
프로그래머스 튜플 2019 카카오 인턴 코딩테스트
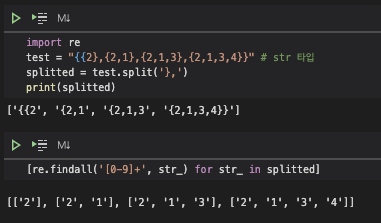
re.findall
re는 Regular Expression의 약자로 str 타입의 데이터를 다루는 데 사용된다. NLP 모델을 위해 데이터 전처리를 할 때 re.sub(문자 찾아서 대체), re.match(위치 찾기) 등이 유용하다.
re.findall은 match되는 부분을 찾아서 추출해준다. 맨 윗처럼 input str이 주어졌을 때, 각각 list로 묶어주기 위해 괄호와 콤마로 split을 해줬다. 그리고 split된 문자들 속에서 숫자 부분들만 뽑아서 하나의 element로 만들어주기 위해 findall을 사용했다. [0-9]는 숫자를 의미하고 +는 앞에 붙은 숫자가 1개 이상 있는 부분을 찾으라는 뜻이다. 예를 들어 두번째 '{2,1'에서는 2와 1이 매칭이 되어서 각각 하나의 인자로 list 형태로 들어갔다. bs4 크롤링을 할 때에도 find_all로 해당 태그들을 모두 찾아 리스트 형태로 만들어주는데, 이와 비슷하다.
dictionary와 list에서의 in
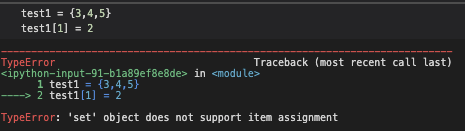
아래처럼 Data에 포함되어 있는지 확인할 때, list는 O(n), dict와 set은 O(1)로 알고 있다. dict와 set은 중복이 허용되지 않고(unique), element들이 각각 고유한 위치를 점유하고 있어서 바로 그 위치를 찾을 수 있다고 이해했다.
if a in data_structure:
print(a)반면 list, tuple과 다르게 element들을 바로 바꿀 수가 없다. list[i] = 3 과 같은 명령이 듣지 않는다.
불편한 점도 있지만 이 덕에 in function 수행 시 O(1)이 소요된다. for나 while loop 안에서 in을 체크해봐야 할 때 가능하다면 꼭 사용해야 하는 것이다.
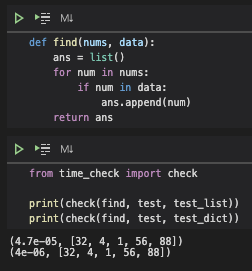
아래 테스트는 5개 숫자를 포함한 1부터 1000까지의 숫자 10005개를 generate한 후 list와 dict에 담아 in function의 구동 시간을 체크한 것이다. 경과 시간의 자리수가 다른 걸로 보면 약 10배 정도 dict가 빨랐다는 것을 알 수 있다.
Question

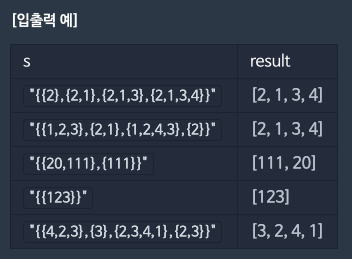
Solution
PSEUDO
- str을 받아서 [[2], [2,1], [2,1,3], [2,1,3,4]]와 같이 list[list[int]] 형태로 만들기
- 길이가 짧은 순서대로 sorted, key=len
- ans = dict() (dictionary로 in function 활용하기 위해)
- for set in list:
if num not in ans: ans[num]=True (하나씩 ans의 key에 추가)
else: pass - return list(ans.keys()) key만 출력
import re
def solution(s):
split_list = s.split('},')
lists = list()
lists.append(re.findall('[0-9]+', split_list[0]))
lists.append(re.findall('[0-9]+', split_list[-1]))
for str_ in split_list[1:-1]:
lists.append(re.findall('[0-9]+', str_))
sort = sorted(lists, key=lambda x: len(x))
ans = dict()
for set1 in sort:
for num in set1:
if num in ans:
continue
ans[int(num)] = True
return list(ans.keys())