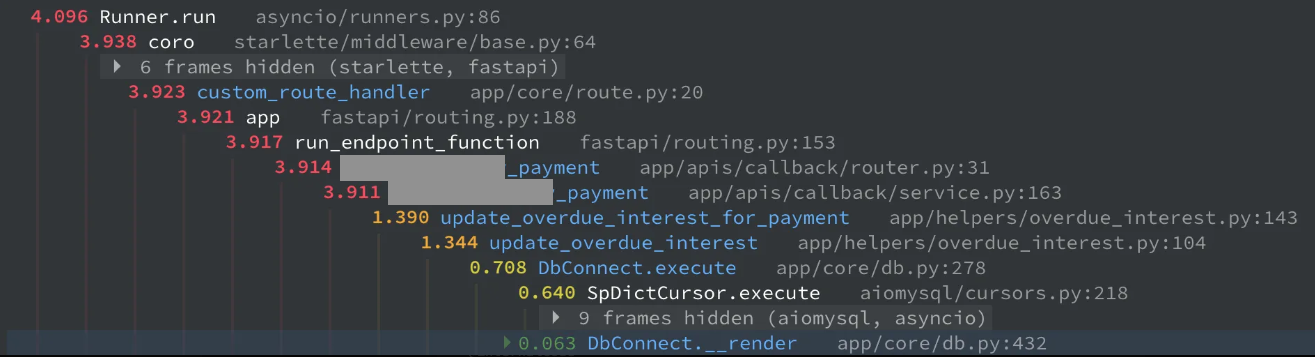
기존에 0.63초 정도 걸리던 DbConnect.__render 로직이 0.063초로 약 90% 빨라졌다. execute 와의 비율도 1:1에서 1/10 정도가 되었다!
전체 실행 시간도 5.2초 → 4.1초로 약 21% 빨라졌다.
위의 효과 외에도 한 가지 더 효과를 얻은 부분이 있는데, 템플릿 캐싱 효과다.
Jinja2Template 은 원래 템플릿 로드 기능에 LRU cache 기능을 제공하고 있다.
# jinja2 > environment.py
@internalcode
def _load_template(
self, name: str, globals: t.Optional[t.Mapping[str, t.Any]]
) -> "Template":
if self.loader is None:
raise TypeError("no loader for this environment specified")
cache_key = (weakref.ref(self.loader), name)
if self.cache is not None:
template = self.cache.get(cache_key)
if template is not None and (
not self.auto_reload or template.is_up_to_date
):
# template.globals is a ChainMap, modifying it will only
# affect the template, not the environment globals.
if globals:
template.globals.update(globals)
return template
template = self.loader.load(self, name, self.make_globals(globals))
if self.cache is not None:
self.cache[cache_key] = template
return templatedefault 로 400개의 한도로 가진 LRU 캐시를 제공하고 있는데, 기존에 우리는 매 쿼리 실행마다 인스턴스를 새로 생성해서 캐시 기능을 사용할 수 없었다. 하지만 이번에 기능을 수정하면서 하나의 인스턴스를 공용으로 쓰게 되었고, 이로 인해 같은 캐시 영역을 사용할 수 있게 되었다.
그럼 어떤 효과가 있었는지 line_profiler 를 통해 확인해보자. 참고로 line_profiler 는 라인별로 실행 횟수, 실행시간 등을 표현해주긴 하지만, 내부 호출까진 추적하지 않아 여기서 표현된 값이 정확한 수치는 아니라는걸 인지해야한다.
아래 결과를 보면, 동일한 로직을 실행할 당시의 __render 를 라인별로 프로파일링 한 수치를 볼 수 있다.
448 라인을 보면, 최초 시도에는 메서드 내에서 82.5%의 실행 시간을 차지했지만, 두 번째 시도에서는 캐싱된 템플릿을 사용하여 30.7%의 실행 시간을 차지하는걸 볼 수 있다. 단위가 워낙 작아 효과가 미미하긴 하지만, 쿼리 파일이 커지거나, 로직에 사용되는 쿼리의 수가 많아지면 충분히 유의미한 효과를 낼 수 있을 것 같다.
common.settlement.deposit.insert_deposit_item
Timer unit: 1e-09 s
Total time: 0.000914 s
File: .../app/core/db.py
Function: __render at line 440
Line # Hits Time Per Hit % Time Line Contents
==============================================================
440 def __render(self, q_id, param={}) -> str:
441 """ 쿼리 파일 랜더링
442
443 - jinja2 Template 파싱 후 빌드된 쿼리 문자열 반환
444 - debug 사용 시 빌드된 쿼리내용 콘솔 출력
445 """
446
447 1 3000.0 3000.0 0.3 sql_path = str.replace(q_id, '.', '/') + '.sql'
448 1 754000.0 754000.0 82.5 template = self._request.app.state.template_env.get_template(sql_path)
449
450 1 101000.0 101000.0 11.1 new_param = copy.deepcopy(param)
451 ...
