Algorithm
1.[Algorithm] 배열과 리스트 그리고 벡터

자료구조 배열과 리스트 그리고 벡터 배열 > 메모리의 연속 공간에 값이 채워져 있는 형태의 자료구조 인덱스를 사용하여 값에 바로 접근할 수 있다 새로운 값을 삽입하거나 특정 인덱스에 있는 값을 삭제하기 어렵다. 값을 삽입하거나 삭제하려면 해당 인덱스 주변에 있는
2.[BOJ/C++] 11720 숫자의 합
공백 없이 입력된 숫자를 모두 합하면 되는 문제입니다 각 문자에서 '0'을 빼면 정수 숫자를 얻을 수 있습니다.
3.[BOJ/C++] 1546 평균
평균을 구하면 되는 문제이지만 모든 과목의 점수를 점수의 최댓값으로 나누고 100을 곱해 새로운 점수들의 평균을 구해야합니다. 점수들의 총 합을 $sum$이라고 한다면 새롭게 구한 점수들의 합 $sum = (과목들의 합 / M) * 100$ 이고 이 점수들의 총
4.[BOJ/C++] 11659 구간 합 구하기4
구간의 합을 구하면 되는 문제로 입력받은 숫자의 합 배열을 구하면 되는 문제입니다.합 배열 $S$의 정의 $Si = A0 + A2 + ... + Ai-1 + Ai$합 배열을 다음과 같이 만들 수 있습니다$Si = Si-1 + Ai$$i$에서 $j$ 까지의 구간 합은 $
5.[BOJ/C++] 11660 구간 합 구하기5
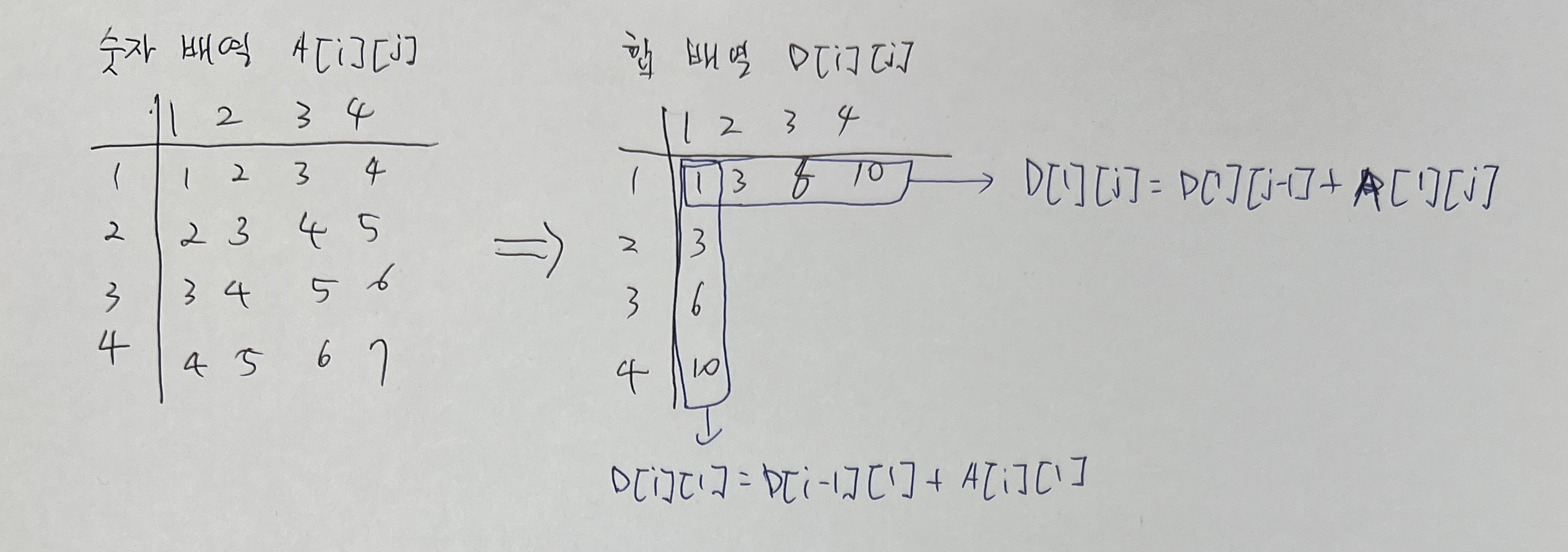
2차원 배열의 구간 합을 구하는 문제로 $(X1, Y1)$ 에서 $(X2, Y2)$ 까지의 합을 구하는 문제입니다.먼저 숫자 배열로부터 1행, 1열의 구간합을 구합니다.구한 1행 1열의 구간 합으로 $(2,2)$의 구간 합을 구합니다.여기서 구간 합을 구하기 위한 식은
6.[BOJ/C++] 10986 나머지 합
구간 합을 이용해야 하는 문제입니다.$Ai + ... + Aj (i<j)$ 까지의 합이 M으로 나누어 떨어지는 $(i,j)$의 쌍을 구해야합니다구간 합 $Sj - Si$는 $i+1$ 부터 $j$까지의 구간 합 이므로$Sj$%M의 값과 $Si$%M의 값이 같다면 $
7.[BOJ/C++] 2018 수들의 합-5
투 포인터를 이용하여 문제를 해결할 수 있습니다시간 제한이 2초이고 N의 최댓값은 10,000,000 이므로 $O(nlogn)$인 알고리즘을 사용하면 시간초과가 발생하므로 $O(n)$인 알고리즘을 사용해야 합니다.3가지의 경우의 수로 투 포인터를 이동할 수 있습니다.s
8.[BOJ/C++] 1940 주몽
투 포인터를 이용하여 문제를 해결할 수 있습니다.N이 최대 15,000이므로 $O(nlogn)$을 사용할 수 있으므로 정렬 알고리즘을 사용해도 됩니다.오름차순으로 정렬 후 시작과 끝을 투 포인터로 가르킨다.합이 M이 되는 순간 count++
9.[BOJ/C++] 1253 좋다
먼저 N의 개수가 최대 2,000이므로 $O(n^2)$ 보다 작아야합니다.입력받은 배열을 정렬한 후 시작하는 것이 좋습니다.start_index는 0부터 시작하고 end_index는 N-1 부터 시작합니다vstart_index + vend_index == vi라면 서로
10.[BOJ/C++] 12891 DNA 비밀번호
슬라이딩 윈도우 알고리즘을 이용해 해결할 수 있습니다.슬라이딩 윈도우 알고리즘은 2개의 포인터로 범위를 지정한 다음 범위를 유지한 채로 이동하며 문제를 해결합니다.염기 서열 A, C, G, T를 체크할 배열을 만든 후 범위를 지정해 해당 범위 내에 염기 개수를 체크하는
11.[BOJ/C++] 11003 최솟값 찾기
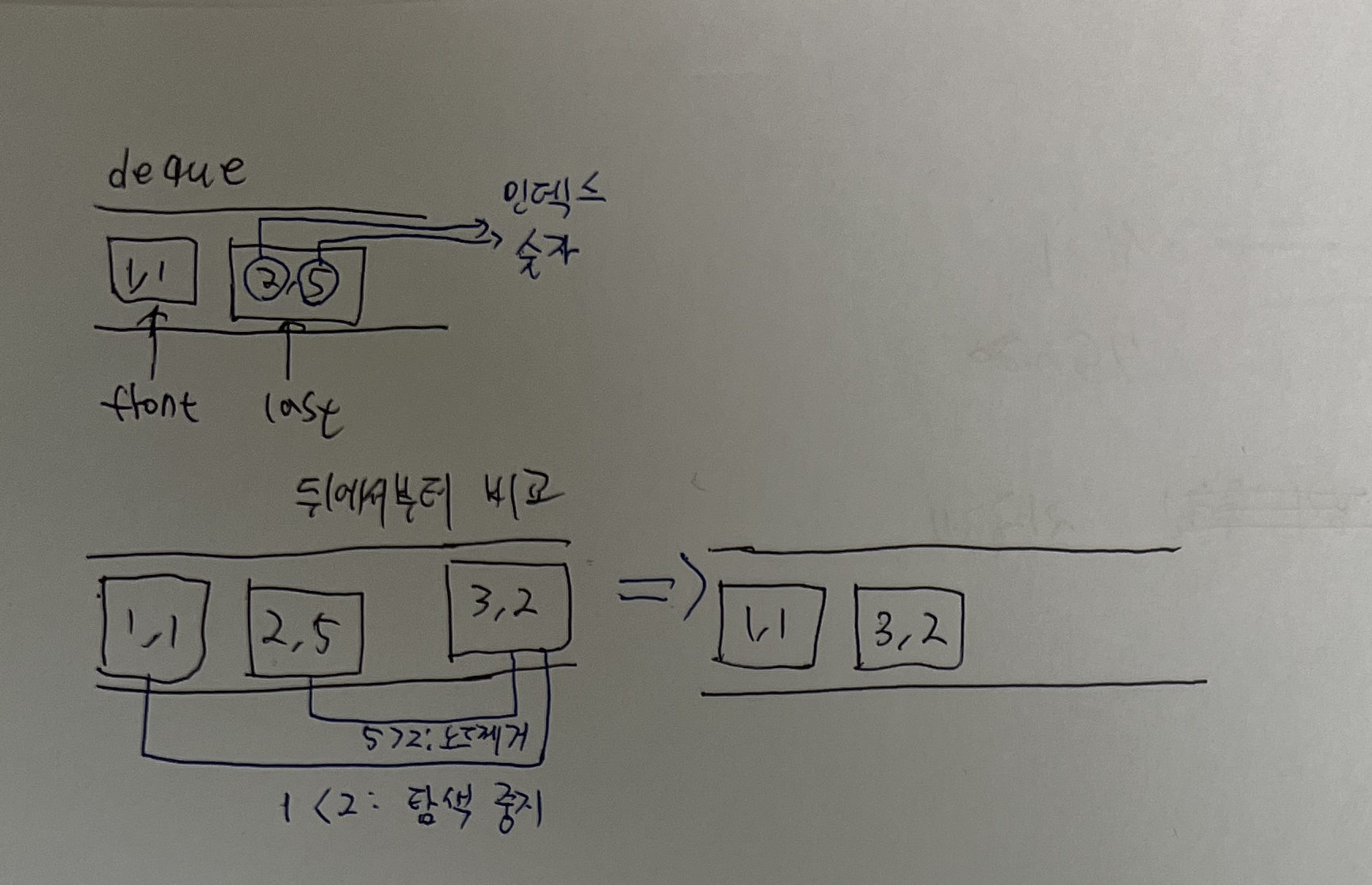
슬라이딩 윈도우 알고리즘을 통해 문제를 해결할 수 있습니다.최솟값의 범위가 $i-L+1$ 부터 $i$까지 이므로 범위는 $L$ 입니다.N과 L의 범위가 5,000,000 이기 때문에 정렬을 사용할 수 없으므로 Deque를 이용해볼 수 있습니다.Deque에 인덱스와 숫자
12.[BOJ/C++] 1874 스택 수열
문제 이름에서 유추할 수 있듯 스택을 이용하여 해결할 수 있습니다. 입력받은 숫자가 나올때까지 숫자를 하나씩 증가시켜 스택에 push합니다.
