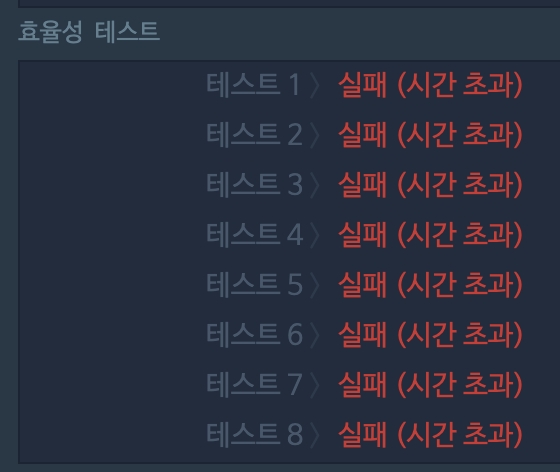
프로그래머스 짝지어 제거하기
Array
우리가 가장 간단하게 사용하는 list는 array 자료 구조를 구현해놓은 것이다. hash table, linked list 등과 비교했을 때 element가 자유롭고 주요 작업(delete, append 등) 코드가 간단하다.
그러나 배열 중간에 원소를 추가/삭제 한다거나 무엇인가를 찾을 때에는 처음부터 O(n)으로 원소를 검색(search)하는 과정이 필요해서 time complexity가 크다. list slicing(list[3:5])을 할 때도 아마 세 번째로 이동을 하고 다섯 번째로 이동을 해서 잘라낼 것이다. 물론 전체 메모리를 변경 (+다른 모든 값들의 위치를 옮김)해줘야 하는 추가/삭제 보다는 간단한 작업이지만 말이다.
노마드 코더의 자료구조 array에 대한 설명 영상
"모든 배열의 값들이 움직여야 해"
따라서 search가 필요한 in function도 O(n)으로 이뤄지게 된다. 이러한 이유로 in function이 필요한 경우엔 hash table 구조를 사용할 수 있을지 항상 먼저 고민해봐야 한다. 이 문제는 답을 맞히기엔 어렵지 않지만 str과 list의 특성과 비효율적인 상황을 파악할 수 있어야만 효율성 테스트까지 통과할 수 있었다.
3 in [9,8,7,3]
3 in {9:True, 8:True, 7:True, 3:True}
# 아래는 3이라는 key로 접근하기 때문에 O(1), 위는 선형탐색이기 때문에 O(n)Quesion

Solution
PSEUDO
- i = 0
- s = '0' + s
- while i < len(s)-1:
if s[i] == s[i+1]:
s를 슬라이싱. (중간 둘 값을 제거하고 나머지를 s로 붙이기)
i -= 1 # 다시 한칸 앞으로 돌아가서 새로 붙은 부분을 판단
continue - len(s)가 1이면 return 1 아니면 0
슬라이싱 부분을 다르게 해보기 위해 s를 str -> List로 변형하여 del을 사용해보기도 했다. Solution1은 str 슬라이싱, 2는 list로 형태를 바꿔서 슬라이싱 대신 del 활용, 3은 stack을 활용(추가 메모리 활용)하여 시간을 빠르게 단축했다. pivonacci 수열 등의 문제에서 저장공간을 사용해서 이미 한번 계산했던 f(x) 값들은 다시 계산하고 가져다 쓸 수 있게 한 것과 유사하다.
결과적으로 셋 모두 옳은 답을 return 했지만 3,2,1 순으로 효율적이었다. 프로그래머스의 효율성 테스트를 1,2는 통과가 어려웠고 3은 통과가 가능했다. 또한 자체 실험에서도 3>2>1 순으로 속도가 빠르다는 것을 알 수 있었다. (실험 결과는 하단에)
추가 저장 메모리 사용> DEL > Slicing 순으로 좋았다.
def solution1(s):
if len(s) == 1: return 0
i = 1
s = '0' + s # 0을 추가해서 s[-1]이 나오는 것을 방지하기 위함
while i < len(s)-1:
if s[i] == s[i+1]: # i == 2
s = s[:i] + s[i+2:]
i -= 1
continue
i += 1
return 1 if len(s)==1 else 0
def solution2(s):
if len(s) == 1: return 0
list_s = [0] + list(s)
i = 1
while i < len(list_s)-1:
if list_s[i] == list_s[i+1]:
del list_s[i]
del list_s[i]
i -= 1
continue
i += 1
return 1 if len(list_s)==1 else 0
def solution3(s):
if len(s) == 1: return 0
stack = list()
for char in s:
if not stack:
stack.append(char)
else:
if stack[-1] == char:
stack.pop()
else:
stack.append(char)
return 1 if not stack else 0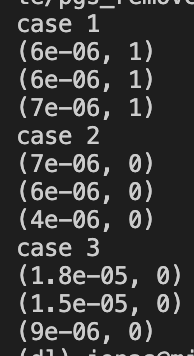 각 케이스에서 모두 세 번째 방법이 빨랐다. 정확성은 모두 통과했지만 세번째가 유일하게 효율성 테스트에서도 통과할 수 있었다. 1,2의 코드는 O(n^2)에 가깝고 3은 O(n)이 되는 것이다.
각 케이스에서 모두 세 번째 방법이 빨랐다. 정확성은 모두 통과했지만 세번째가 유일하게 효율성 테스트에서도 통과할 수 있었다. 1,2의 코드는 O(n^2)에 가깝고 3은 O(n)이 되는 것이다.