Problem
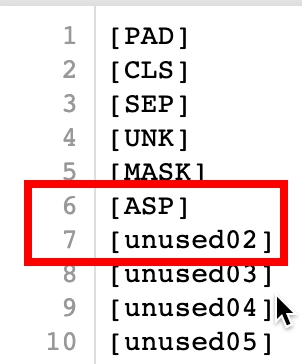
언어 모델 학습 이전에 적절한 토크나이저의 학습이 필요하고, 이 때 [unused00] 토큰들을 추가해서 이후에 스페셜 토큰으로 활용하곤 한다.
나는 aspect word 토큰 앞 뒤에 스페셜 토큰을 붙여서 그 안의 토큰들을 태깅할 계획이었는데 아래와 같이 [ASP]와 [unused00] 토큰들을 추가해서 학습시켰음에도 불구하고 제대로 토크나이즈가 되지 않는 문제가 발생했다.

Solution
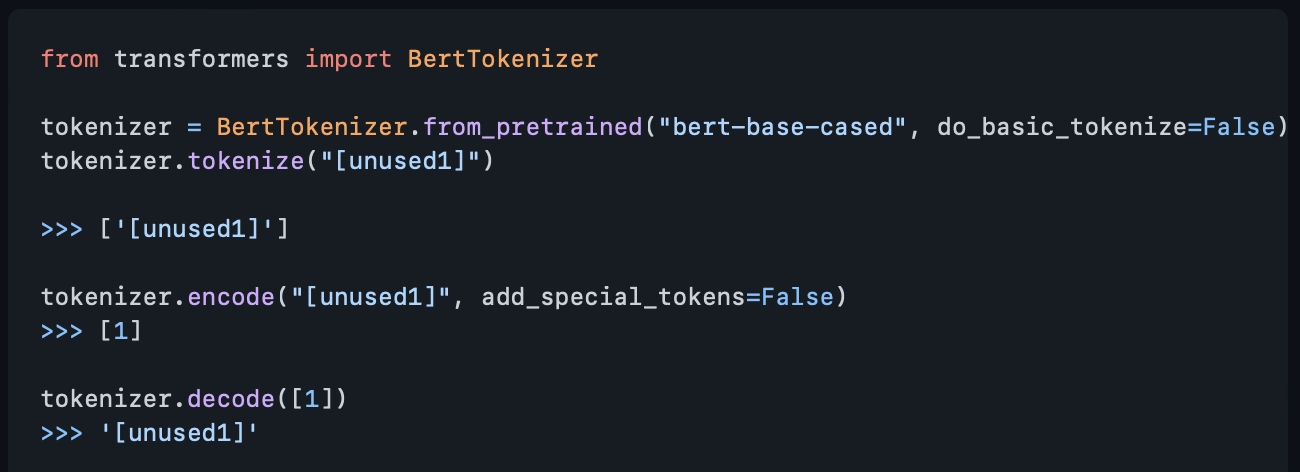
허깅페이스 깃허브에도 이와 같은 이슈를 문의한 내용이 있었고, 참고하여 해결하였다. 해결방법은 "do_basic_tokenize=False". Document의 해당 부분을 읽어보지 못해서 왜 베이직 토크나이즈를 False로 주는지 그 의미는 아직 잘 이해하지 못했으나, 이후에도 사용할 일이 있을 것 같아서 메모해둔다.
Example
tokenizer를 읽어올 때 do_basic_tokenize=False를 똑같이 주었다. from_pretrained가 아니어도 같은 로직으로 작동한다.
from transformers import BertTokenizer
tkzer2 = BertTokenizer(PATH_TOKENIZER, do_lower_case=False,
do_basic_tokenize=False)
references
github/huggingface

Graduate School of DataScience, NLP researcher. AI engineer at NAVER PlaceAI