13.[BOJ/C++] 17298 오큰수
N이 1,000,000이기 때문에 반복문을 사용하면 시간 초과가 발생합니다.스택을 이용하여 해결할 수 있습니다.스택에 새로 들어오는 수가 top에 존재하는 수보다 크면 그 수는 오큰수가 된다.오큰수를 구한 후 수열에서 오큰수가 존재하지 않는 숫자에 -1을 출력한다.
14.[BOJ/C++] 2164 카드2
큐를 이용하여 문제를 해결할 수 있습니다.pop을 수행하여 맨 앞의 카드를 버린다.pop -> push를 수행해 맨 앞에 있는 카드를 가장 아래로 옮긴다큐의 크기가 1이 될 때까지 반복한 후 남은 원소를 출력한다.
15.[BOJ/C++] 11286 절댓값
우선순위 큐를 이용해 문제를 해결할 수 있습니다.x==0큐가 비어있을 때는 0을 출력하고 비어 있지 않을 때는 절댓값이 최소인 값을 출력한다. 단, 절댓값이 같을 경우 음수를 우선하여 출력해야하기 때문에 비교하는 compare 구조체를 따로 정의해야한다.x==1우선순위
16.[Algorithm] 정렬

데이터의 인접 요소끼리 비교하고 swap 연산을 수행하며 정렬하는 방식버블 정렬은 두 인접한 데이터의 크기를 비교해 정렬하는 방법이다간단하게 구현할 순 있지만 시간 복잡도는 $O(n^2)$으로 다른 정렬 알고리즘보다 속도가 느린 편이다비교 연산이 필요한 루프 범위를 설
17.[BOJ/C++] 2750 수 정렬하기
정렬 문제로 버블 정렬을 이용하여 문제를 쉽게 해결할 수 있습니다.
18.[BOJ/C++] 1377 버블 소트
버블 정렬을 수행하며 한번도 일어나지 않은 루프를 찾는 문제입니다.N이 500,000 이므로 버블 정렬을 이용하면 시간 초과가 발생합니다.버블 정렬의 안쪽 루프는 특정 데이터가 왼쪽으로 이동할 수 있는 최대 거리가 1이므로입력 받은 숫자의 정렬 전 인덱스와 정렬 후 인
19.[BOJ/C++] 11399 ATM
시간 복잡도가 $O(n^2)$이 허용되기 때문에 아무 정렬이나 이용해서 문제를 해결할 수 있습니다.삽입 정렬을 이용하여 문제를 해결해보겠습니다.
20.[BOJ/C++] 1427 소트인사이드
시간 복잡도 $O(n^2)$을 허용하므로 정렬을 이용하여 문제를 해결할 수 있습니다.선택 정렬을 이용해 문제를 해결해보겠습니다\`문자열로 입력받아 각 문자를 숫자로 변환해 벡터로 저장한 뒤 정렬을 수행하면 됩니다.
21.[BOJ/C++] 11004 K번째 수
정렬 했을때 앞에서부터 K번째 수는 vk-1 번째 수와 같습니다.정렬을 이용하여 해결할 수 있습니다.QuickSort를 직접 구현해보았으나 최악의 경우 시간복잡도가 $O(n^2)$ 이기 때문에 시간초과가 발생할 수 있습니다.C++의 STL에 구현되어 있는 Sort는 Q
22.[BOJ/C++] 2751 수 정렬하기2
정렬 문제로 병합 정렬을 이용하여 문제를 해결했습니다.
23.[BOJ/C++] 1517 버블 소트

병합 정렬에서 두 그룹이 병합되는 과정에서 버블 정렬의 swap이 포함되어 있음을 이용하여 문제를 해결할 수 있습니다.5가 앞의 4개의 데이터보다 작으므로 swap이 4번 일어난것과 동일합니다.병합하는 과정에서 작은 값이 저장될 때 해당 수의 인덱스와 저장되는 위치의
24.[BOJ/C++] 10989 수 정렬하기 3
N이 10,000,000 으로 매우 크기 때문에 $O(nlogn)$보다 빠른 알고리즘이 필요합니다.기수 정렬 및 계수 정렬은 $O(Kn)$이기 때문에 이를 이용하여 해결할 수 있습니다.계수 정렬이 기수 정렬보다 간단하기 때문에 계수 정렬을 이용했습니다.N이 1~1000
25.[Algorithm] 탐색
한 방향으로 갈 수 있을 때까지 가다가 더 이상 갈 수 없을 때 가장 최근 갈림길로 돌아와 다른 길을 선택하여 다시 진행하는 방법가능한 모든 경로를 탐색스택 또는 재귀함수(가장 보편적이고 코드가 짧음) 이용시간 복잡도는 %O(V + E)$, V: 정점 수, E: 간선
26.[Algorithm] DFS & BFS
한 방향으로 갈 수 있을 때까지 가다가 더 이상 갈 수 없을 때 가장 최근 갈림길로 돌아와 다른 길을 선택하여 다시 진행하는 방법 가능한 모든 경로를 탐색스택 또는 재귀함수(가장 보편적이고 코드가 짧음) 이용간선으로 이어진 정점 i,j가 그래프에 존재한다면?Mi =
27.[BOJ/C++] 11724 연결 요소의 개수
연결되어 있는 그룹의 개수를 구하면 되는 문제입니다.모든 정점에 대해 DFS를 진행하고 실행된 DFS 횟수가 연결 요소의 개수가 됩니다.
28.[BOJ/C++] 2023 신기한 소수
N자리의 숫자를 왼쪽에서부터 1자리~N자리의 모든 숫자가 소수인 숫자를 찾는 문제입니다.각 자리의 숫자에 대해 DFS를 이용하여 문제를 해결할 수 있습니다.예를 들어 숫자가 2333이라면 2, 23, 233, 2333 모두 소수이므로 신기한 소수가 됩니다.1자리 숫자중
29.[BOJ/C++] 13023 ABCDE
문제의 조건은 다음과 같습니다. N명이 있을때 A와 B는 친구이다.B와 C는 친구이다.C와 D는 친구이다.D와 E는 친구이다.의 조건을 만족하면 됩니다. 연속된 친구의 관계가 5명이면 됩니다.DFS를 이용하여 문제를 해결할 수 있습니다.주어진 모든 노드에 대해 DFS를
30.[BOJ/C++] DFS와 BFS
기본적인 BFS와 DFS를 구현하여 방문한 순서대로 출력하면 되는 문제입니다.
31.[BOJ/C++] 2178 미로 탐색

2차원 좌표계인 미로를 탐색하는 문제입니다.상, 하, 좌, 우를 기준으로 탐색할 수 있습니다.DFS보다 BFS가 적합한 이유는 해당 깊이에서 갈 수 있는 노드 탐색을 마친 후 다음 깊이로 넘어가기 때문입니다.갈 수 있는 노드를 깊이로 업데이트 하면서 탐색하여 해결할 수
32.[BOJ/C++] 1167 트리의 지름
탐색을 이용하여 문제를 해결할 수 있습니다.임의의 노드에서 가장 먼 거리에 있는 노드는 트리의 지름에 해당하는 두 노드중 하나입니다.DFS를 이용하여 가장 먼 거리에 있는 노드를 구한 후 해당 노드로부터 가장 먼 거리의 노드를 구하면 되는 문제입니다.
33.[BOJ/C++] 1920 수 찾기
N의 100,000 이므로 정렬과 이진탐색을 이용하여 $O(nlogn)$의 시간복잡도로 문제를 해결할 수 있습니다.입력 받은 수를 정렬하고 이후 찾아야하는 수를 이진 탐색을 통해 찾습니다.
