

회사에서 데이터 파이프라인을 만들면서 데이터 엔지니어링 쪽에 관심이 생겼다. 뭔가 내가 만든 파이프라인을 볼 때마다 뭔가 관리가 제대로 안 되는 듯한 느낌을 받았는데... (물론 나 혼자의 의견으로만 만든 것은 아님) 회사에 DE쪽을 아는 사람이 거의 없는 것 같기 때문에 이 참에 공부하면 좋을 것 같아 차근차근 작성해보고자 한다. 👀
1. Airflow란?
- Airflow는 airbnb 엔지니어링 팀에서 개발한 워크플로 오픈소스 플랫폼이다.
- Python 기반으로 복잡한 데이터 파이프라인(추출, 가공, 저장 등)을 자동화하고 스케줄링하는 데 사용된다.
- Airflow 에서 Data Pipeline = DAG
2. 주요 개념
Workflow- 의존성으로 연결된 작업들의 집합
- ETL 같은 경우는 Extraction -> Transformation -> Load의 흐름을 가지는 workflow임
DAG(Directed Acyclic Graph)- 순환하지 않고 방향성을 갖는 워크플로우
- Airflow에서는 이러한 DAG을 이용해 언제, 어떤 순서로 Task들을 실행시킬 지 정의할 수 있다.
Task- DAG을 이루는 단위 작업
3. Airflow Component 구성 요소
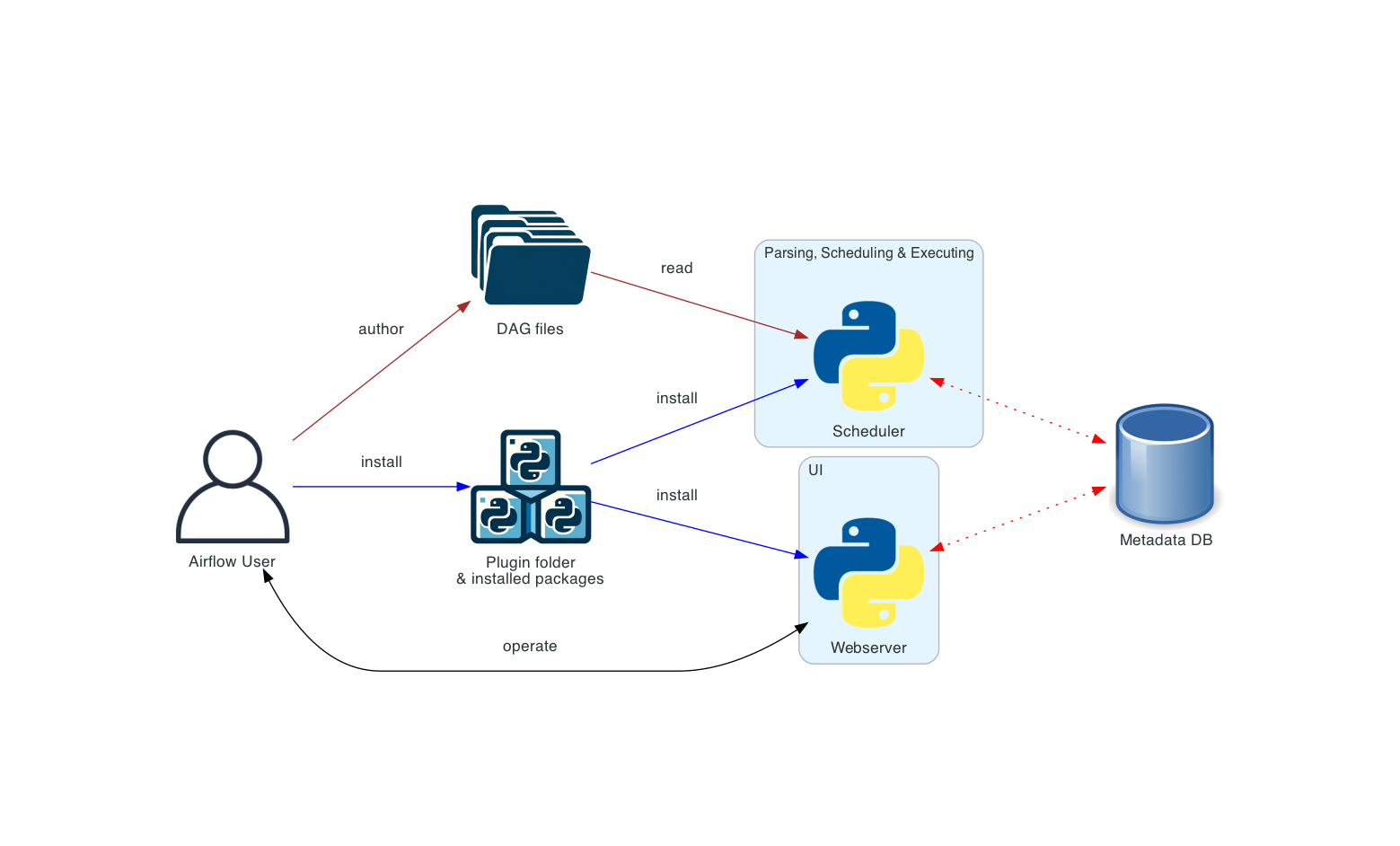
Web Server- Airflow의 웹 UI이 서버로, 실행 중인 작업을 한 눈에 볼 수 있도록 사용자에게 다양한 시각적 정보를 볼 수 있는 기능을 제공한다.