463 1 1000.0 1000.0 0.1 return sql
common.settlement.deposit.insert_deposit_item
Timer unit: 1e-09 s
Total time: 0.000179 s
File: .../app/core/db.py
Function: __render at line 440
Line # Hits Time Per Hit % Time Line Contents
==============================================================
440 def __render(self, q_id, param={}) -> str:
441 """ 쿼리 파일 랜더링
442
443 - jinja2 Template 파싱 후 빌드된 쿼리 문자열 반환
444 - debug 사용 시 빌드된 쿼리내용 콘솔 출력
445 """
446
447 1 2000.0 2000.0 1.1 sql_path = str.replace(q_id, '.', '/') + '.sql'
448 1 55000.0 55000.0 30.7 template = self._request.app.state.template_env.get_template(sql_path)
449
450 1 53000.0 53000.0 29.6 new_param = copy.deepcopy(param)
451 ...
463 1 0.0 0.0 0.0 return sql참고로 line_profiler 는 다음처럼 적용해서 뽑아볼 수 있다.
async def execute(self, **kwargs) -> int|None:
try:
from line_profiler import LineProfiler
async with self.__get_cursor() as cursor:
profiler = LineProfiler()
profiler.add_function(self.__render)
profiler.enable()
...
sql = self.__render(q_id, param)
profiler.disable()
print(q_id)
profiler.print_stats()
affected_rows = await cursor.execute(sql, param)
...
return affected_rows
...### thread safe
이 방안은 thread safe 하지는 않다. 하나의 인스턴스를 생성해서 공용으로 쓰기 있기 때문이다. 하지만 현재 코드 내에서 명시적으로 멀티스레드를 사용하는 부분이 없고, fastapi 에서도 비동기 요청을 처리할 때 기본적으로 단일 스레드로 처리하기에 문제가 발생하진 않을 것 같다. (스레드 경합이 생긴다면, 캐시 생성 시 경합이 생길 수 있다)
만약 thread safe 하게 코드를 수정한다면, 아래처럼 lock 을 명시적으로 주어 할 수 있다.
import threading
...
lock = threading.Lock()
...
def __render(self, q_id, param={}) -> str:
sql_path = str.replace(q_id, '.', '/') + '.sql'
lock = threading.Lock()
with lock:
template = self._request.app.state.template_env.get_template(sql_path)
방안 2. 서버 띄울 때 템플릿도 모두 미리 로드
사실 이 방법을 먼저 생각하고 적용해보긴 했다.
모든 SQL 쿼리에 대한 템플릿을 미리 로드해서 캐싱해놓고, 필요할 때마다 꺼내쓰는 방식이다.
먼저 대상이 되는 쿼리 파일이 얼마나 되나 파악해봤다. 현재 기준 쿼리 파일은 총 850개이고, 전체 용량은 1MB 정도 되었다.
템플릿으로 모두 로드했을 경우에 얼마나 차지하는지는 뒤에서 확인해보자. 일단 얼마가 되든 현재 dev 환경의 2GB RAM 이나 prod 환경의 8GB RAM 에는 충분히 여유가 있을 것 같다.
각각의 EC2 인스턴스의 메모리 사용량도 확인해보니, prod의 경우 최대치로 사용한 경우가 약 25% 였고, dev 환경도 50% 정도였다.
그래서 어떻게 할거냐.
최초 서버 구동 시 모든 쿼리를 읽고, 템플릿으로 로드해서 [방안 1. 템플릿 인스턴스 싱글톤] 처럼 application.state 에 담아놓고 사용하려고 한다.
먼저 모든 쿼리를 읽고 템플릿으로 로드하는 코드를 작성한다.
from jinja2 import Template
def load_sql_queries(sql_dir: str = 'app/sql') -> dict:
"""
SQL 디렉토리의 모든 .sql 파일을 로드하여 캐시로 저장
Returns:
dict: {query_id: Template} 형태의 캐시
"""
sql_cache = {}
sql_path = Path(sql_dir)
for sql_file in sql_path.rglob('*.sql'):
# 상대 경로를 query_id로 변환 (예: common/user/get_user.sql -> common.user.get_user)
relative_path = sql_file.relative_to(sql_path)
query_id = str(relative_path.with_suffix('')).replace('/', '.')