34.[BOJ/C++] 2343 기타 레슨
이진 탐색을 이용하여 문제를 해결할 수 있습니다.$l=$ 레슨 길이의 최댓값$r=$ 레슨 길이의 합$mid$ 값으로 모든 레슨을 저장할 수 있으면 $r=mid-1$$mid$ 값으로 모든 레슨을 저장할 수 없으면 $l=mid+1$탐색이 종료되었을 때 $l$ 값이 블루레이
35.[BOJ/C++] 1300 K번째 수
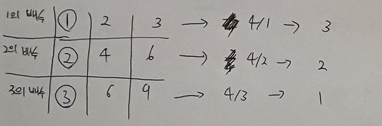
이진 탐색으로 문제를 해결할 수 있지만 아이디어를 떠올리기 어려웠던 문제입니다.우선 이진 탐색을 써야한다는 것 자체를 떠올리는게 어려웠습니다.그리고 K번째 수보다 작거나 같은 값이 최소 K개 존재한다는 것과 각 행렬을 T로 나눈 몫과 N의 최솟값이 T보다 작은 수의 개
36.[BOJ/C++] 11047 동전 0
그리디 알고리즘을 이용해 문제를 해결할 수 있습니다.현재 상태에서 볼 수 있는 선택지 중에 최선의 선택을 하는 알고리즘DP보다 구현하기 쉽고 시간 복잡도가 우수하다항상 최적의 해를 보장하지 못하다그리디 알고리즘을 사용하기 전에 논리 유무를 충분히 살펴야 한다해 선택:
37.[BOJ/C++] 1715 카드 정렬하기
우선순위 큐를 이용하여 문제를 해결할 수 있습니다.작은 묶음의 카드부터 더해나가는 것이 최솟값이기 때문에 오름차순의 우선순위 큐에 모든 카드를 넣습니다.카드를 2개씩 꺼내어 두 묶음의 합을 우선순위 큐에 삽입하고 누적해서 더합니다.
38.[BOJ/C++] 2374 같은 수 만들기
그리디 알고리즘과 스택을 이용해서 문제를 해결할 수 있습니다.재귀를 이용해서 문제를 풀어도 되지만 같은 수 만들기 2 문제에서 시간초과로 문제를 해결할 수 없습니다.시간 복잡도 면에서 스택을 이용하는 것이 더 좋기 때문에 스택을 이용해서 문제를 해결해보겠습니다.또한 입
39.[BOJ/C++] 1744 수 묶기
우선순위 큐를 이용하여 문제를 해결할 수 있습니다.
40.[BOJ/C++] 1931 회의실 배정
41.[BOJ/C++] 1541 잃어버린 괄호
그리디 알고리즘을 이용하여 문제를 해결할 수 있습니다.최솟값을 만들기 위해선 음수를 가장 크게 만들어야합니다.마이너스 부호를 시작으로 이후 나오는 덧셈을 괄호를 이용해 모두 묶어주면 가장 큰 음수를 얻을 수 있습니다.즉, 마이너스 부호 이후에 나오는 값들을 모두 빼주면
42.[BOJ/C++] 25556 포스택
그리디 알고리즘을 이용해 문제를 해결할 수 있습니다. 처음에는 단순하게 스택 4개를 이용해서 문제를 풀어보려고 했으나 굳이 스택을 4개 안써도 될 것 같아서 다르게 접근해봤습니다.
43.[BOJ/C++] 1929 소수 구하기
N이 최대 100만이기 때문에 일반적인 소수 구하는 방법으로는 시간초과가 발생합니다.에라토스테네스의 체를 이용하여 문제를 해결할 수 있습니다.
44.[BOJ/C++] 2812 크게 만들기
그리디 알고리즘과 스택을 이용하여 문제를 해결할 수 있습니다.문자열을 순회하며 다음과 같이 진행합니다.1\. 스택이 비어있거나 K개만큼 제거했을 때 \- 스택에 push2\. 그렇지 않고 스택의 top이 $i$번째 숫자보다 클 때 \- 스택에 push3\. 스택의 to
45.[BOJ/C++] 1456 거의 소수
에라토스테네스의 체 알고리즘을 이용하여 문제를 해결할 수 있습니다.입력이 최대 10의 14승 이고 에라토스테네스의 체를 이용하면 제곱근까지만 수행하면 됩니다.먼저 에라토스테네스의 체를 이용하여 소수를 구해줍니다이후 모든 소수에 대해서 거듭제곱을 하며 B보다 작거나 같을
46.[BOJ/C++] 1747 소수 & 팰린드롬
47.[BOJ/C++] 1016 제곱 ㄴㄴ 수
에라토스테네스의 체를 응용하여 문제를 해결할 수 있습니다.우선 문제의 min, max의 최댓값을 보면 1,000,000,000,000로 매우 큰 숫자입니다.하지만 min <= max <= min + 1,000,000 의 조건을 살펴보면 확인해야 하는 범위는
48.[BOJ/C++] 11689 GCD(n, k) = 1
오일러 피 함수 $PN$은 1~N까지 범위에서 N과 서로소인 자연수의 개수를 뜻합니다.구하고자 하는 오일러 피의 범위만큼 배열을 자기 자신의 인덱스 값으로 초기화한다.2부터 시작해 현재 배열의 값과 인덱스가 같으면(= 소수일 때) 현재 선택된 숫자(K)의 배수에 해당하
49.[BOJ/C++] 1934 최소 공배수 구하기
유클리드 호제법을 이용해 문제를 해결할 수 있습니다.a와 b의 최소공배수는 $a\*b/gcd$로 나타낼 수 있습니다.
50.[BOJ/C++] 1850 최대공약수
유클리드 호제법을 이용해 문제를 해결할 수 있습니다.long을 사용했더니 오버플로우가 발생하여 long long으로 해결했습니다.
51.[BOJ/C++] 1033 칵테일
N-1개의 비율로 N개의 재료와 관련된 전체 비율을 알아낼 수 있습니다.이를 그래프 관점으로 보면 사이클이 없는 트리 구조로 볼 수 있습니다.먼저 비율을 같은 기준으로 변환하여 각 재료의 실제 양을 구하기 위해 비율의 최소공배수를 구해야합니다.입력을 예시로 들면 1,
52.[Algorithm] 그래프(Graph)
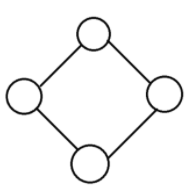
단순히 노드(N, node)와 그 노드를 연결하는 간선(E, edge)을 하나로 모아 놓은 자료구조연결되어 있는 객체 간의 관계를 표현할 수 있다. ex) 지도, 지하철 노선도, 도로, 전기 회로 등그래프는 여러 개의 고립된 부분 그래프로 구성될 수 있다.정점(vert
53.[BOJ/C++] 18352 특정 거리의 도시 찾기
BFS를 이용해 문제를 해결할 수 있습니다.시작 노드부터 모든 노드를 방문하며 거리를 업데이트 합니다.방문 배열에서 K 거리를 만족하는 노드가 있다면 출력하고만족하는 노드가 한 개도 없다면 -1을 출력합니다.
54.[BOJ/C++] 1325 효율적인 해킹
BFS를 이용하여 문제를 해결할 수 있습니다.A가 B를 신뢰할때 B를 통해 A를 해킹할 수 있으므로 B->A로 간선이 연결됩니다.방향이 있는 그래프이기 때문에 인접 리스트에서 하나의 노드에만 추가해야합니다.
55.[BOJ/C++] 1707 이분 그래프
DFS를 이용해 문제를 해결할 수 있습니다.문제의 핵심은 인접한 노드를 다른 그룹으로 나누는 것입니다.탐색을 진행하며 방문한 노드가 아니라면 현재 노드와 다른 그룹으로 나눕니다.이때 이미 방문한 노드가 현재 노드와 같은 집합이면 이분 그래프가 아닙니다.
