
앙상블(Ensemble)은 분류(Classification)를 위한 ML 모델을 만들 때 여러 개의 작은 모델들을 만들고 이들을 더해서 성능을 높이는 방법을 말한다. 하나의 크고 좋은 모델을 만들면 되는데 왜 굳이 여러 개의 모델을 동시에 사용하는지? 그리고 어떤 방법들이 있을지에 대해서 메모해둔다.
오버피팅을 방지하거나 언더피팅을 방지하거나
분류 문제를 풀기 위해 Decision Tree를 하나 학습시켰다고 생각해보자. 머신러닝 모델의 영원한 숙제인 Overfitting이 발생하는 경우가 있을 것이고, 혹시 데이터의 양이 부족하거나 알고리즘이 적합하지 않다면 트레이닝 데이터에도 Underfitting 될 수도 있다.
아래는 분류 문제에서 너무 과하게 트레이닝 데이터를 나누고 있는 오버피팅 모델과, 2차원 선의 회귀라인이 적절한 문제에서 직선의 회귀라인을 도출하고 있는 언더피팅 모델의 그림이다.
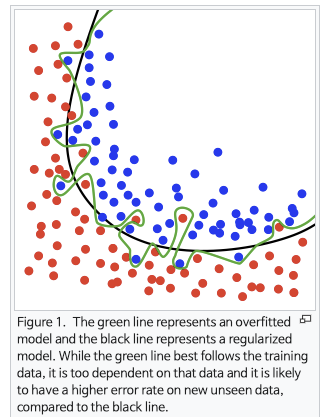
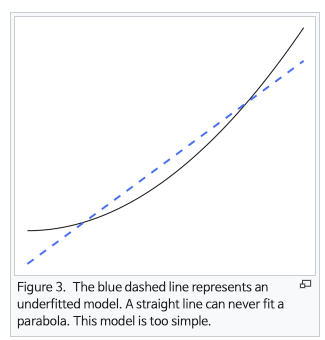
이 두 가지 상황 모두 여러 모델을 조합함으로서(앙상블) 해결해볼 수 있다.
Bagging
배깅은 Decision Tree 여러 개로 이뤄진 Random Forest를 떠올리면 쉽다. 하나의 Deicison Tree 만을 사용했을 때 트레이닝 데이터에 그 트리가 과적합될 경우 테스트 데이터에서 좋은 성능을 내기가 힘들다. 하지만 여러 개의 트리를 동시에 학습시켜두고 각 트리가 예측한 결과를 잘 조합해서 최종 결과를 낸다면, 과적합된 트리의 비중을 낮출 수 있기 때문에 더 나은 성능을 보일 수 있다.

표 출처: Link
트레이닝 데이터에서 Sampling with replacement를 하고, 분류에 사용할 feature 또한 그때그때 랜덤 샘플링한다. 그래서 각각의 트리를 학습시킨 후에 각 결과물의 평균이나 voting을 사용해서 최종 분류값을 도출하게 된다. Variance를 낮춘다는 말은 하나의 트리 성능에 따라 크게 결과가 좌우되는 걸 방지해줄 수 있다는 걸 뜻한다.
Boosting
부스팅은 말 그대로 성능을 부스트하려는 목적을 갖는다. 단일 모델의 성능이 부족하고, 또는 트레이닝 데이터의 양과 질이 부족할 때 여러 모델들을 활용해서 점점 성능을 올려갈 수 있다. 특히 트레이닝 데이터에도 예측 성능이 잘 나오지 않을 때 (underfitting) 사용한다.

표 출처: Link
특이한 점은 위 테이블의 Partition of data 부분이다. 모델 A로 학습을 진행한 후 다음 모델 B로 추가학습을 진행할 때, 데이터를 랜덤하게 샘플링 하는 게 아니라 A가 틀린 샘플들을 중심으로 뽑아 B가 학습할 수 있게끔 한다. 틀린 문제를 다시 복습해서 A의 부족한 점을 채워줄 수 있도록 구조화하는 것이다. 이 과정을 많이 거치게 됐을 때, 트레이닝 데이터를 너무 잘 학습하게 되는(Overfitting) 문제가 발생할 가능성도 있으니 중간중간 Validation을 해 가면서 적정한 수준을 찾아내는 게 좋다.
Bagging vs Boosting
둘을 비교하는 여러 기준들이 있지만 나는 아래 세 가지 키워드를 중심으로 비교하곤 한다.
- Parallel vs Sequential: Bagging은 동시에 예측한 후 결과물을 combine 하는 반면 Boosting은 하나의 모델이 한번 예측하고 나면 그 결과를 바탕으로 다음 모델이 작동한다. 자연스럽게 학습시간에서 차이가 나게 된다.
- Overfit vs Underfit: 위에서 말한 대로 Bagging은 단일 모델이 너무 학습 데이터에 fit되는 상황에서 사용되며 Boosting은 단일 모델의 성능이 약할 때 사용할 수 있는 방법이다.
- Randomly(Bootstrap) vs Weight: Bagging은 데이터나 feature를 샘플링할 때 무작위로 뽑아낸다. 데이터는 복원추출, feature는 한번 추출할 때는 비복원으로 추출하게 될 것이다. 반면 Boosting은 앞선 모델의 결과를 반영해서 더 좋은 성능을 보여야 하기 때문에 예측이 틀린 케이스를 중심으로 샘플링을 해서 추가 학습을 진행한다. 잘 못하는 학생들을 골라 보충학습을 통해 전체 평균성적을 올려주는 것이다.