# SQL 파일 내용 읽기
with open(sql_file, 'r', encoding='utf-8') as f:
template_str = f.read()
# Jinja2 템플릿 컴파일
sql_cache[query_id] = Template(template_str, autoescape=False)
return sql_cache이전에 사용했던 Jinja2Template 은 경로를 주면 파일까지 찾아 들어가서 로드를 해주는 역할을 했지만, 이번에는 그런 수고를 덜어주었다.
app/sql 하의 모든 sql 쿼리 경로를 한 번에 가져오고, 이 경로를 돌면서 파일을 읽고 Template 을 통해 템플릿을 생성한다. 이전처럼 인스턴스도 필요없고, get_template 역할을 하는 Template 으로 로드한다.
그리고 캐시 역할을 해줄 딕셔너리에 담아준다.
main.py 의 애플리케이션 생성 부에서 위 메서드를 실행하고 state 에 캐싱한 템플릿들을 담아준다.
# main.py
application.state.sql_cache = load_sql_queries()마지막으로 __render 메서드를 수정해준다.
캐싱 템플릿을 저장한 state 에서 템플릿을 조회해서 쓰고, 마안약에 없다면, 기존 방식으로 로드를 해준다.
def __render(self, q_id, param={}) -> str:
# 캐시에서 템플릿 조회
template = self._request.app.state.sql_cache.get(q_id)
if template is None:
# 캐시 미스: 파일에서 직접 로드
sql_path = str.replace(q_id, '.', '/') + '.sql'
models = Jinja2Templates(directory='app/sql', autoescape=False)
template = models.get_template(sql_path)
# 캐시에 저장
self._request.app.state.sql_cache[q_id] = template이제 실행 결과를 한 번 살펴보자.
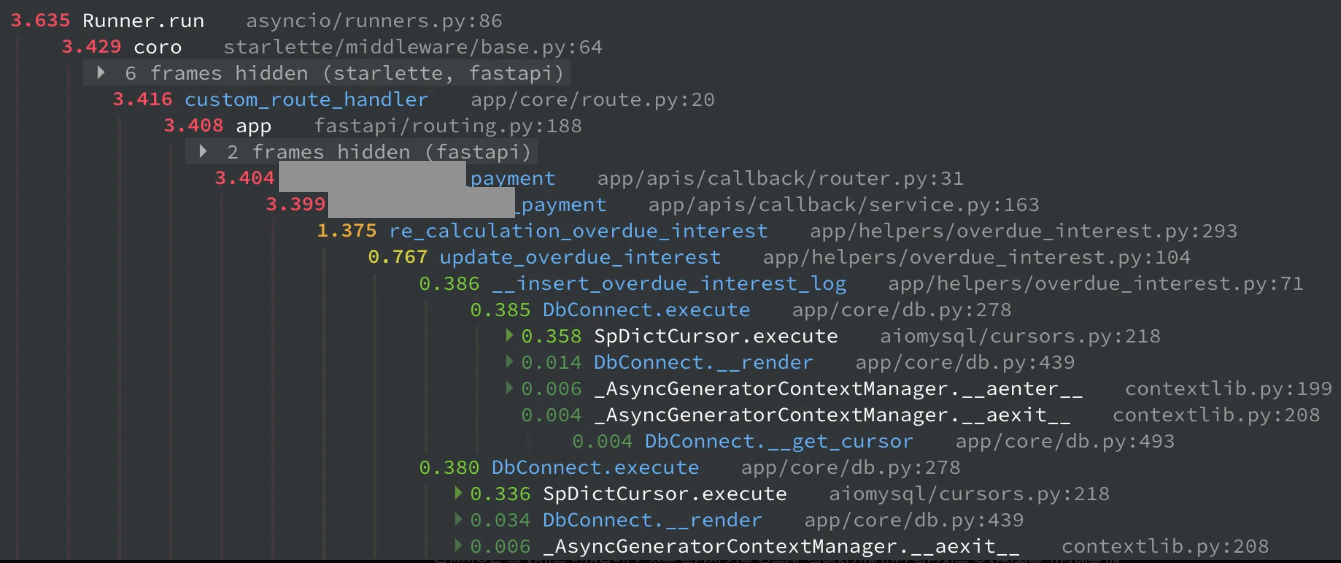
결과적으로 큰 차이는 없어보인다. 조금 빨라진 것도 같은데, 실행시기에 따라 달라지는 오차범위를 고려했을 때 유의미한 차이는 없었다.
### 추가 고려사항
그럼 이 방법을 적용한다면 어떤걸 더 고려해야할까?