56.[BOJ/C++] 2251 물통
BFS를 이용해 문제를 해결할 수 있습니다.우선 탐색을 할 수 있는 경우의 수는 6개로1\. A->B, A->C2\. B->A, B->C3\. C->A, C->B의 경우를 모두 탐색하며 보내는 물통의 모든 용량을 받는 물통에 저장하고 보내는 물통에 0을 저장합니다.이
57.[Algorithm] Union-Find(유니온 파인드)
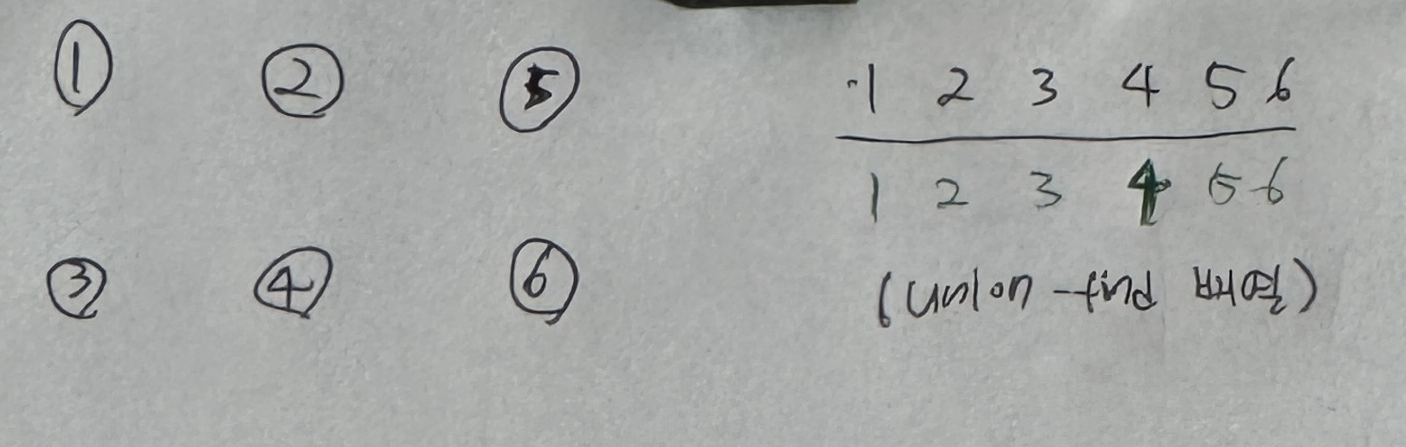
여러 노드가 있을 때 특정 2개의 노드를 연결해 1개의 집합으로 묶는 union 연산과두 노드가 같은 집하에 속해 있는지를 확인하는 find 연산으로 구성된 알고리즘입니다.각 노드가 속한 집합을 1개로 합치는 연산으로노드 a, b가 $a \\in A, b \\in B$
58.[BOJ/C++] 1717 집합의 표현
유니온 파인드를 이용하여 문제를 해결할 수 있습니다.문제에서 0은 합집합 1은 같은 집합에 포함되어 있는지 확인하는 연산이라고 되어있습니다.이는 0은 union 연산을 실행하고, 1은 find 연산을 통해 같은 집합에 포함되어 있는지 확인한다는 힌트를 얻을 수 있습니다
59.[BOJ/C++] 1976 여행 가자
BFS를 이용해도 되지만 유니온 파인드를 이용해서 문제를 해결했습니다.모든 여행 경로에 대해서 parent가 동일하다면 여행 경로가 모두 연결되어있으므로 해당 경로로 여행할 수 있습니다
60.[BOJ/C++] 1043 거짓말
유니온 파인드를 이용해 문제를 해결할 수 있습니다.각 파티에 진실을 알고있는 사람과 연결되어 있다면 해당 파티에서는 과장된 얘기를 할 수 없습니다.각 파티의 사람들을 union 연산을 통해 같은 그룹으로 만듭니다각 파티의 임의의 사람과 진실을 알고있는 사람을 비교해 한
61.[Algorithm] 위상 정렬
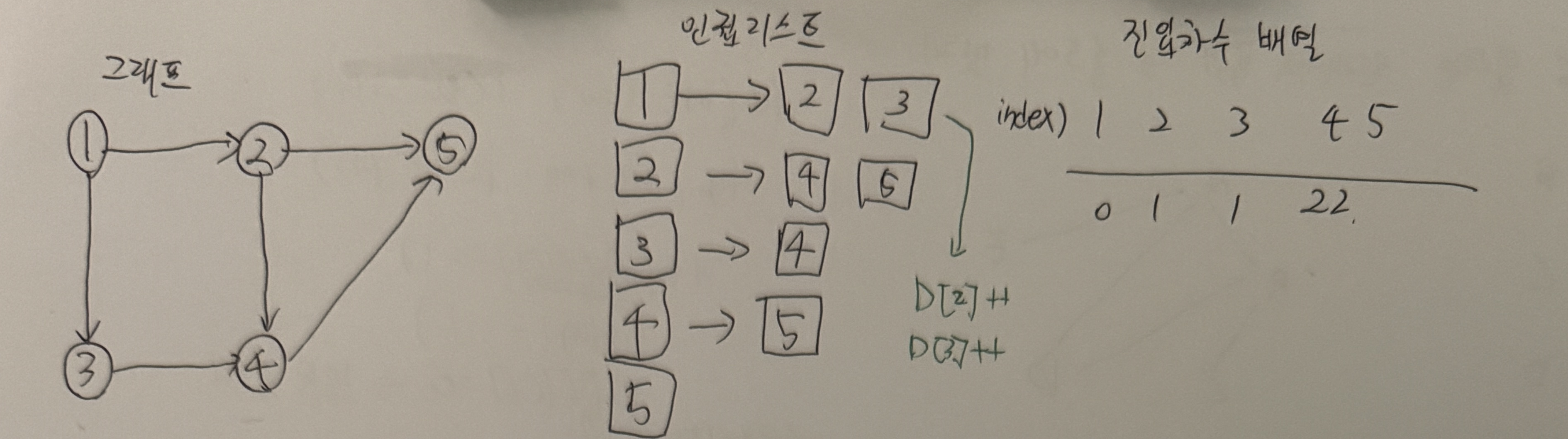
위상 정렬은 사이클이 없는 방향 그래프에서 노드 순서를 찾는 알고리즘 입니다.진입 차수 배열 D를 다음과 같이 업데이트 합니다.진입 차수는 자기 자신을 가리키는 에지의 개수입니다.1에서 2, 3을 가리키고 있으므로 $D2, D3$을 각각 1씩 증가시킵니다.진입 차수 배
62.[BOJ/C++] 2252 줄 세우기
일부 학생들의 키를 비교하여 줄을 세우는 것은 학생들을 노드로 생각하고 노드의 순서를 도출하는 것으로 생각할 수 있습니다.또한 답이 여러 가지일 경우 아무거나 출력해도 된다는 것은 항상 동일한 결과가 나오지 않는 위상 정렬의 전제와 동일합니다.위상 정렬의 수행 과정1\
63.[BOJ/C++] 1516 게임 개발
"어떤 건물을 짓기 위해 먼저 지어야 하는 건물이 있을 수 있다" 라는 문장에서노드 순서를 정렬하는 위상 정렬을 사용하는 문제임을 알 수 있습니다.중요한 점은 다음 건물에 저장된 시간, 현재 건물에 저장된 시간 + 다음 건물의 생산 시간의 최댓값으로 업데이트 해야합니다
64.[Algorithm] Djikstra
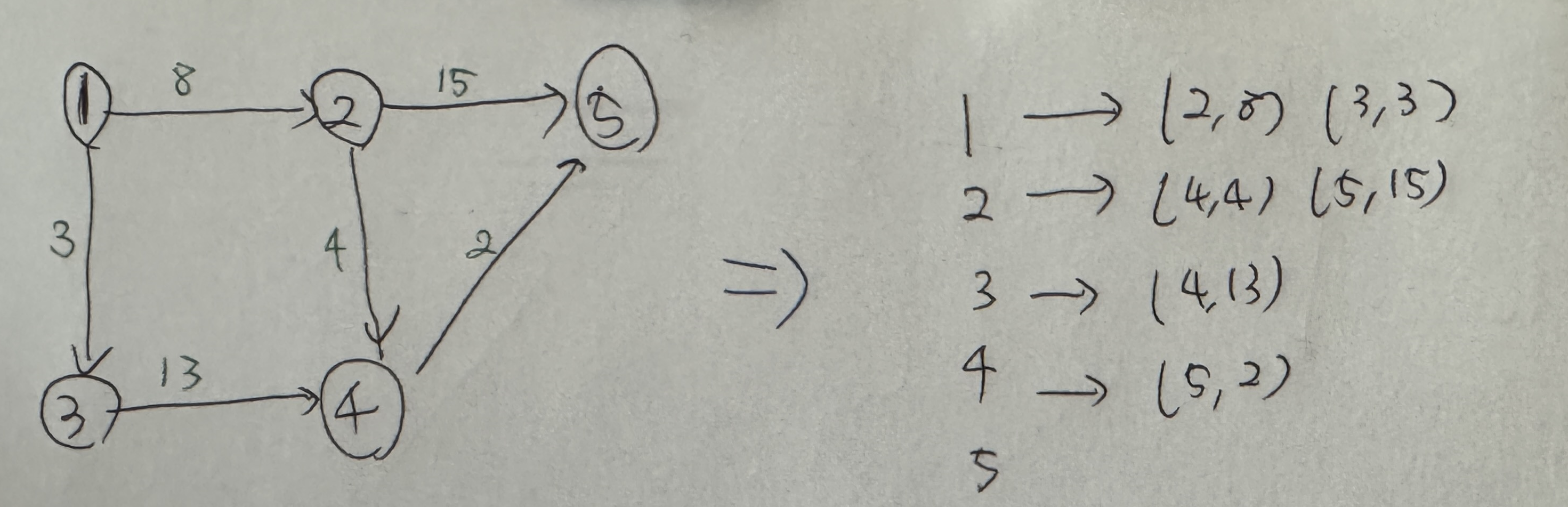
다익스트라 알고리즘은 그래프에서 최단 거리를 구하는 알고리즘으로 다음과 같은 특징을 가지고 있습니다.인접 행렬로 구현하는 것보다 시간 복잡도 측면에서 N이 클 것을 대비해 인접 리스트로 구현하는 것이 좋습니다최단 거리 배열을 만들고 출발 노드는 0, 이외의 노드는 무한
65.[BOJ/C++] 1753 최단 경로
최단 경로를 구하는 문제로 다익스트라를 이용해 문제를 해결할 수 있습니다
66.[BOJ/C++] 1916 최소비용 구하기
출발 도시에서 도착 도시까지 최소 비용을 구하는 문제로 다익스트라 알고리즘을 이용해 문제를 해결할 수 있습니다시간초과가 발생하여 시간 복잡도를 줄일 필요가 있습니다.이미 방문한 노드 중 가중치가 현재 노드까지의 최단거리보다 크다면 최단거리를 업데이트 할 필요가 없습니다
67.[Algorithm] 벨만-포드(bellman-ford-moore)
벨만-포드 알고리즘은 그래프에서 최단 거리를 구하는 알고리즘으로 다음과 같은 특징이 있습니다.에지 리스트는 출발 노드, 도착 노드, 가중치 3개의 정보를 가지고 있습니다.최단 경로 배열은 출발 노드는 0 나머지는 INT_MAX로 초기화합니다.최단 경로 배열의 업데이트