- Python + Flask로 개발되었다.
Scheduler- 모든 DAG과 Task를 모니터링 및 관리하고 실행해야 할 Task를 스케줄링 한다.
- Executor에게 task를 제공해주는 역할을 수행한다.
Executor- 실행 중인 Task를 관리하는 컴포넌트, 실제 어떤 리소스가 투입되어 실행될 것인지를 결정한다.
- Worker에게 Task를 push 한다.
Worker- 실제 Task를 실행하는 주체자
Database- airflow에 있는 DAG, Task 등의 metadata를 저장하고 관리한다.
Queue- 놀고 있는 Worker가 생기면 Queue의 Task를 할당한다.
4. Airflow 동작 방식
- 사용자는 DAG을 생성한다.
- Airflow는 DAG을 읽고 Scheduler가 스케줄링한다.
- Worker가 Task를 가져가 실행한다.
- Task의 실행 결과는 Database에 저장된다.
- 사용자는 UI(Webserver)를 통해서 각 Task의 실행 상태, 성공 여부 등을 확인하고 관리한다.
5. Operator
- 각 DAG은 여러 Task로 이루어져 있다. Operator나 Sensor가 하나의 Task로 만들어 지는데, Airflow는 기본적인 Task를 위해 다양한 Operator를 제공한다.
- 즉, Operator란 Task를 실행시키는 기계 (Operator가 객체화, 인스턴스화 되면 Task가 된다!)
- 주요 오퍼레이터
BashOperator: Python 함수 실행PythonOperator: bash command 실행EmailOperator: Email 전송MySqlOperator: sql 쿼리 수행
6. Airflow 장단점
장점
- 데이터 파이프라인 세밀하게 작성 및 제어 가능
- 다양한 데이터 소스, 데이터 웨어하우스 지원
- 파이썬에서 지원되는 라이브러리 활용하여 다양한 도구 컨트롤 및 커스터마이징 가능
- 백필이 쉬움
단점
- 러닝커브 존재
- 실시간 워크플로우 관리에는 적합하지 않음 (배치성 실행에 적합)
- 환경 구축이 어려워 클라우드 상에서 사용되는 것이 선호되어짐
- GCP의 Cloud Composer
- AWS의 Managed Workflows for Apache Airflow
7. DAG
DAG 생성
~airflow/dags폴더 밑에 {dags_name}.py 생성- 기초 Python DAG 파일 생성 예제
from airflow import DAG
import datetime
import pendulum
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
import random
with DAG(
# dag_id에는 보통 python file과 같은 이름으로 생성
dag_id="dags_python_operator",
schedule="30 6 * * *", # 분 시 일 월 요일
start_date=pendulum.datetime(2023, 3, 1, tz="Asia/Seoul"), # dag 생성 이후 바꾸면 안됨. 바꾸려면 dag 새로 생성 or dag_id 변경
catchup=False # start_date부터 backfill 할 것인지 여부
) as dag:
# 1. bash 오퍼레이터
bash_t1 = BashOperator(
task_id="bash_t1",
bash_command="echo whoami", # ehco = print
)
# 2. 파이썬 오퍼레이터
def select_fruit():
fruit = ['APPLE', 'BANANA', 'ORANGE', 'AVOCADO']
rand_int = random.randint(0,3) # 0 ~ 3 까지 임의의 숫자 반환
print(fruit[rand_int])
# 해당 operator를 통해 task 정의
py_t1 = PythonOperator(
task_id = 'py_t1',
python_callable=select_fruit
)
# task들의 수행 순서
bash_t1 >> py_t1