- 로드 시간
일단 모든 sql 파일을 읽고 템플릿으로 로드하는 시간을 확인해야한다. 측정해보니 m1 air 로컬 기준 0.84초가 걸린다. prod 환경과 단순비교를 했을 때, m1 air 가 좀 더 빠른걸로 봐서, prod 에서는 1초 정도 걸릴 것으로 예상된다.
- 메모리 사용량
로드된 템플릿을 모두 메모리에 올려놔야하므로, 메모리 사용량도 확인해 봐야 한다.
측정해보니 각각의 파일은 4KB 정도의 메모리를 사용하고 있고, 전체 사용량은 3.4MB 정도 나온다.
위에서 클라우드워치로 확인한 EC2 인스턴스 사용량에서 prod 는 2GB 를 최대로 사용하고, 6GB 가 여유가 있기에, 이정도는 무리를 주지 않을 것 같다.
def load_sql_queries(sql_dir: str = 'app/sql') -> dict:
"""
SQL 디렉토리의 모든 .sql 파일을 로드하여 캐시로 저장
Returns:
dict: {query_id: Template} 형태의 캐시
"""
sql_cache = {}
sql_path = Path(sql_dir)
total_size = 0
template_sizes = {}
for sql_file in sql_path.rglob('*.sql'):
relative_path = sql_file.relative_to(sql_path)
query_id = str(relative_path.with_suffix('')).replace('/', '.')
with open(sql_file, 'r', encoding='utf-8') as f:
template_str = f.read()
template = Template(template_str, autoescape=False)
sql_cache[query_id] = template
# 각 템플릿의 메모리 사용량 측정
template_size = objsize.get_deep_size(template)
template_sizes[query_id] = template_size
total_size += template_size
# 메모리 사용량 출력
print("\n=== SQL Template Cache Memory Usage ===")
print(f"Total cached templates: {len(sql_cache)}")
print(f"Total cache size: {total_size / (1024*1024):.2f} MB ({total_size / 1024:.2f} KB)")
print("\nTemplate sizes:")
for query_id, size in template_sizes.items():
print(f"- {query_id}: {size / 1024:.2f} KB")
print("=====================================\n")
return sql_cache# 각각의 쿼리 템플릿이 사용하는 메모리 양
- common.history.select_change_history_count: 4.08 KB
- common.history.insert_change_history: 4.09 KB
- common.history.select_access_log_count: 4.08 KB
- common.history.select_change_history_list: 4.09 KB
- common.history.insert_permission_group_log: 4.08 KB
- common.history.insert_access_log: 4.08 KB- 로컬 개발 시 쿼리 파일의 수정이 반영되는가
로컬에서는 uvicorn 을 통해 reload 옵션으로 파이썬 코드 수정 시 서버가 재시작 되게 하고 있다. 하지만 sql 파일은 여기서 빠져있어서, 서버 시작 시 쿼리 파일을 모두 로드하는데에 바로 반영되지 않을 수 있다. 이 부분은 uvicorn 의 reload-include 옵션을 통해 해결할 수 있다.
아래 옵션을 추가하면, sql 수정 시에도 서버가 재시작되게 하여 수정된 템플릿이 바로 반영되게 할 수 있다.
uvicorn app.main:app --reload --reload-include "*.sql"다만 sql 파일의 수정까지 바라보고 있으면 개발 중 서버 재시작이 빈번해져, 로컬 환경에서는 캐싱을 하지 않도록 반영해두었다.
# 결론
그럼 두 방안 중 어떤 것을 선택해야할까?
내 생각엔 서버를 띄울 때 템플릿을 모두 로드하는 방식인 방안 2가 좋을 것 같다.
우선 쿼리 파일의 경우 새로 배포를 할 때만 변동이 있기에 동적으로 반영되는 경우는 없다.
그리고 쿼리의 수도 현재 시스템은 많은 기능이 개발되어 있기에 지금의 850개 보다 기하급수적으로 더 늘어날 가능성은 적어보인다.
반면 템플릿 인스턴스를 싱글톤으로 만들어 사용하는 방법은 얻는 효용에 비해서 코드가 오버스펙으로 가는 것 같다. LRU cache 수를 1000개 정도로 늘려서 사용한다해도, 방안 2와 유사해지고, 애초에 방안 2는 현재 캐싱 되어있는지 확인하고 새로 캐싱하는 로직도 필요 없이 꺼내 쓰기만 하면 된다.
스레드 안정성을 고려한다면 threading lock 까지 추가로 넣어야한다.
그렇기에 각 EC2 인스턴스당 6MB(3MB x worker 수) 정도를 사용하기만 하면 되는 방안 2가 좋을 것 같다.