68.[BOJ/C++] 11657 타임머신
시작 노드에서 다른 모든 노드까지의 최단거리를 구하며 가중치가 음수도 가능하기 때문에 벨만-포드 알고리즘을 이용해 문제를 해결할 수 있습니다.모든 에지와 관련된 정보를가져온 후 다음 조건에 따라 최단 거리 배열을 업데이트노드 개수 -1 만큼 1번을 반복음수 사이클의 유
69.[BOJ/C++] 1219 오민식의 고민
최단 경로가 아닌 최대 경로를 구하며 같은 도시에 여러 번 방문할 수 있습니다.이것은 벨만-포드 알고리즘을 응용해 최대 경로를 구하고 양의 사이클의 존재 여부를 구하면 됩니다.모든 간선에 대해 최대 경로 배열 업데이트시작 노드가 방문한 적이 없으면 패스시작 노드가 양수
70.[Algorithm] 플로이드-워셜(Floyd-warshall)
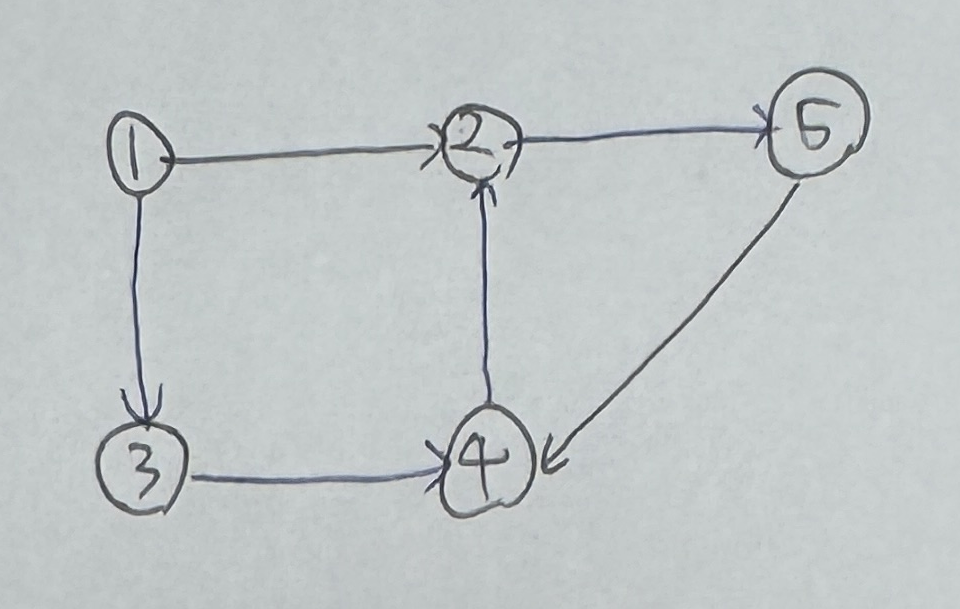
플로이드-워셜 알고리즘은 그래프에서 최단 거리를 구하는 알고리즘으로 다음과 같은 특징을 가지고 있습니다.A 노드에서 B 노드까지 최단 경로를 구했다고 가정했을 때 최단 경로 위에 K 노드가 존재한다면 그것을 이루는 부분 경로 또한 최단 경로위 그림에서 1번 노드에서 5
71.[BOJ/C++] 11404 플로이드
출발 노드 $i$에서 도착 노드 $j$로 가는 최소 비용을 구하는 문제로 플로이드-워셜 알고리즘을 이용해 문제를 해결할 수 있습니다.N이 최대 100 이므로 $O(N^3)$인 플로이드-워셜 알고리즘으로도 가능합니다.LONG_MAX로 초기화 할 경우 $Gi > Gi +
72.[BOJ/C++] 11403 경로 찾기
N이 최대 100이므로 플로이드-워셜 알고리즘을 이용해 문제를 해결할 수 있습니다.기존 최단 경로를 찾는 문제가 아니라 모든 노드에 대해 갈 수 있는 경로가 있는지를 확인하는 문제로$min(DS, DS + DK$가 아닌 $DS == 1$ 이고 $DK == 1$ 이면 $
73.[BOJ/C++] 1389 케빈 베이컨의 6단계 법칙
기존에 BFS로 문제를 해결했지만 N이 최대 100이므로 플로이드-워셜 알고리즘으로도 문제를 해결할 수 있습니다.단, 방향이 없는 그래프이기 때문에 양방향 모두 연결해주어야 합니다.
74.[Algorithm] 최소 신장 트리(Minimum Spanning Tree)
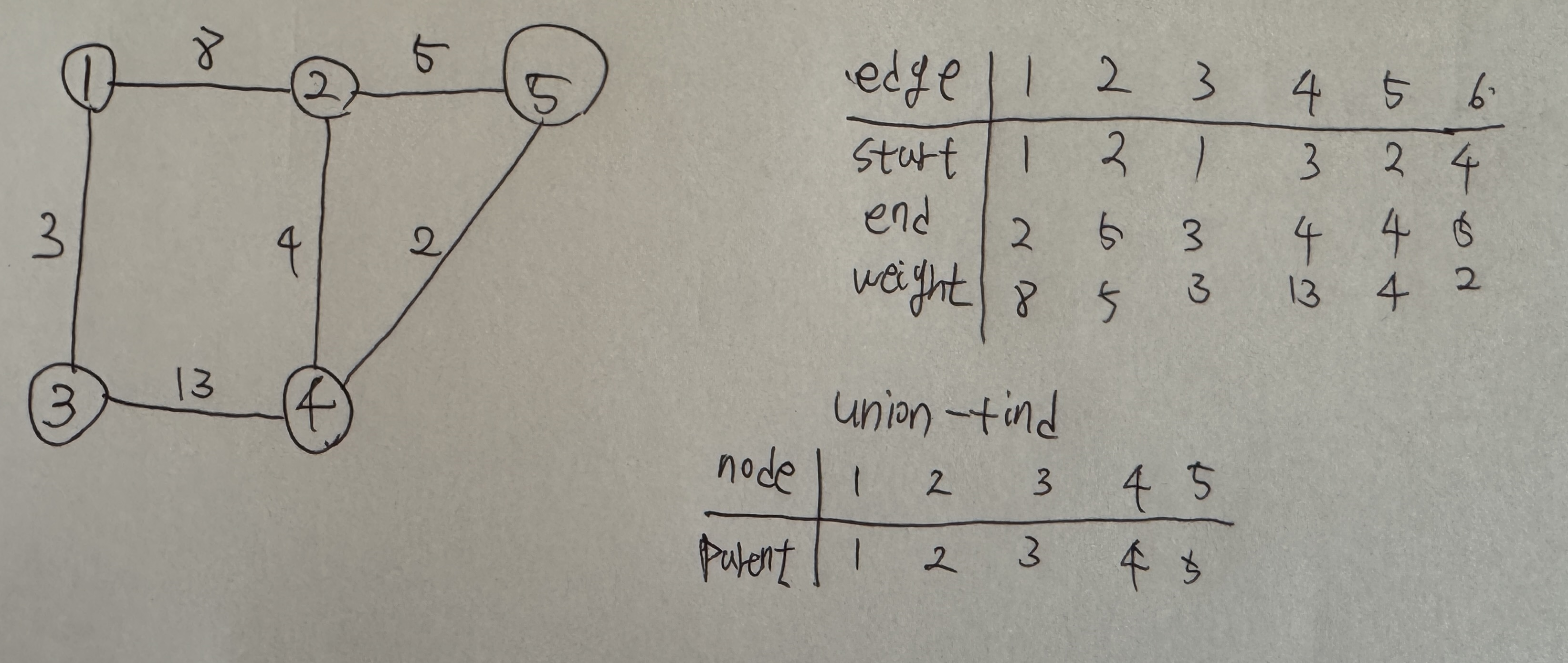
그래프에서 모든 노드를 연결할 때 사용된 간선의 비용을 최소로 하는 트리로 다음과 같은 특징을 가지고 있습니다.사이클이 포함되면 가중치의 합이 최소가 될 수 없으므로 사이클을 포함하지 않는다N개의 노드가 있다면 최소 신장 트리를 구성하는 간선의 수는 항상 N-1개다.가
75.[BOJ/C++] 1197 최소 스패닝 트리
76.[BOJ/C++] 17472 다리 만들기 2
굉장히 어려웠던 문제입니다... 우선 모든 섬의 다리를 최소 비용으로 연결하는 문제로 최소 신장 트리를 이용해 문제를 해결할 수 있습니다.다만 입력으로 간선의 정보를 주는 것이 아닌 섬에 대한 정보를 주기 때문에 간선에 대한 정보를 직접 알아내야합니다.BFS를 이용해
77.[BOJ/C++] 1414 불우이웃돕기
다솜이가 기부할 수 있는 랜선 길이의 최댓값을 구해야합니다.연결되어 있는 모든 랜선을 최소 비용만 남기고 기부할 수 있으므로다솜이가 최대로 기부할 수 있는 랜선의 길이는(모든 랜선의 길이 - 모든 컴퓨터를 연결할 수 있는 랜선의 최소 길이) 입니다
78.[Alogirthm] 트리(Tree)
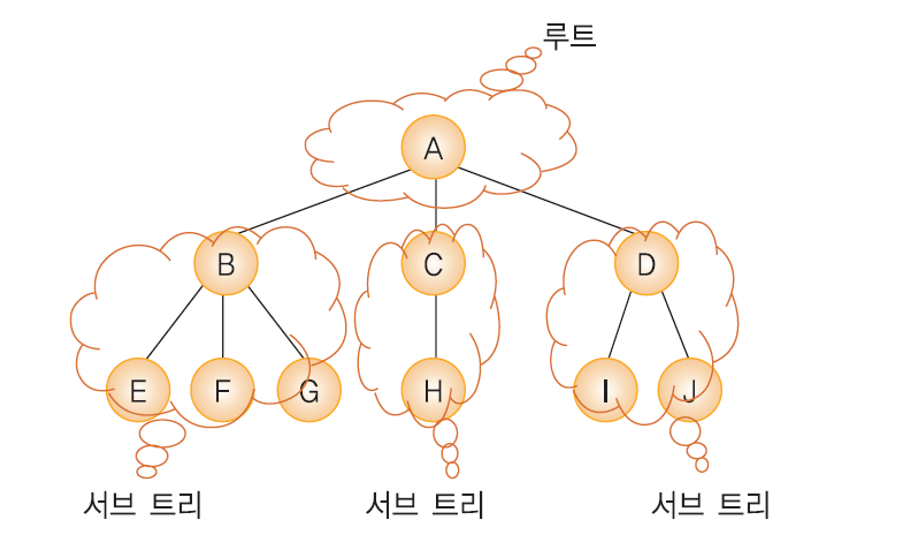
트리는 노드와 간선으로 연결된 그래프의 특수한 형태로 다음과 같은 특징을 가지고 있습니다.순환 구조를 가지고 있지 않으며 1개의 루트 노드가 존재루트 노드를 제외한 노드는 단 1개의 부모 노드를 가집니다트리의 부분 트리 역시 트리의 모든 특징을 가집니다
79.[BOJ/C++] 11725 트리의 부모 찾기
트리의 부모 노드를 구하는 문제로 DFS를 이용하여 문제를 해결할 수 있습니다.진행되는 DFS는 이전 노드에서 넘어왔으므로 이전 노드가 각 노드의 부모 노드가 됩니다.
80.[BOJ/C++] 1068 트리
리프 노드의 개수를 구하는 문제로 DFS를 이용해 문제를 해결할 수 있습니다.모든 노드를 탐색하며 리프 노드가 없으면 결과값 1증가만약 삭제된 노드라면 탐색 중지삭제한 노드가 루트 노드라면 탐색할 수 없으므로 0 출력
81.[Algorithm] 트라이(Trie)
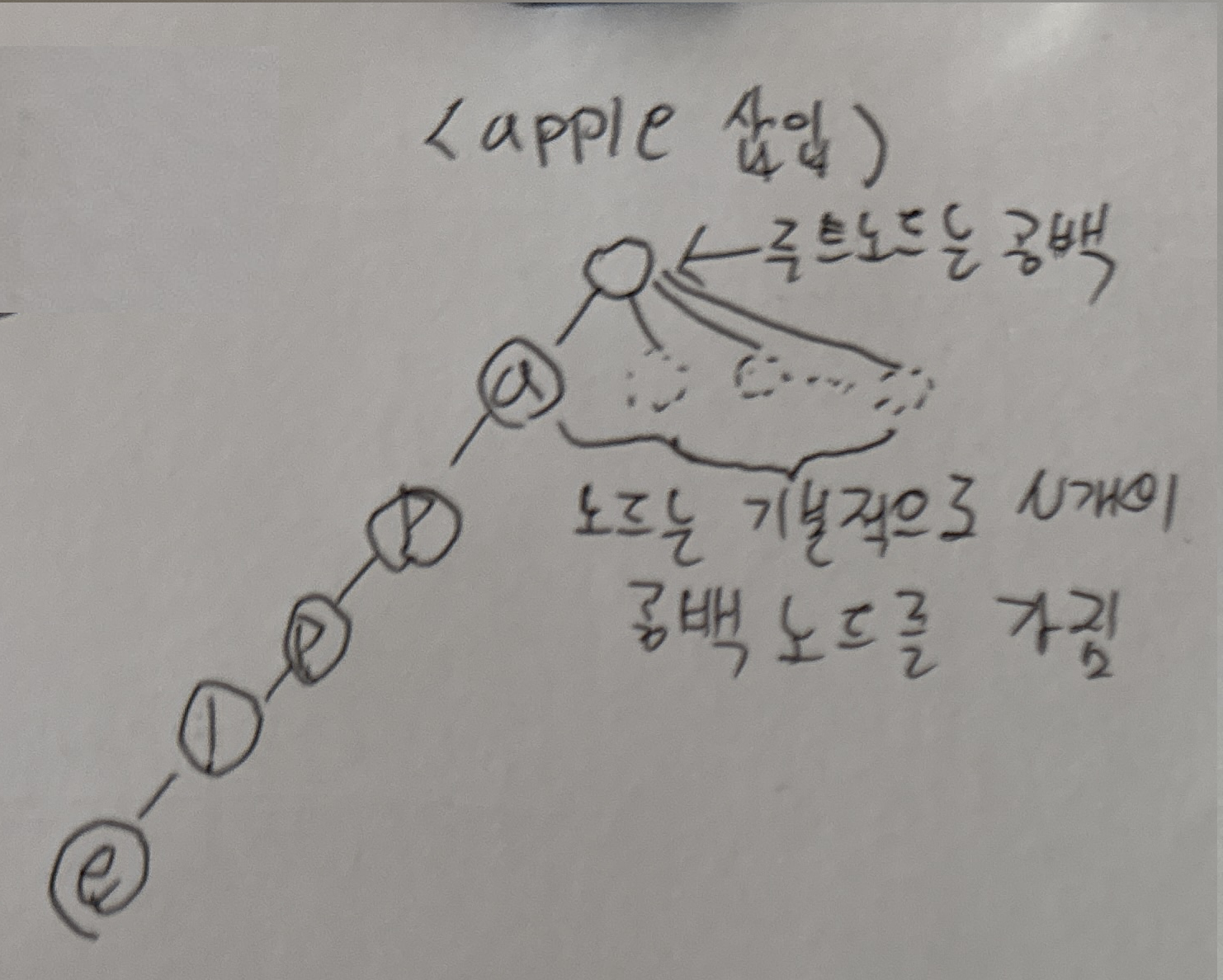
트라이는 문자열 검색을 빠르게 실행할 수 있는 형태를 가진 트리 형태의 자료구조로 다음과 같은 특징을 가지고 있습니다.N진 트리: 문자 종류의 개수에 따라 N이 결정된다. 예를 들어 알파벳은 26개의 문자로 이루어져 있으므로 26진 트리로 구성된다.루트 노드는 항상 빈
82.[BOJ/C++] 14425 문자열 집합
입력받은 문자열이 집합안에 존재하는지 여부를 확인하는 문제로 set과 트라이를 이용해서 문제를 해결할 수 있습니다.set을 이용한 방법과 트라이를 이용한 방법 2가지로 문제를 해결해보겠습니다.해당 문제는 문자열의 부분 탐색이 아니기 때문에 해시 구조를 가지고 있는 un
83.[Algorithm] 이진 트리
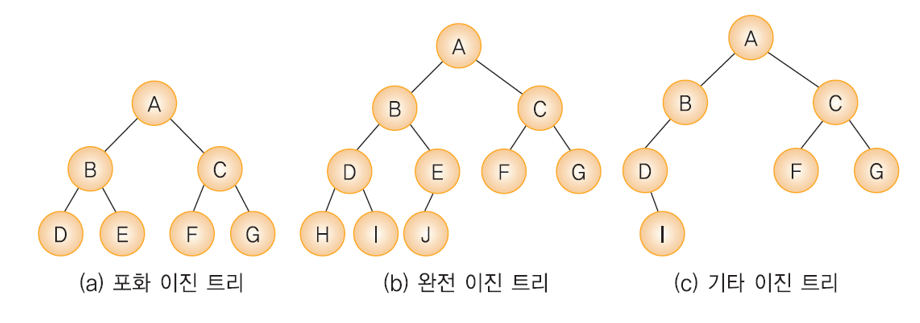
이진 트리는 각 노드의 자식 노드(차수)의 개수가 2 이하로 구성된 트리입니다.포화 이진 트리: 트리의 높이가 모두 일정하며 리프 노드가 꽉 찬 이진 트리완전 이진 트리: 마지막 레벨을 제외하고 완전하게 노드들이 채워져 있고 마지막 레벨은 왼쪽부터 채워진 트리포화 이진
84.[BOJ/C++] 1991 트리 순회
트리를 각각 전위, 중위, 후위 순회 한 결과를 출력하는 문제입니다.
85.[Algorithm] 조합
순열과 조합 순열은 n개 중에 r개를 뽑아 순서를 고려해 나열하는 경우의 수로 $nPr$로 표현됩니다. 조합은 n개 중에 r개를 뽑는 경우의 수로 $nCr$로 표현됩니다. 순열과 조합의 수학적 공식 > $nPr = n! / (n-r)!$ > $nCr = n!
86.[BOJ/C++] 11050 이항 계수 1
가장 기초적인 조합 문제 입니다.이전에는 재귀 함수로 조합 공식의 팩토리얼을 구하는 방법으로 풀었었는데 해당 점화식을 이용해 문제를 해결해보겠습니다.$i$개 중에 $j$개를 뽑는 조합의 점화식은 다음과 같습니다.$Di = Di-1 + Di-1$먼저 DP 테이블을 다음과
87.[BOJ/C++] 11051 이항 계수 2
11050 이항 계수 1 문제와 동일하지만 N이 커진 점과 결과를 10007로 나눈 나머지를 출력하는 것입니다.
88.[BOJ/C++] 2775 부녀회장이 될테야
k층의 n호에 사는 사람의 점화식을 구해 문제를 해결할 수 있습니다.0층의 i호에는 i명의 사람이 살고 있으므로 0층에는 1, 2, 3, 4, ... ,15 명이 각 살고 있습니다.또한 각 층의 1호에는 a층 b호에는 (a-1)(0) ~ (a-1)(b)호의 사람들이 살
89.[BOJ/C++] 1722 순열의 순서
조합론을 이용한 문제로 N이 최대 20! 이므로 long long을사용해야 합니다.순열이 사전 순으로 되어있기 때문에 몇 번째에 어떤 순열이 있는지 유추해볼 수 있습니다.N이 4인 경우로 예시를 들어보겠습니다.1 2 3 41 2 4 31 3 2 41 3 4 21 4 2
90.[BOJ/C++] 1256 사전
아이디어를 떠올리기 힘들었던 문제입니다. 우선 N개의 a와 M개의 z로 만들 수 있는 조합은 (N+M)개 중에 N개 혹은 M개를 뽑는 조합의 경우의 수와 같습니다.예를 들어, 2개의 a와 2개의 z로 만들 수 있는 경우의 수는 4개 중에 2개를 뽑는 것과 같습니다.
91.[BOJ/C++] 1947 선물 전달
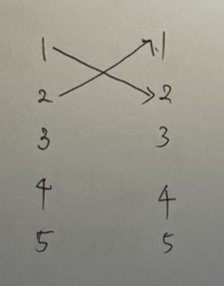
나를 제외한 모두가 선물을 하나씩 받는 경우의 수를 구해봅시다.1, 2번이 서로에게 선물을 전달한 경우1, 2번은 선물 교환이 끝났기 때문에 남은 3명이서 전달하는 경우의 수가 남습니다.1번은 (N-1)명한테 선물을 줄 수 있으니 다음과 같은 점화식을 얻을 수 있습니다
92.[Algorithm] 동적 계획법(Dynamic Programming)
복잡한 문제를 여러 개의 간단한 문제로 분리하여 부분의 문제들을 해결함으로써 최종적으로 복잡한 문제의 답을 구하는 방법큰 문제를 작은 문제로 나눌 수 있어야 한다작은 문제들이 반복되어 나타나고 사용되며 이 작은 문제들의 결괏값은 항상 같아야 한다모든 작은 문제들은 한
93.[BOJ/C++] 1463 1로 만들기
동적 계획법을 이용해 문제를 해결할 수 있습니다.X는 3가지 연산을 할 수 있습니다.3으로 나누어 떨어지는 경우 3으로 나눈다2로 나누어 떨어지는 경우 2로 나눈다1을 뺀다기본적으로 1을 빼는 연산을 한 후 2로 나누어 떨어지는 경우, 3으로 나누어 떨어지는 경우에서
94.[BOJ/C++] 14501 퇴사
아이디어를 떠올리는 것이 어려웠던 문제입니다.동적 계획법을 이용해 문제를 해결할 수 있습니다.$DPi$는 $i$일 까지 얻을 수 있는 최대 수익입니다.특이한 건 거꾸로 N일부터 구해나갑니다.$DPN+1$의 초기값은 0입니다.7일로 예시를 들면 일+시간(7+2) > N+
95.[BOJ/C++] 2193 이친수
동적 계획법을 이용해 문제를 해결할 수 있습니다.우선 각 자릿수에서 이친수의 개수를 알아봅시다.N=11N=21 0N=31 0 01 0 1N=41 0 0 01 0 0 11 0 1 0위의 규칙들을살펴보았을 때 다음과 같은 점화식을 얻을 수 있습니다.$DPN = DPN-1
96.[BOJ/C++] 10844 쉬운 계단 수
동적 계획법으로 문제를 해결할 수 있습니다.$DPi$는 길이 $i$번째 계단수의 마지막 숫자가 $j$인 경우입니다.N번째 계단 수는 N-1번째 계단 수에 영향을 받습니다.만약 N번째 자리가 9라면 N-1번째 자리엔 8만 올 수 있습니다.$DPi = DPi-1$N번째 자
97.[BOJ/C++] 11726 2xn 타일링
동적 계획법을 이용해 문제를 해결할 수 있습니다.N=1 인 경우2x1N=2 인 경우1x2, 1x22x1, 2x1N=3 인 경우2x1, 1x2, 1x21x2, 1x2, 2x12x1, 2x1, 2x1다음과 같은 점화식을 얻을 수 있습니다.$DPN = DPN-1 + DPN-
98.[BOJ/C++] 13398 연속합 2
동적 계획법을 이용해 문제를 해결할 수 있습니다.우선 $DPN$은 0부터 N을 포함하여 연속해서 값을 선택했을 때의 최댓값 입니다.이 때 하나의 값을 삭제하여 최댓값을 만들수도 있습니다.왼쪽에서의 연속된 합 배열 L과 오른쪽에서의 연속된 합 배열 R을 통하여 1개를 제
99.[BOJ/C++] 2851 슈퍼 마리오
누적합을 이용해 문제를 해결할 수 있습니다.합이 100을 넘지 않을 때를 주의해야합니다.
100.[BOJ/C++] 15724 주지수
2차원 배열의 구간 합을 구하는 문제로 $(X1, Y1)$ 에서 $(X2, Y2)$ 까지의 합을 구하는 문제입니다.먼저 숫자 배열로부터 1행, 1열의 구간합을 구합니다.구한 1행 1열의 구간 합으로 $(2,2)$의 구간 합을 구합니다.여기서 구간 합을 구하기 위한 식은
101.[BOJ/C++] 17390 이건 꼭 풀어야 해!
N과 Q가 최대 300,000 이므로 $O(N^2)$ 알고리즘을 사용하면 시간초과가 발생합니다.$O(nlogn)$ 시간 복잡도를 갖는 알고리즘으로 정렬 후 문제를 해결해야 합니다.정렬된 배열을 통해 구간 합 배열을 구합니다.구간 합 배열 $Si$는 $1~i$까지의 합을
102.[BOJ/C++] 20922 겹치는 건 싫어
N이 최대 200,000 이기 때문에 $O(N^2)$의 시간복잡도를 가지는 알고리즘은 사용할 수 없습니다.포인터를 하나씩 움직이며 같은 수가 K개 나왔다면 길이를 저장하고 포인터를 옮깁니다.해당 길이의 최댓값을 구합니다.
103.[Programmers/C++] 퍼즐 게임 챌린지
n이 최대 300,000이기 때문에 $O(N^2)$인 알고리즘은 사용할 수 없습니다.숙련도를 기준으로 이분탐색을 진행합니다.이 때 l=1, r은 퍼즐 문제를 푸는데 걸리는 시간의 최댓값으로 초기화 합니다.퍼즐 문제를 푸는데 걸린 시간의 총 합이 제한 시간보다 작거나 같
104.[Programmers/C++] 광물 캐기
모든 곡괭이에 대한 DFS를 진행하면 $O(3^k)$의 시간이 걸립니다.k는 최대 15이므로 시간은 충분합니다.백트래킹을 이용하여 문제를 해결할 수 있습니다.모든 곡괭이에 대해 DFS를 진행하며 피로도의 최솟값을 갱신합니다.곡괭이가 존재한다면 광물을 5개 연속으로 캐며
105.[BOJ/C++] 22945 팀 빌딩
N이 최대 100,000이기 때문에 $O(N^2)$ 시간복잡도의 알고리즘은 사용할 수 없습니다.정렬을 사용할 수 없고 A와 B의 사이의 개발자 수와 개발 능력이 바뀌어야 하기 때문에 양 끝에서 투 포인터를 이용하여 문제를 해결할 수 있습니다.개발 능력이 더 작은 쪽의
106.[BOJ/C++] 11758 CCW
CCW 공식을 이용하여 $O(1)$의 시간 복잡도가 발생합니다.CCW(Counter-clockwise)는 편명상의 3개의 점과 관련된 점들의 위치 관계를 판단하는 알고리즘 입니다.벡터의 외적을 이용하며 세 점 A(X1, Y1), B(X2, Y2), C(X3, Y3)가
107.[Programmers/C++] K번째 수
C++의 sort 함수를 이용하면 $O(nlogn)$의 시간 복잡도가 발생합니다.배열의 최대 길이가 100이므로 시간 복잡도는 충분합니다.배열의 $i$번째 부터 $j$번째 까지 정렬을 수행합니다.정렬된 구간의 $k$번째 수는 배열의 첫 번째로부터 $i+k$ 번째에 있습
108.[Programmers/C++] 가장 큰 수
시간 복잡도 n번 순회 + 정렬을 사용하므로 $O(n+nlogn)$의 시간 복잡도가 발생합니다. n은 최대 100,000이기 때문에 시간 복잡도는 충분합니다. 문제 접근법 문자열로 바꾼 후 더해진 문자열 값이 크도록 내림차순하여 정렬합니다. 예를 들어 3, 3
109.[BOJ/C++] 2212 센서
정렬 2번, n번 탐색 2번 이므로 $O(nlogn + nlogn + n + n)$ 의 시간복잡도가 발생합니다.N이 최대 10,000 이기 때문에 시간은 충분합니다.만약 2개의 집중국이 있다면 센서들 중 가장 거리차가 큰 1개를 끊어준다면 거리가 최솟값이 됩니다.즉 K
110.[Programmers/C++] 모의고사
N이 최대 10,000 이므로 시간은 충분합니다.각 수포자가 문제를 찍는 1 사이클을 배열로 가지고 있습니다.문제의 정답을 순회하며 각 수포자가 찍은 정답과 비교하여 정답 횟수를 배열에 업데이트 합니다.정답의 최댓값을 구한 후 같은 정답을 가지고 있는 수포자를 정답 배
111.[Programmers/C++] 피로도
던전의 개수가 최대 8이므로 $O(n!)$ 이므로 시간은 충분합니다.들어갈 수 있는 던전에 대한 모든 경우의 수를 구합니다.탐험할 던전의 최소 필요 피로도보다 현재 피로도가 낮으면 탐험하지 않습니다.DFS 수행이 끝난 후 다른 경우에서 탐색할 수 있도록 방문 체크를 해
112.[Programmers/C++] 카펫
노란색 격자가 최대 2,000,000 이고 인수는 $\\sqrt{n}$ 까지 반복하여 구할 수 있습니다.시간 복잡도는 $O(\\sqrt{n})$ 으로 충분합니다.노란색 격자가 들어갈 수 있는 모든 크기, 즉 노란색 격자의 모든 인수를 구합니다.해당 인수는 $n x m$
113.[BOJ/C++] 17281 ⚾
9명의 선수들의 타자 순서에 대한 순열의 경우의 수는 $9!$ 입니다.최대 50이닝 이므로 시간 복잡도는 $O(9! \* n)$ 이므로 충분합니다.9명의 선수들에 대한 모든 순서 조합에 대하여 이닝을 진행합니다.3명이 아웃되었다면 다음 이닝을 진행합니다.각 타자의 결과
114.[BOJ/C++] 21278 호석이 두 마리 치킨
N이 최대 100이므로 $O(N^3)$인 플로이드 워셜 알고리즘을 이용하여 해결할 수 있습니다.플로이드-워셜 알고리즘을 이용하여 모든 건물간의 최단 경로를 구합니다.이중반복문을 이용해 건물을 오름차순으로 순회합니다. (1, 2), (2, 3) ...두 건물중 더 가까운
115.[BOJ/C++] 10815 숫자 카드
N의 크기가 최대 500,000 입니다.정렬과 이분탐색을 이용해 $O(nlogn + logn)$의 시간복잡도로 해결할 수 있습니다.입력받은 숫자를 정렬합니다. 상근이가 가지고 있는지 정렬된 숫자 카드중에 이분탐색으로 찾습니다.
116.[BOJ/C++] 1590 캠프가는 영식
버스의 개수 N이 최대 50, 운행하는 버스의 대수 C가 최대 100이므로$O(N\*C)$의 시간으로 해결할 수 있습니다.버스의 시작 시각을 기준으로 간격마다 탐색을 진행합니다.영식이의 도착시간보다 같거나 큰 버스의 출발 시간이 있다면 업데이트합니다.각 버스의 종류마다
117.[BOJ/C++] 2470 C++
N은 최대 100,000이기 때문에 투 포인터 알고리즘을 사용하면 $O(n)$의 시간 복잡도로 해결할 수 있습니다.용액의 농도를 입력받은 후 정렬합니다.투 포인터를 이용해 두 농도의 합의 절댓값이 최소가 될 때 두 용액의 농도를 업데이트 합니다.
118.[BOJ/C++] 13397 구간 나누기2
N이 최대 5,000 이므로 이분 탐색을 이용해 $O(logn)$의 시간 복잡도로 해결할 수 있습니다.mid를 구간의 최댓값과 최솟값의 차이로 놓고 이분 탐색을 진행합니다.mid가 최소가 되어야 하므로 구간의 최댓값과 최솟값의 차이가 mid보다 크다면 구간을 나눕니다.
119.[BOJ/C++] 9372 상근이의 여행
BFS를 인접 리스트를 이용해 구현하면 시간 복잡도는 $O(V+E)$ 입니다.모든 국가를 방문해야 하기 때문에 BFS를 이용하여 모든 노드를 방문한 숫자를 카운트하여 문제를 해결할 수 있습니다.
120.[BOJ/C++] 4963 섬의 개수
인접 행렬을 이용한 BFS는 $O(V\*E)$의 시간 복잡도가 발생합니다.섬의 상, 하, 좌, 우, 대각선 8방향을 탐색하며 이어져있는 섬을 탐색하는 문제입니다.섬을 인접 행렬로 초기화 한 뒤 모든 좌표에 대해 BFS를 수행합니다.아직 방문하지 않은 섬이 있다면 BFS
121.[BOJ/C++] 2468 안전 영역
N이 최대 100, 높이가 최대 100이기 때문에 $N\*N$ 을 높이만큼 반복하면 최대 1,000,000 입니다.BFS를 인접 행렬로 구현하면 $O(VE)$이고 높이만큼 반복하기 때문에 시간 복잡도는 $O(N^2 h)$ 입니다.장마철에 비가오는 모든 높이에 대해 B
122.[Programmers/C++] 가장 먼 노드
다익스트라 알고리즘을 사용하여 최단 경로를 구하면 $O(ElogV)$의 시간 복잡도가 발생합니다,추가적으로 최단 거리 배열을 순회하며 최대 거리와 동일한 값을 찾아야 하기 때문에 $O(n)$의 시간이 추가로 발생합니다.도착 지점과 가중치로 이루어진 그래프를 인접 행렬로
123.[Programmers/C++] 타겟 넘버
숫자의 개수가 최대 20개 이고 각 숫자가 양수, 음수의 경우의 수를 구해야 하므로 $O(2^20)$ 으로 약 1,000,000 입니다.모든 숫자에 대해 양수, 음수의 경우를 계산하며 합이 타겟과 같은지 DFS를 이용하여 구합니다.모든 숫자에 대해 진행을 했고 타겟과
124.[Programmers/C++] 게임 맵 최단거리
시간 복잡도 BFS를 인접행렬을 이용하여 구현하면 $O(V*E)$의 시간 복잡도가 발생합니다. 문제 접근법 시작 지점을 기준으로 BFS를 수행하며 시작 지점부터 모든 지점까지의 거리를 업데이트 합니다. BFS를 수행 후 $(n, m)$ 까지의 거리가 정답이 됩니
125.[Programmers/C++] 네트워크
시간 복잡도 BFS를 연결리스트를 이용하여 구현하면 시간 복잡도는 $O(ElogV)$ 입니다. 문제 접근법 연결되어 있는 네트워크 그룹의 개수를 구하는 문제입니다. BFS를 이용하면 탐색 과정에서 방문한 모든 노드들은 하나의 네트워크에 속하게 됩니다, 방문하지
126.[Programmers/C++] 단어 변환
시간 복잡도 단어 배열 words에는 최대 50개의 단어가 존재합니다. DFS를 이용해 모든 경우의 수를 구하면 최대 $O(N!)$ 이므로 최대 $50!$이라 시간 초과가 발생할 수 있습니다. BFS를 이용하면 $O(N)$의 시간 복잡도로 문제를 해결할 수 있습니
127.[Programmers/C++] 여행경로
DFS를 이용해 모든 경우의 수를 탐색하므로 최악의 경우 $O(N!)$이 발생할 수 있습니다.N이 최대 10,000 이기 때문에 시간초과가 발생할 수 있어 최적화가 필요합니다.DFS를 이용해 모든 경우의 수를 탐색해도 되지만 최악의 경우 시간 초과가 발생할 수 있습니다
128.[Programmers/C++] 체육복
모든 학생을 탐색하는 방법으로 $O(n)$ 의 시간 복잡도가 발생합니다.학생들의 체육복 개수를 0(체육복 있음)으로 초기화 합니다.체육복을 도난당한 학생은 -1, 여분의 체육복을 가져온 학생은 +1 합니다.이후 학생들의 체육복 개수는 -1(체육복 없음), 0(체육복 있
129.[Programmers/C++] 조이스틱
for문이 최대 N번, while문은 전체적으로 N번 이기 때문에 $O(N)$ 입니다while문이 실행될 때마다 idx가 증가하면서 전체 문자열을 기준으로 한 번씩만 방분합니다.따라서 while문이 여러 번 중첩되어 실행되지 않고 최대 N번만 실행됩니다임의의 문자 $x
130.[Programmers/C++] 큰 수 만들기
스택을 이용하여 $O(N)$ 만큼의 시간이 발생합니다.스택이 비어있다면 숫자를 스택에 삽입합니다.스택이 비어있지 않다면 스택이 비거나 k가 0보다 크고 스택의 top에 있는 숫자가 현재 숫자보다 크거나 같을 때 까지 제거합니다.이후 스택에 현재 숫자를 삽입합니다.위의
131.[Programmers/C++] 구명보트
투 포인터를 이용하므로 $O(N)$의 시간 복잡도가 발생합니다.사람들의 몸무게를 오름차순으로 정렬합니다.가장 무거운 사람부터 구명보트에 태우고 가장 몸무게가 낮은 사람과 함께 탈 수 있는지 확인합니다.함께 탈 수 있다면 무게가 작은 사람도 함께 태웁니다.해당 횟수마다
132.[Programmres/C++] 섬 연결하기
Kruskal의 최소 신장 트리를 이용하여 구현하면 $O(ElogE)$의 시간 복잡도가 발생합니다.최소 신장 트리(MST)를 이용하여 문제를 해결할 수 있습니다.
133.[Programmers/C++] 단속카메라
정렬과 순차 탐색이 필요하므로 $O(NlogN)$의 시간 복잡도가 발생합니다.차들의 진입 시점을 기준으로 정렬합니다.이후 첫 번째 카메라를 첫 번째 차량이 고속도로에서 나가는 시점에 놓았다고 가정하고 다음 차량의 진입 시점에 따라 어떻게 놓을지 결정합니다.위 그림과 같